অধ্যায় ১
হাতে লেখা সংখ্যা চিনতে neural net ব্যবহার করা
Using neural nets to recognize handwritten digits
মানুষের visual system পৃথিবীর অন্যতম এক বিস্ময়। নিচের হাতে লেখা সংখ্যার ধারাটি একবার দেখো:
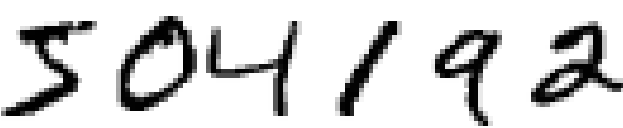
বেশিরভাগ মানুষ অনায়াসেই এই সংখ্যাগুলোকে 504192 হিসেবে চিনে ফেলে। এই সহজভাব কিন্তু আসলে বিভ্রান্তিকর। আমাদের মস্তিষ্কের প্রতিটি গোলার্ধে একটি primary visual cortex আছে — যাকে V1 বলা হয় — যেখানে ১৪ কোটি neuron এবং তাদের মধ্যে কয়েক হাজার কোটি connection রয়েছে। তবু মানুষের দৃষ্টি কেবল V1-তেই সীমাবদ্ধ নয়, বরং একে একে V2, V3, V4, V5 — এই পুরো visual cortex-এর শৃঙ্খল ক্রমশ আরও জটিল image processing করে। আমাদের মাথায় যেন একটা supercomputer বসানো আছে, যাকে কোটি কোটি বছরের evolution ধরে এমনভাবে সাজানো হয়েছে যে সে visual জগৎটাকে চমৎকারভাবে বোঝে। হাতে লেখা সংখ্যা চেনা মোটেই সহজ কাজ নয়; বরং চোখ যা দেখায় তার অর্থ বের করায় আমরা মানুষরা অবিশ্বাস্যরকম দক্ষ। কিন্তু এই কাজের প্রায় পুরোটাই হয় অবচেতনভাবে। তাই আমরা সাধারণত বুঝতেই পারি না আমাদের visual system কত কঠিন একটা সমস্যা সমাধান করছে।
Visual pattern recognition কতটা কঠিন তা স্পষ্ট হয়ে ওঠে যখন তুমি উপরের মতো সংখ্যা চেনার জন্য একটা computer program লিখতে যাও। নিজেরা করলে যা সহজ মনে হয়, সেটা হঠাৎ ভীষণ কঠিন হয়ে দাঁড়ায়। আকৃতি কীভাবে চিনি সে সম্পর্কে সহজ অন্তর্দৃষ্টি — যেমন "9-এর উপরে একটা loop থাকে আর নিচের ডানদিকে একটা খাড়া দাগ" — algorithm আকারে প্রকাশ করা মোটেও সহজ নয়। এমন নিয়মগুলোকে যখন নিখুঁত করতে যাও, তখন ব্যতিক্রম, শর্ত আর বিশেষ ক্ষেত্রের জঙ্গলে হারিয়ে যাও। মনে হয় কাজটা যেন অসম্ভব।
Neural network সমস্যাটিকে একেবারে অন্যভাবে দেখে। মূল ভাবনাটি হলো — বিপুল সংখ্যক হাতে লেখা সংখ্যা নেওয়া হয়, যাদের বলা হয় training example,

তারপর এমন একটা system তৈরি করা হয় যা এই example থেকে শিখতে পারে। অন্যভাবে বললে, neural network এই example-গুলো ব্যবহার করে হাতে লেখা সংখ্যা চেনার নিয়ম নিজে থেকেই বের করে নেয়। তাছাড়া training example-এর সংখ্যা বাড়ালে network হাতের লেখা সম্পর্কে আরও বেশি শিখতে পারে, ফলে এর accuracy বাড়ে। উপরে আমি মাত্র ১০০টি training সংখ্যা দেখিয়েছি, কিন্তু হাজার, এমনকি লক্ষ-কোটি example দিয়ে আমরা হয়তো আরও ভালো একটা handwriting recognizer বানাতে পারতাম।
এই অধ্যায়ে আমরা একটা computer program লিখব যা neural network ব্যবহার করে হাতে লেখা সংখ্যা চিনতে শেখে। Program-টি মাত্র ৭৪ লাইনের, এবং কোনো বিশেষ neural network library ব্যবহার করে না। তবু এই ছোট্ট program মানুষের কোনো হস্তক্ষেপ ছাড়াই ৯৬ শতাংশের বেশি accuracy-তে সংখ্যা চিনতে পারে। পরের অধ্যায়গুলোতে আমরা এমন ধারণা গড়ে তুলব যা accuracy-কে ৯৯ শতাংশের উপরে নিয়ে যেতে পারে। আসলে এখনকার সেরা commercial neural network এতই ভালো যে ব্যাংক cheque process করতে আর post office ঠিকানা চিনতে সেগুলো ব্যবহার করে।
আমরা handwriting recognition-এর উপর জোর দিচ্ছি কারণ neural network সম্পর্কে সাধারণভাবে শেখার জন্য এটি একটি চমৎকার prototype সমস্যা। Prototype হিসেবে এটি ঠিক জায়গায় আঘাত করে — যথেষ্ট চ্যালেঞ্জিং, অথচ এত কঠিন নয় যে খুব জটিল সমাধান বা প্রচুর computational power লাগে। উপরন্তু, এটি deep learning-এর মতো আরও উন্নত কৌশল গড়ে তোলার দারুণ একটা উপায়। তাই পুরো বই জুড়ে আমরা বারবার handwriting recognition-এর কাছে ফিরে আসব। পরে দেখব এই ধারণাগুলো computer vision-এর অন্য সমস্যায়, এবং speech, natural language processing প্রভৃতি ক্ষেত্রেও কীভাবে প্রয়োগ করা যায়।
অবশ্যই, এই অধ্যায়ের উদ্দেশ্য যদি শুধু সংখ্যা চেনার program লেখা হতো, তবে অধ্যায়টা অনেক ছোট হতো! কিন্তু পথ চলতে চলতে আমরা neural network সম্পর্কে অনেক গুরুত্বপূর্ণ ধারণা গড়ে তুলব — দু’ধরনের artificial neuron (perceptron ও sigmoid neuron), এবং neural network-এর জন্য standard learning algorithm যাকে বলে stochastic gradient descent। পুরোটা জুড়ে আমি ব্যাখ্যা করব কেন জিনিসগুলো এভাবে করা হয়, যাতে তোমার neural networks intuition গড়ে ওঠে। শুধু কীভাবে কাজ করে তা দেখানোর চেয়ে এতে আলোচনা একটু দীর্ঘ হয়, কিন্তু যে গভীর বোঝাপড়া তুমি পাবে তার জন্য এটুকু মূল্য দেওয়া সার্থক। অধ্যায়ের শেষে আমরা বুঝতে পারব deep learning আসলে কী, এবং কেন তা গুরুত্বপূর্ণ।
Perceptrons
Neural network জিনিসটা কী? শুরু করতে আমি এক ধরনের artificial neuron-এর কথা বলব যাকে বলে perceptron। ১৯৫০ ও ১৯৬০-এর দশকে বিজ্ঞানী Frank Rosenblatt perceptron তৈরি করেন, যা Warren McCulloch ও Walter Pitts-এর আগের কাজ দ্বারা অনুপ্রাণিত। আজকাল artificial neuron-এর অন্য model ব্যবহার করাই বেশি প্রচলিত — এই বইয়ে এবং neural network নিয়ে আধুনিক অনেক কাজে মূল neuron model হলো sigmoid neuron। Sigmoid neuron নিয়ে আমরা শীঘ্রই আসব। কিন্তু sigmoid neuron কেন এভাবে সংজ্ঞায়িত, তা বোঝার জন্য আগে perceptron বোঝা দরকার।
তাহলে perceptron কীভাবে কাজ করে? একটি perceptron কয়েকটি binary input নেয় এবং একটি মাত্র binary output দেয়:
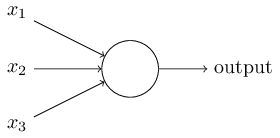
উপরের উদাহরণে perceptron-টির তিনটি input । সাধারণভাবে এর কম-বেশি input থাকতে পারে। Rosenblatt output বের করার একটা সরল নিয়ম প্রস্তাব করেন। তিনি weight নামে কিছু বাস্তব সংখ্যা চালু করেন, যা output-এ সংশ্লিষ্ট input-গুলোর গুরুত্ব প্রকাশ করে। Neuron-এর output, না , তা নির্ধারিত হয় weighted sum একটি threshold মানের চেয়ে কম নাকি বেশি, তার উপর। Weight-এর মতোই threshold একটি বাস্তব সংখ্যা, যা neuron-এর একটি parameter। আরও নিখুঁত algebraic ভাষায়:
Perceptron কীভাবে কাজ করে তার পুরোটা এটুকুই!
এই হলো মূল গাণিতিক model। Perceptron-কে তুমি এমন একটা যন্ত্র হিসেবে ভাবতে পারো যা প্রমাণ ওজন করে সিদ্ধান্ত নেয়। একটা উদাহরণ দিই। উদাহরণটা খুব বাস্তবসম্মত নয়, কিন্তু সহজে বোঝা যায়; আরও বাস্তব উদাহরণে আমরা শীঘ্রই যাব। ধরো সামনে সপ্তাহান্ত আসছে, আর তুমি শুনেছ তোমার শহরে একটা cheese festival হবে। তুমি cheese ভালোবাসো, আর ঠিক করতে চাইছ festival-এ যাবে কিনা। তিনটি বিষয় ওজন করে তুমি হয়তো সিদ্ধান্ত নেবে:
- আবহাওয়া কি ভালো?
- তোমার সঙ্গী কি তোমার সাথে যেতে চায়?
- Festival-টা কি public transit-এর কাছে? (তোমার গাড়ি নেই।)
এই তিনটি বিষয়কে আমরা তিনটি binary variable দিয়ে প্রকাশ করতে পারি। যেমন যদি আবহাওয়া ভালো হয়, আর যদি খারাপ হয়। একইভাবে যদি তোমার সঙ্গী যেতে চায়, নইলে ; আর ও public transit-এর ক্ষেত্রেও তেমনি।
এখন ধরো তুমি cheese এতটাই ভালোবাসো যে সঙ্গী আগ্রহী না হলেও বা festival-এ পৌঁছানো কঠিন হলেও তুমি খুশিমনে যাবে। কিন্তু খারাপ আবহাওয়া তুমি একদম সহ্য করতে পারো না — আবহাওয়া খারাপ হলে কোনোভাবেই যাবে না। এই ধরনের সিদ্ধান্তগ্রহণ perceptron দিয়ে model করা যায়। একটা উপায় হলো আবহাওয়ার জন্য weight , আর অন্য দুটি শর্তের জন্য ও বেছে নেওয়া। -এর বড় মান বোঝায় যে আবহাওয়া তোমার কাছে অনেক বেশি গুরুত্বপূর্ণ — সঙ্গী যাওয়া বা transit কাছে থাকার চেয়েও অনেক বেশি। শেষে ধরো তুমি perceptron-এর জন্য threshold বেছে নিলে । এই পছন্দগুলো দিয়ে perceptron-টি ঠিক কাঙ্ক্ষিত সিদ্ধান্ত-model তৈরি করে: আবহাওয়া ভালো হলেই দেয়, খারাপ হলে । সঙ্গী যেতে চায় কিনা বা transit কাছে কিনা তাতে output-এর কোনো হেরফের হয় না।
Weight ও threshold বদলালে আমরা সিদ্ধান্তগ্রহণের ভিন্ন ভিন্ন model পাই। যেমন ধরো threshold-কে বেছে নিলাম। তখন perceptron সিদ্ধান্ত নেবে যে আবহাওয়া ভালো হলে, অথবা festival public transit-এর কাছে এবং সঙ্গীও যেতে রাজি — এই দুই-ই সত্যি হলে, তোমার festival-এ যাওয়া উচিত। অর্থাৎ এটা ভিন্ন একটা সিদ্ধান্ত-model। Threshold কমানো মানে তুমি festival-এ যেতে আরও বেশি রাজি।
স্পষ্টতই perceptron মানুষের সিদ্ধান্তগ্রহণের সম্পূর্ণ model নয়! কিন্তু উদাহরণটি দেখায় কীভাবে একটা perceptron বিভিন্ন রকম প্রমাণ ওজন করে সিদ্ধান্ত নিতে পারে। আর এটা যুক্তিসঙ্গত মনে হয় যে perceptron-এর একটা জটিল network বেশ সূক্ষ্ম সিদ্ধান্তও নিতে পারে:
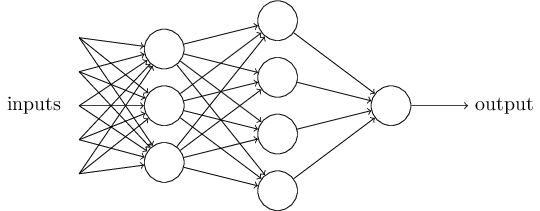
এই network-এ perceptron-গুলোর প্রথম column — যাকে আমরা প্রথম layer বলব — input প্রমাণ ওজন করে তিনটি খুব সরল সিদ্ধান্ত নিচ্ছে। দ্বিতীয় layer-এর perceptron-গুলো কী করছে? তাদের প্রতিটি প্রথম layer-এর সিদ্ধান্তগুলোর ফলাফল ওজন করে সিদ্ধান্ত নিচ্ছে। এভাবে দ্বিতীয় layer-এর একটা perceptron প্রথম layer-এর চেয়ে আরও জটিল ও বিমূর্ত স্তরে সিদ্ধান্ত নিতে পারে। আর তৃতীয় layer-এর perceptron আরও জটিল সিদ্ধান্ত নিতে পারে। এভাবে perceptron-এর একটা বহু-layer network অত্যন্ত সূক্ষ্ম সিদ্ধান্তগ্রহণে অংশ নিতে পারে।
প্রসঙ্গত, perceptron সংজ্ঞায়িত করার সময় বলেছিলাম এর একটি মাত্র output থাকে। উপরের network-এ perceptron-গুলোকে দেখে মনে হচ্ছে তাদের একাধিক output আছে। আসলে তাদের একটিই output। একাধিক output-তীর কেবল একটা সুবিধাজনক উপায়, যা বোঝায় একটা perceptron-এর output আরও কয়েকটি perceptron-এর input হিসেবে ব্যবহৃত হচ্ছে। একটা output line এঁকে তা ভাগ করার চেয়ে এটা কম জটিল।
Perceptron-এর বর্ণনাটা একটু সরল করি। শর্তটি বেশ ভারী, একে সরল করতে দুটি notation-গত পরিবর্তন করতে পারি। প্রথম পরিবর্তন: -কে একটা dot product হিসেবে লেখা, , যেখানে ও হলো vector যাদের component যথাক্রমে weight ও input। দ্বিতীয় পরিবর্তন: threshold-কে অসমতার অন্য পাশে সরিয়ে নেওয়া এবং তাকে perceptron-এর bias দিয়ে প্রতিস্থাপন করা। Threshold-এর বদলে bias ব্যবহার করলে perceptron নিয়ম লেখা যায়:
Bias-কে তুমি এই পরিমাপ হিসেবে ভাবতে পারো যে perceptron থেকে output পাওয়া কতটা সহজ। কিংবা আরও জীববিজ্ঞানসুলভ ভাষায়, bias হলো perceptron-কে fire করানো কতটা সহজ তার পরিমাপ। খুব বড় bias-যুক্ত perceptron-এর পক্ষে output দেওয়া অত্যন্ত সহজ; কিন্তু bias খুব ঋণাত্মক হলে output দেওয়া কঠিন। স্পষ্টতই bias চালু করা perceptron-এর বর্ণনায় ছোট্ট একটা পরিবর্তন, তবে পরে দেখব এটা আরও notation সরল করে দেয়। তাই বইয়ের বাকি অংশে আমরা threshold ব্যবহার করব না, সবসময় bias ব্যবহার করব।
Perceptron-কে আমি প্রমাণ ওজন করে সিদ্ধান্ত নেওয়ার পদ্ধতি হিসেবে বর্ণনা করেছি। Perceptron-এর আরেকটা ব্যবহার হলো computation-এর ভিত্তি বলে আমরা যে মৌলিক logical function-গুলো ভাবি — যেমন AND, OR, NAND — সেগুলো compute করা। যেমন ধরো আমাদের একটা perceptron আছে যার দুটি input, প্রতিটির weight , আর overall bias । এই হলো perceptron-টি:
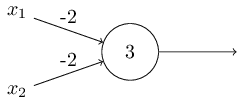
তাহলে দেখি input দিলে output হয় , কারণ ধনাত্মক। এখানে গুণফলগুলো স্পষ্ট করতে আমি চিহ্ন ব্যবহার করেছি। একইরকম হিসাবে দেখা যায় input ও দিলেও output হয়। কিন্তু input দিলে output , কারণ ঋণাত্মক। অর্থাৎ আমাদের perceptron একটা NAND gate বানিয়ে ফেলল!
NAND উদাহরণ দেখায় যে আমরা perceptron দিয়ে সরল logical function compute করতে পারি। আসলে perceptron-এর network দিয়ে আমরা যেকোনো logical function compute করতে পারি। কারণ NAND gate computation-এর জন্য universal — অর্থাৎ যেকোনো computation আমরা NAND gate দিয়ে গড়ে তুলতে পারি। যেমন NAND gate দিয়ে আমরা দুটি bit ও যোগ করার একটা circuit বানাতে পারি। এর জন্য bitwise sum এবং একটা carry bit compute করতে হয়, যেটা ও দুটোই হলে হয় — অর্থাৎ carry bit হলো bitwise product :
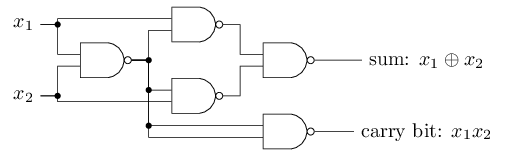
Perceptron-এর সমতুল্য network পেতে আমরা সব NAND gate-কে দুটি input-যুক্ত perceptron দিয়ে প্রতিস্থাপন করি, যাদের প্রতিটি input-এর weight এবং overall bias । এই হলো ফলাফল-network। লক্ষ করো, তীরগুলো আঁকা সহজ করতে নিচের ডানদিকের NAND gate-এর perceptron-টা একটু সরিয়ে দিয়েছি:
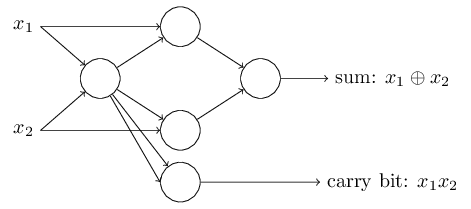
এই perceptron network-এর একটা লক্ষণীয় দিক হলো — সবচেয়ে বাঁয়ের perceptron-এর output সবচেয়ে নিচের perceptron-এ দুইবার input হিসেবে ব্যবহৃত হয়েছে। Perceptron model সংজ্ঞায়িত করার সময় আমি বলিনি একই জায়গায় এমন দ্বিগুণ-output অনুমোদিত কিনা। আসলে এতে খুব একটা যায় আসে না। যদি আমরা এটা অনুমোদন করতে না চাই, তাহলে দুটি weight-এর connection-কে মিলিয়ে একটিমাত্র weight-এর connection বানিয়ে দেওয়া যায়। (এটা স্পষ্ট না মনে হলে থেমে নিজে প্রমাণ করো যে এ দুটো সমতুল্য।) এই পরিবর্তনে network দেখায় এরকম — সব চিহ্নহীন weight , সব bias , আর একটা চিহ্নিত weight:
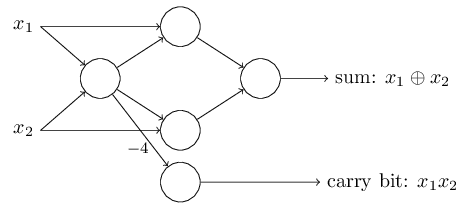
এতক্ষণ আমি ও -এর মতো input-গুলোকে network-এর বাঁ পাশে ভাসমান variable হিসেবে এঁকেছি। আসলে input encode করতে একটা অতিরিক্ত layer — input layer — আঁকাই প্রথা:
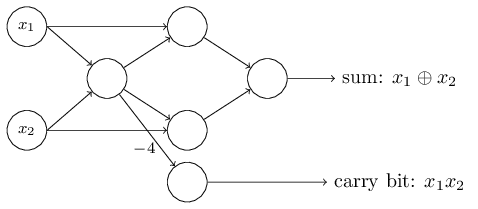
Input perceptron-এর এই notation, যেখানে output আছে কিন্তু input নেই,
— আসলে একটা সংক্ষিপ্ত রূপ। এর মানে এই নয় যে perceptron-টির কোনো input নেই। দেখো: ধরো সত্যিই একটা perceptron আছে যার কোনো input নেই। তখন weighted sum সবসময় শূন্য হবে, ফলে perceptron-টি দেবে যদি , আর দেবে যদি । অর্থাৎ perceptron একটা স্থির মান দেবে, কাঙ্ক্ষিত মান (উপরের উদাহরণে ) নয়। তাই input perceptron-গুলোকে আসলে perceptron না ভেবে এমন বিশেষ unit ভাবা ভালো, যাদের সংজ্ঞাই হলো কাঙ্ক্ষিত মান output দেওয়া।
Adder উদাহরণটি দেখায় কীভাবে perceptron-এর একটা network অনেক NAND gate-যুক্ত একটা circuit-কে অনুকরণ করতে পারে। আর যেহেতু NAND gate computation-এর জন্য universal, তাই perceptron-ও computation-এর জন্য universal।
Perceptron-এর এই computational universality একইসঙ্গে আশ্বস্তকর ও হতাশাজনক। আশ্বস্তকর কারণ এটা বলে যে perceptron-এর network অন্য যেকোনো computing device-এর মতোই শক্তিশালী হতে পারে। কিন্তু হতাশাজনকও, কারণ এতে মনে হয় perceptron যেন কেবল NAND gate-এর একটা নতুন রূপ মাত্র। সে আর এমন কী বড় খবর!
তবে পরিস্থিতি এই দৃষ্টিভঙ্গির চেয়ে ভালো। দেখা যায়, আমরা এমন learning algorithm উদ্ভাবন করতে পারি যা artificial neuron-এর network-এর weight ও bias স্বয়ংক্রিয়ভাবে tune করে। বাইরের উদ্দীপনার প্রতিক্রিয়ায় এই tuning ঘটে, programmer-এর সরাসরি হস্তক্ষেপ ছাড়াই। এই learning algorithm আমাদের artificial neuron-কে প্রচলিত logic gate থেকে সম্পূর্ণ ভিন্নভাবে ব্যবহার করতে দেয়। NAND ও অন্যান্য gate-এর circuit স্পষ্টভাবে সাজানোর বদলে, আমাদের neural network কেবল সমস্যা সমাধান করতে শিখে নিতে পারে — এমন সমস্যাও, যেখানে সরাসরি একটা প্রচলিত circuit design করা অত্যন্ত কঠিন হতো।
Sigmoid neuron
Learning algorithm শুনতে দারুণ। কিন্তু neural network-এর জন্য এমন algorithm আমরা কীভাবে উদ্ভাবন করব? ধরো আমাদের একটা perceptron network আছে যেটা দিয়ে কোনো সমস্যা সমাধান করতে শেখাতে চাই। যেমন network-এর input হতে পারে একটা scan করা হাতে লেখা সংখ্যার raw pixel data। আর আমরা চাই network weight ও bias শিখে নিক যাতে এর output সংখ্যাটিকে সঠিকভাবে classify করে। Learning কীভাবে কাজ করতে পারে দেখতে, ধরো network-এর কোনো একটা weight (বা bias)-এ আমরা সামান্য পরিবর্তন করলাম। আমরা চাই এই সামান্য পরিবর্তন network-এর output-এও কেবল সামান্য একটা পরিবর্তন ঘটাক। একটু পরেই দেখব, এই ধর্মটিই learning-কে সম্ভব করে তোলে। ছবিতে আমরা যা চাই তা এরকম (স্পষ্টতই handwriting recognition করার জন্য এই network খুবই সরল!):
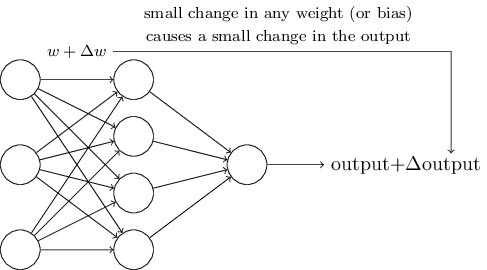
যদি সত্যিই এমন হতো যে weight (বা bias)-এ সামান্য পরিবর্তন output-এ সামান্য পরিবর্তন ঘটায়, তবে এই তথ্য কাজে লাগিয়ে আমরা weight ও bias বদলে network-কে ধীরে ধীরে কাঙ্ক্ষিত আচরণের দিকে নিতে পারতাম। যেমন ধরো network ভুল করে কোনো ছবিকে "8" বলছে, যেটা আসলে "9" হওয়ার কথা। তখন weight ও bias-এ এমন একটা সামান্য পরিবর্তন বের করতে পারতাম যাতে network ছবিটিকে "9" বলার একটু কাছে যায়। এরপর এটা বারবার করতাম, weight ও bias বদলে বদলে আরও ভালো output পেতাম। Network শিখত।
সমস্যা হলো, আমাদের network-এ perceptron থাকলে এমনটা ঘটে না। আসলে network-এর কোনো একটা perceptron-এর weight বা bias-এ সামান্য পরিবর্তন কখনো কখনো ওই perceptron-এর output পুরোপুরি উল্টে দিতে পারে — যেমন থেকে । সেই উল্টে যাওয়া তখন বাকি network-এর আচরণ খুব জটিলভাবে সম্পূর্ণ বদলে দিতে পারে। ফলে তোমার "9" হয়তো এখন ঠিকভাবে classify হচ্ছে, কিন্তু বাকি সব ছবিতে network-এর আচরণ সম্ভবত এমনভাবে বদলে গেছে যা নিয়ন্ত্রণ করা কঠিন। এতে weight ও bias ধীরে ধীরে এমনভাবে বদলানো কঠিন হয়ে যায় যাতে network কাঙ্ক্ষিত আচরণের কাছে আসে। হয়তো এ সমস্যা এড়ানোর কোনো চতুর উপায় আছে, কিন্তু perceptron-এর network-কে শেখানোর উপায়টা সরাসরি স্পষ্ট নয়।
এই সমস্যা আমরা কাটিয়ে উঠতে পারি নতুন এক ধরনের artificial neuron চালু করে, যাকে বলে sigmoid neuron। Sigmoid neuron perceptron-এর মতোই, তবে এমনভাবে পরিবর্তিত যে এদের weight ও bias-এ সামান্য পরিবর্তন output-এ কেবল সামান্য পরিবর্তন ঘটায়। এই গুরুত্বপূর্ণ তথ্যটিই sigmoid neuron-এর network-কে শিখতে দেয়।
ঠিক আছে, sigmoid neuron-টা বর্ণনা করি। Perceptron যেভাবে এঁকেছিলাম, sigmoid neuron-ও সেভাবেই আঁকব:
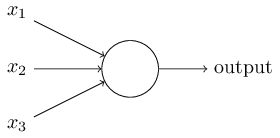
Perceptron-এর মতোই sigmoid neuron-এর input আছে, । কিন্তু এগুলো কেবল বা না হয়ে ও -এর মধ্যবর্তী যেকোনো মানও নিতে পারে। যেমন একটা বৈধ input। আবার perceptron-এর মতোই প্রতিটি input-এর জন্য weight ও একটা overall bias আছে। কিন্তু output বা নয়। বরং তা , যেখানে -কে বলা হয় sigmoid function, এবং যার সংজ্ঞা:
আরও স্পষ্ট করে বললে, input , weight ও bias সহ একটা sigmoid neuron-এর output হলো:
প্রথম দেখায় sigmoid neuron-কে perceptron থেকে খুব আলাদা মনে হয়। Sigmoid function-এর algebraic রূপ অপরিচিত হলে অস্পষ্ট ও ভীতিকর ঠেকতে পারে। আসলে perceptron ও sigmoid neuron-এর মধ্যে অনেক মিল আছে, আর sigmoid function-এর algebraic রূপটা বোঝার পথে সত্যিকারের বাধা না হয়ে বরং একটা technical খুঁটিনাটি মাত্র।
Perceptron model-এর সাথে মিলটা বুঝতে ধরো একটা বড় ধনাত্মক সংখ্যা। তখন , ফলে । অর্থাৎ বড় ও ধনাত্মক হলে sigmoid neuron-এর output প্রায় — ঠিক যেমন perceptron-এর হতো। অন্যদিকে ধরো খুব ঋণাত্মক। তখন , আর । তাই খুব ঋণাত্মক হলেও sigmoid neuron-এর আচরণ perceptron-এর খুব কাছাকাছি। কেবল মাঝারি মাপের হলেই perceptron model থেকে উল্লেখযোগ্য বিচ্যুতি ঘটে।
-এর algebraic রূপ নিয়ে কী বলা যায়? এটা কীভাবে বুঝব? আসলে -এর নিখুঁত রূপ তত গুরুত্বপূর্ণ নয় — যা সত্যিই গুরুত্বপূর্ণ তা হলো function-টা plot করলে কেমন আকৃতি ধারণ করে। এই হলো সেই আকৃতি:
এই আকৃতি আসলে একটা step function-এর মসৃণ রূপ:
যদি সত্যিই একটা step function হতো, তাহলে sigmoid neuron একটা perceptron-ই হতো — কারণ output হতো বা , নির্ভর করত ধনাত্মক না ঋণাত্মক তার উপর।
প্রকৃত function ব্যবহার করে আমরা পাই, আগেই ইঙ্গিত করা মতো, একটা মসৃণ-করা perceptron। আসলে function-এর এই মসৃণতাই গুরুত্বপূর্ণ তথ্য, এর খুঁটিনাটি রূপ নয়। -এর মসৃণতার মানে হলো weight-এ সামান্য পরিবর্তন এবং bias-এ সামান্য পরিবর্তন neuron-এর output-এ একটা সামান্য পরিবর্তন ঘটাবে। আসলে calculus আমাদের বলে -কে ভালোভাবে approximate করা যায় এভাবে:
যেখানে যোগফলটি সব weight -এর উপর, আর ও যথাক্রমে ও -এর সাপেক্ষে output-এর partial derivative বোঝায়। Partial derivative-এ স্বচ্ছন্দ না হলে ভয় পেয়ো না! সব partial derivative নিয়ে উপরের রাশিটা জটিল দেখালেও এটা আসলে খুব সরল একটা কথা বলছে (এবং তা খুব সুখবর): হলো weight ও bias-এর পরিবর্তন ও -এর একটা linear function। এই linearity weight ও bias-এ এমন সামান্য পরিবর্তন বেছে নেওয়া সহজ করে দেয়, যাতে output-এ যেকোনো কাঙ্ক্ষিত সামান্য পরিবর্তন পাওয়া যায়। তাই sigmoid neuron-এর গুণগত আচরণ perceptron-এর অনেকটা মতো হলেও, weight ও bias বদলালে output কীভাবে বদলাবে তা বের করা এদের ক্ষেত্রে অনেক সহজ।
যদি -এর আকৃতিই আসল ব্যাপার হয়, নিখুঁত রূপ নয়, তবে Equation (3)-এ -এর জন্য ওই নির্দিষ্ট রূপটাই কেন ব্যবহার করি? আসলে বইয়ের পরে আমরা মাঝে মাঝে এমন neuron বিবেচনা করব যাদের output , অন্য কোনো activation function -এর জন্য। ভিন্ন activation function ব্যবহার করলে মূলত যা বদলায় তা হলো Equation (5)-এর partial derivative-গুলোর নির্দিষ্ট মান। পরে যখন ওই partial derivative compute করব, তখন দেখা যাবে ব্যবহার করলে algebra সরল হয়ে যায়, কারণ exponential-এর differentiate করার সময় সুন্দর কিছু ধর্ম আছে। যাই হোক, neural net-এর কাজে খুবই প্রচলিত, এবং এই বইয়ে সবচেয়ে বেশি আমরা এই activation function-ই ব্যবহার করব।
Sigmoid neuron-এর output-কে আমরা কীভাবে ব্যাখ্যা করব? স্পষ্টতই perceptron ও sigmoid neuron-এর একটা বড় পার্থক্য হলো — sigmoid neuron কেবল বা output দেয় না। ও -এর মধ্যবর্তী যেকোনো বাস্তব সংখ্যা এদের output হতে পারে, যেমন বা বৈধ output। এটা কাজে লাগতে পারে — যেমন যদি আমরা output-কে network-এ দেওয়া কোনো image-এর pixel-গুলোর গড় তীব্রতা বোঝাতে চাই। কিন্তু কখনো কখনো এটা ঝামেলারও কারণ। ধরো আমরা চাই network-এর output বোঝাক হয় "input image-টা একটা 9", নয়তো "input image-টা 9 নয়"। স্পষ্টতই output বা হলে এটা করা সবচেয়ে সহজ হতো, যেমন perceptron-এ। কিন্তু বাস্তবে আমরা একটা convention ঠিক করে নিতে পারি — যেমন -এর সমান বা বেশি যেকোনো output-কে "9" আর -এর কম যেকোনো output-কে "9 নয়" ধরে নেওয়া। বিভ্রান্তি এড়াতে এমন convention ব্যবহার করলে আমি সবসময় তা স্পষ্ট করে বলব।
Neural network-এর architecture
পরের অংশে আমি এমন একটা neural network পরিচয় করিয়ে দেব যা হাতে লেখা সংখ্যা classify করায় বেশ ভালো কাজ করে। তার প্রস্তুতি হিসেবে network-এর বিভিন্ন অংশের নাম বোঝানো এমন কিছু পরিভাষা ব্যাখ্যা করা দরকার। ধরো আমাদের একটা network আছে:
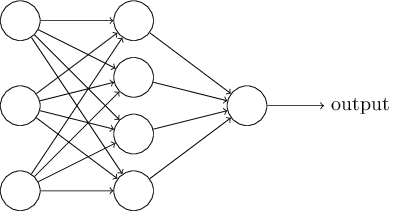
আগেই বলেছি, এই network-এর সবচেয়ে বাঁয়ের layer-কে বলা হয় input layer, আর এর neuron-গুলোকে input neuron। সবচেয়ে ডানের বা output layer-এ থাকে output neuron — এই ক্ষেত্রে একটিমাত্র output neuron। মাঝের layer-কে বলা হয় hidden layer, কারণ এই layer-এর neuron-গুলো input-ও নয়, output-ও নয়। "hidden" শব্দটা হয়তো একটু রহস্যময় শোনায় — প্রথমবার শুনে আমি ভেবেছিলাম এর কোনো গভীর দার্শনিক বা গাণিতিক তাৎপর্য আছে — কিন্তু এর মানে আসলে "input বা output নয়" ছাড়া আর কিছুই নয়। উপরের network-এ একটিমাত্র hidden layer আছে, তবে কিছু network-এ একাধিক hidden layer থাকে। যেমন নিচের চার-layer-এর network-টিতে দুটি hidden layer আছে:
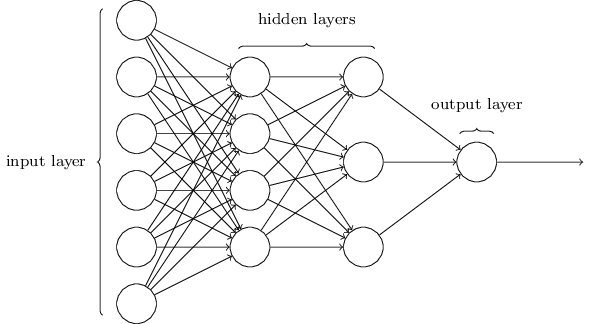
কিছুটা বিভ্রান্তিকরভাবে, এবং ঐতিহাসিক কারণে, এমন বহু-layer network-কে কখনো কখনো multilayer perceptron বা MLP বলা হয় — যদিও এগুলো perceptron নয়, sigmoid neuron দিয়ে তৈরি। আমি এই বইয়ে MLP পরিভাষা ব্যবহার করব না, কারণ এটা বিভ্রান্তিকর মনে হয়, তবে এর অস্তিত্ব সম্পর্কে তোমাকে সতর্ক করে রাখলাম।
Network-এর input ও output layer-এর design প্রায়ই সরল। যেমন ধরো আমরা ঠিক করতে চাই কোনো হাতে লেখা ছবি "9" দেখাচ্ছে কিনা। এর জন্য স্বাভাবিক design হলো ছবির pixel-গুলোর তীব্রতাকে input neuron-এ encode করা। ছবিটা যদি বাই greyscale হয়, তাহলে আমাদের input neuron থাকবে, যেখানে তীব্রতাগুলো ও -এর মধ্যে যথাযথভাবে scale করা। Output layer-এ থাকবে একটিমাত্র neuron, যার মান -এর কম হলে বোঝাবে "input image 9 নয়", আর -এর বেশি হলে "input image একটা 9"।
Network-এর input ও output layer-এর design প্রায়ই সরল হলেও, hidden layer-এর design-এ রীতিমতো শিল্পকলা থাকতে পারে। বিশেষ করে, hidden layer-এর design প্রক্রিয়াকে কয়েকটা সহজ নিয়মে গুটিয়ে ফেলা যায় না। বরং neural network গবেষকরা hidden layer-এর জন্য অনেক design heuristic গড়ে তুলেছেন, যা মানুষকে তাদের net থেকে কাঙ্ক্ষিত আচরণ পেতে সাহায্য করে। যেমন এমন heuristic দিয়ে ঠিক করা যায় কীভাবে hidden layer-এর সংখ্যার সাথে network train করার সময়ের ভারসাম্য রাখা যায়। এমন কয়েকটি design heuristic-এর সাথে আমরা বইয়ের পরে পরিচিত হব।
এতক্ষণ আমরা এমন neural network নিয়ে আলোচনা করছিলাম যেখানে এক layer-এর output পরের layer-এর input হিসেবে ব্যবহৃত হয়। এমন network-কে বলা হয় feedforward neural network। এর মানে network-এ কোনো loop নেই — তথ্য সবসময় সামনের দিকে যায়, কখনো পেছনে ফিরে যায় না। Loop থাকলে আমরা এমন পরিস্থিতিতে পড়তাম যেখানে function-এর input তার নিজের output-এর উপর নির্ভর করত। সেটা বোঝা কঠিন হতো, তাই আমরা এমন loop অনুমোদন করি না।
তবে artificial neural network-এর আরও কিছু model আছে যেখানে feedback loop সম্ভব। এই model-গুলোকে বলা হয় recurrent neural network। এসব model-এর ভাবনা হলো এমন neuron রাখা যারা কিছু সীমিত সময়ের জন্য fire করে, তারপর নিষ্ক্রিয় হয়ে যায়। সেই fire করা অন্য neuron-কে উদ্দীপ্ত করতে পারে, যারা একটু পরে fire করতে পারে, তাও সীমিত সময়ের জন্য। তাতে আরও neuron fire করে, এবং সময়ের সাথে আমরা neuron fire করার একটা ঢেউ পাই। এমন model-এ loop সমস্যা তৈরি করে না, কারণ একটা neuron-এর output তার input-কে কেবল কিছু পরবর্তী সময়ে প্রভাবিত করে, তাৎক্ষণিকভাবে নয়।
Recurrent neural net feedforward network-এর তুলনায় কম প্রভাবশালী হয়েছে, আংশিকভাবে কারণ recurrent net-এর learning algorithm (অন্তত এখন পর্যন্ত) কম শক্তিশালী। তবু recurrent network অত্যন্ত আকর্ষণীয়। আমাদের মস্তিষ্ক কীভাবে কাজ করে তার সাথে এগুলো feedforward network-এর চেয়ে অনেক বেশি কাছাকাছি। আর এমনও হতে পারে যে recurrent network এমন কিছু গুরুত্বপূর্ণ সমস্যা সমাধান করতে পারে যা feedforward network দিয়ে খুব কষ্টে সমাধান করা যায়। তবে পরিধি সীমিত রাখতে এই বইয়ে আমরা বেশি-প্রচলিত feedforward network-এর উপরই মনোযোগ দেব।
হাতে লেখা সংখ্যা classify করার একটি সরল network
Neural network সংজ্ঞায়িত করার পর চলো handwriting recognition-এ ফিরে আসি। হাতে লেখা সংখ্যা চেনার সমস্যাকে আমরা দুটি উপ-সমস্যায় ভাগ করতে পারি। প্রথমত, অনেকগুলো সংখ্যা-যুক্ত একটা ছবিকে আলাদা আলাদা ছবিতে ভাঙার একটা উপায় চাই, যাতে প্রতিটিতে একটা মাত্র সংখ্যা থাকে। যেমন আমরা এই ছবিটাকে
ছয়টি আলাদা ছবিতে ভাঙতে চাই,

আমরা মানুষরা এই segmentation সমস্যা অনায়াসে সমাধান করি, কিন্তু একটা computer program-এর পক্ষে ছবিটিকে সঠিকভাবে ভাঙা চ্যালেঞ্জিং। ছবি ভাগ হয়ে গেলে program-কে এরপর প্রতিটি আলাদা সংখ্যা classify করতে হয়। যেমন আমরা চাই আমাদের program বুঝুক উপরের প্রথম সংখ্যাটি,
একটা 5।
আমরা দ্বিতীয় সমস্যাটি — অর্থাৎ আলাদা সংখ্যা classify করা — সমাধানের program লেখায় মনোযোগ দেব। এর কারণ, একবার আলাদা সংখ্যা classify করার ভালো উপায় পেয়ে গেলে segmentation সমস্যা সমাধান করা তত কঠিন নয়। Segmentation সমস্যা সমাধানের অনেক approach আছে। একটা approach হলো — ছবিটা ভাঙার অনেক ভিন্ন উপায় চেষ্টা করা, এবং প্রতিটি চেষ্টাকে আলাদা-সংখ্যা classifier দিয়ে score দেওয়া। যদি classifier সব segment-এর classification-এ আত্মবিশ্বাসী হয় তবে সেই চেষ্টা উচ্চ score পায়, আর এক বা একাধিক segment-এ classifier সমস্যায় পড়লে নিম্ন score পায়। ভাবনাটা হলো — classifier কোথাও সমস্যায় পড়লে সম্ভবত segmentation ভুলভাবে বেছে নেওয়ার কারণেই পড়ছে। এই ভাবনা ও এর নানা রূপ দিয়ে segmentation সমস্যা ভালোভাবেই সমাধান করা যায়। তাই segmentation নিয়ে চিন্তা না করে আমরা আরও আকর্ষণীয় ও কঠিন সমস্যা — অর্থাৎ আলাদা হাতে লেখা সংখ্যা চেনা — সমাধানের একটা neural network গড়ে তোলায় মন দেব।
আলাদা সংখ্যা চিনতে আমরা একটা তিন-layer-এর neural network ব্যবহার করব:
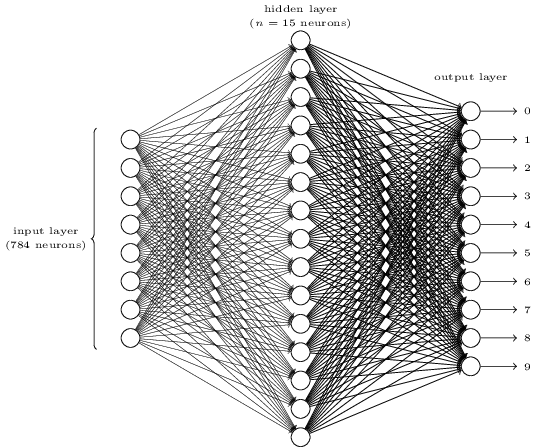
Network-এর input layer-এ থাকে input pixel-গুলোর মান encode করা neuron। পরের অংশে আলোচনা করা মতো, আমাদের training data হবে scan করা হাতে লেখা সংখ্যার অনেক বাই pixel-এর ছবি, তাই input layer-এ neuron থাকবে। সরলতার জন্য উপরের চিত্রে বেশিরভাগ input neuron বাদ দিয়েছি। Input pixel-গুলো greyscale, যেখানে মানে সাদা, মানে কালো, আর মধ্যবর্তী মানগুলো ক্রমশ গাঢ় হতে থাকা ধূসর ছায়া বোঝায়।
Network-এর দ্বিতীয় layer একটা hidden layer। এই hidden layer-এর neuron সংখ্যাকে আমরা দিয়ে বোঝাব, এবং -এর বিভিন্ন মান নিয়ে পরীক্ষা করব। দেখানো উদাহরণে একটা ছোট hidden layer আছে, যেখানে মাত্র টি neuron।
Network-এর output layer-এ থাকে ১০টি neuron। প্রথম neuron যদি fire করে, অর্থাৎ output হয়, তবে তা বোঝাবে network মনে করছে সংখ্যাটি । দ্বিতীয় neuron fire করলে বোঝাবে network মনে করছে সংখ্যাটি । এভাবেই চলবে। আরও নিখুঁত করে বললে, আমরা output neuron-গুলোকে থেকে পর্যন্ত নম্বর দিই, এবং দেখি কোন neuron-এর activation মান সবচেয়ে বেশি। সেই neuron যদি ধরো নম্বর হয়, তবে আমাদের network অনুমান করবে input সংখ্যাটি ছিল । অন্য output neuron-গুলোর ক্ষেত্রেও তেমনি।
তুমি ভাবতে পারো আমরা টি output neuron কেন ব্যবহার করছি। network-এর লক্ষ্য তো আমাদের বলা — input ছবিটি কোন সংখ্যার () সাথে মেলে। এটা করার একটা আপাত-স্বাভাবিক উপায় হলো মাত্র টি output neuron ব্যবহার করা, প্রতিটিকে binary মান হিসেবে ধরে — neuron-এর output -এর কাছে নাকি -এর কাছে তার উপর নির্ভর করে। উত্তর encode করতে টি neuron-ই যথেষ্ট, কারণ যা input সংখ্যার টি সম্ভাব্য মানের চেয়ে বেশি। তাহলে network-এর কেন টি neuron ব্যবহার করা উচিত? এটা কি অদক্ষ নয়? শেষ বিচারে যুক্তিটা empirical: আমরা দুটো design-ই চেষ্টা করতে পারি, এবং দেখা যায় এই নির্দিষ্ট সমস্যার জন্য output neuron-এর network output neuron-এর network-এর চেয়ে ভালোভাবে সংখ্যা চিনতে শেখে। কিন্তু এতে প্রশ্ন থেকে যায় — output neuron কেন ভালো কাজ করে? এমন কোনো heuristic কি আছে যা আগেই বলে দিত যে আমাদের -output নয়, -output encoding ব্যবহার করা উচিত?
কেন এটা করি তা বুঝতে neural network কী করছে তা মূল নীতি থেকে ভাবা সাহায্য করে। প্রথমে output neuron-এর ক্ষেত্রটা বিবেচনা করি। প্রথম output neuron-এ মন দিই — যেটা ঠিক করার চেষ্টা করছে সংখ্যাটা কিনা। সে এটা করে hidden layer-এর neuron থেকে আসা প্রমাণ ওজন করে। ওই hidden neuron-গুলো কী করছে? ধরা যাক, যুক্তির খাতিরে, hidden layer-এর প্রথম neuron সনাক্ত করে নিচের মতো একটা image আছে কিনা:

সে এটা করতে পারে — ছবির সাথে মিলে যাওয়া input pixel-গুলোকে বেশি weight, আর বাকিগুলোকে কম weight দিয়ে। একইভাবে ধরা যাক hidden layer-এর দ্বিতীয়, তৃতীয় ও চতুর্থ neuron সনাক্ত করে নিচের image-গুলো আছে কিনা:

যেমন তুমি হয়তো আঁচ করেছ, এই চারটি image একসাথে মিলে আগে দেখা সংখ্যার ধারায় থাকা image-টি তৈরি করে:

তাই এই চারটি hidden neuron-ই fire করলে আমরা সিদ্ধান্তে আসতে পারি যে সংখ্যাটি । অবশ্যই, কোনো ছবিকে বলার এটাই একমাত্র ধরনের প্রমাণ নয় — আরও অনেকভাবে আমরা বৈধভাবে একটা পেতে পারি (যেমন উপরের image-গুলোর translation বা সামান্য বিকৃতির মাধ্যমে)। তবে অন্তত এই ক্ষেত্রে আমরা নিরাপদে বলতে পারি যে input ছিল একটা ।
Neural network যদি এভাবে কাজ করে, তাহলে আমরা একটা যুক্তিসঙ্গত ব্যাখ্যা দিতে পারি কেন network থেকে -এর বদলে output থাকা ভালো। যদি output থাকত, তবে প্রথম output neuron সংখ্যাটির most significant bit কী তা ঠিক করার চেষ্টা করত। আর ওই most significant bit-কে উপরে দেখানো সরল আকৃতির সাথে সহজে সম্পর্কিত করার কোনো উপায় নেই। এটা কল্পনা করা কঠিন যে সংখ্যাটির উপাদান-আকৃতিগুলো (বলা যাক) output-এর most significant bit-এর সাথে নিবিড়ভাবে সম্পর্কিত হবে।
তবে যা বললাম, এর সবটাই কেবল একটা heuristic। এমন কোনো নিয়ম নেই যে তিন-layer neural network-কে আমি যেভাবে বর্ণনা করেছি — hidden neuron সরল উপাদান-আকৃতি সনাক্ত করছে — ঠিক সেভাবেই কাজ করতে হবে। হয়তো কোনো চতুর learning algorithm weight-এর এমন একটা বিন্যাস খুঁজে পাবে যাতে মাত্র output neuron ব্যবহার করা যায়। তবে heuristic হিসেবে আমার বর্ণিত ভাবনাটা বেশ ভালো কাজ করে, এবং ভালো neural network architecture design করায় তোমার অনেক সময় বাঁচাতে পারে।
Gradient descent দিয়ে শেখা
এখন যেহেতু আমাদের neural network-এর একটা design আছে, এটা কীভাবে সংখ্যা চিনতে শিখবে? প্রথমে আমাদের শেখার জন্য একটা data set দরকার — যাকে বলে training data set। আমরা MNIST data set ব্যবহার করব, যেখানে হাজার হাজার scan করা হাতে লেখা সংখ্যার ছবি ও তাদের সঠিক classification আছে। MNIST নামটা এসেছে এই কারণে যে এটা NIST — যুক্তরাষ্ট্রের National Institute of Standards and Technology — সংগৃহীত দুটি data set-এর একটি modified subset। MNIST থেকে কয়েকটি ছবি:
যেমন দেখতে পাচ্ছ, এই সংখ্যাগুলো আসলে এই অধ্যায়ের শুরুতে চেনার চ্যালেঞ্জ হিসেবে দেখানো সংখ্যাগুলোই। অবশ্যই, network পরীক্ষা করার সময় আমরা এমন ছবি চিনতে বলব যা training set-এ নেই!
MNIST data দুটি অংশে আসে। প্রথম অংশে আছে training data হিসেবে ব্যবহারের জন্য 60,000 ছবি। এগুলো 250 জন মানুষের হাতের লেখার নমুনা scan করা — যাদের অর্ধেক US Census Bureau-র কর্মী, আর অর্ধেক স্কুল-শিক্ষার্থী। ছবিগুলো greyscale এবং 28 বাই 28 pixel। MNIST-এর দ্বিতীয় অংশ হলো test data হিসেবে ব্যবহারের জন্য 10,000 ছবি, এগুলোও 28 বাই 28 greyscale। Network কত ভালোভাবে সংখ্যা চিনতে শিখেছে তা মূল্যায়নে আমরা test data ব্যবহার করব। কর্মক্ষমতার একটা ভালো পরীক্ষা হতে, test data নেওয়া হয়েছে training data-র 250 জন থেকে ভিন্ন আরেক দল 250 জন মানুষের কাছ থেকে (যদিও তারাও Census Bureau কর্মী ও স্কুল-শিক্ষার্থীর মিশ্রণ)। এতে আমরা আস্থা পাই যে আমাদের system এমন মানুষের লেখাও চিনতে পারে যাদের লেখা training-এ দেখেনি।
একটা training input বোঝাতে আমরা notation ব্যবহার করব। প্রতিটি training input -কে একটা -মাত্রিক vector হিসেবে ধরা সুবিধাজনক। Vector-এর প্রতিটি entry ছবির একটা pixel-এর grey মান বোঝায়। সংশ্লিষ্ট কাঙ্ক্ষিত output বোঝাব দিয়ে, যেখানে একটা -মাত্রিক vector। যেমন কোনো training image যদি একটা দেখায়, তবে network থেকে কাঙ্ক্ষিত output । লক্ষ করো এখানে হলো transpose operation, যা একটা row vector-কে সাধারণ (column) vector-এ রূপান্তর করে।
আমরা এমন একটা algorithm চাই যা আমাদের এমন weight ও bias খুঁজে দেয় যাতে সব training input -এর জন্য network-এর output -এর কাছাকাছি হয়। এই লক্ষ্য কতটা পূরণ হচ্ছে তা পরিমাপ করতে আমরা একটা cost function সংজ্ঞায়িত করি:
এখানে বোঝায় network-এর সব weight-এর সমষ্টি, সব bias, মোট training input-এর সংখ্যা, হলো input দিলে network থেকে আসা output-এর vector, আর যোগফলটি সব training input -এর উপর। অবশ্যই output , , ও -এর উপর নির্ভর করে, তবে notation সরল রাখতে আমি এই নির্ভরতা স্পষ্ট করিনি। notation কেবল একটা vector -এর স্বাভাবিক দৈর্ঘ্য বোঝায়। আমরা -কে quadratic cost function বলব; একে কখনো কখনো mean squared error বা MSE-ও বলা হয়। Quadratic cost function-এর রূপ দেখলেই বোঝা যায় অঋণাত্মক, কারণ যোগফলের প্রতিটি পদ অঋণাত্মক। তাছাড়া cost ছোট, অর্থাৎ হয় ঠিক তখনই, যখন সব training input -এর জন্য প্রায় output -এর সমান। তাই আমাদের training algorithm ভালো কাজ করেছে যদি এমন weight ও bias খুঁজে পায় যাতে । বিপরীতে, বড় হলে algorithm তত ভালো করছে না — মানে অনেক input-এর জন্য output -এর কাছে নেই। তাই আমাদের training algorithm-এর লক্ষ্য হবে weight ও bias-এর function হিসেবে cost minimize করা। অর্থাৎ এমন weight ও bias-এর একটা সেট খুঁজে বের করা যা cost-কে যতটা সম্ভব ছোট করে। এটা আমরা করব gradient descent নামের একটা algorithm দিয়ে।
Quadratic cost কেন চালু করলাম? আমরা তো মূলত network কতগুলো ছবি সঠিকভাবে classify করল সেই সংখ্যায় আগ্রহী, তাই না? Quadratic cost-এর মতো একটা proxy পরিমাপ minimize করার বদলে সরাসরি ওই সংখ্যাটাই maximize করার চেষ্টা করি না কেন? সমস্যা হলো — সঠিকভাবে classify হওয়া ছবির সংখ্যা network-এর weight ও bias-এর একটা মসৃণ function নয়। বেশিরভাগ ক্ষেত্রে weight ও bias-এ সামান্য পরিবর্তন সঠিকভাবে classify হওয়া ছবির সংখ্যায় কোনো পরিবর্তনই আনে না। এতে কর্মক্ষমতা বাড়াতে weight ও bias কীভাবে বদলাব তা বের করা কঠিন হয়। Quadratic cost-এর মতো একটা মসৃণ cost function ব্যবহার করলে দেখা যায়, cost-এর উন্নতির জন্য weight ও bias-এ সামান্য পরিবর্তন কীভাবে করতে হবে তা বের করা সহজ। তাই আমরা প্রথমে quadratic cost minimize করায় মন দিই, এবং তার পরেই classification accuracy পরীক্ষা করব।
মসৃণ cost function ব্যবহার করতে চাই — এটা মেনেও তুমি হয়তো ভাবতে পারো Equation (6)-এ ব্যবহৃত quadratic function-ই কেন বেছে নিচ্ছি? এটা কি বেশ ad hoc পছন্দ নয়? অন্য কোনো cost function নিলে কি একেবারে ভিন্ন একটা minimizing weight ও bias-এর সেট পাব? এটা যথার্থ উদ্বেগ, এবং পরে আমরা cost function-এ ফিরে গিয়ে কিছু পরিবর্তন করব। তবে Equation (6)-এর quadratic cost function neural network-এ learning-এর মূল ধারণা বোঝার জন্য চমৎকার কাজ করে, তাই আপাতত আমরা এতেই থাকব।
সংক্ষেপে, neural network train করায় আমাদের লক্ষ্য হলো এমন weight ও bias খুঁজে বের করা যা quadratic cost function minimize করে। এটা একটা সুসংজ্ঞায়িত সমস্যা, কিন্তু এখন যেভাবে উপস্থাপন করেছি তাতে অনেক মনোযোগ-বিক্ষেপকারী গঠন আছে — ও -কে weight ও bias হিসেবে ব্যাখ্যা, function-এর উপস্থিতি, network architecture-এর পছন্দ, MNIST, ইত্যাদি। দেখা যায়, এর বেশিরভাগ গঠন উপেক্ষা করে শুধু minimization-এর দিকটায় মন দিলেই আমরা অনেক কিছু বুঝতে পারি। তাই আপাতত আমরা cost function-এর নির্দিষ্ট রূপ, neural network-এর সাথে সম্পর্ক — এসব ভুলে যাব। বরং কল্পনা করব যে আমাদের কেবল বহু-variable-এর একটা function দেওয়া হয়েছে এবং তা minimize করতে হবে। আমরা gradient descent নামের একটা কৌশল গড়ে তুলব যা এমন minimization সমস্যা সমাধানে কাজে লাগে। তারপর neural network-এর জন্য যে নির্দিষ্ট function minimize করতে চাই তাতে ফিরে আসব।
ঠিক আছে, ধরো আমরা কোনো function minimize করার চেষ্টা করছি। এটা বহু variable -এর যেকোনো বাস্তব-মানের function হতে পারে। লক্ষ করো আমি ও notation-কে দিয়ে বদলেছি, জোর দিতে যে এটা যেকোনো function হতে পারে — আমরা আর বিশেষভাবে neural network-এর প্রসঙ্গে ভাবছি না। minimize করতে সাহায্য হয় যদি -কে কেবল দুটি variable — ও -এর function হিসেবে কল্পনা করি:
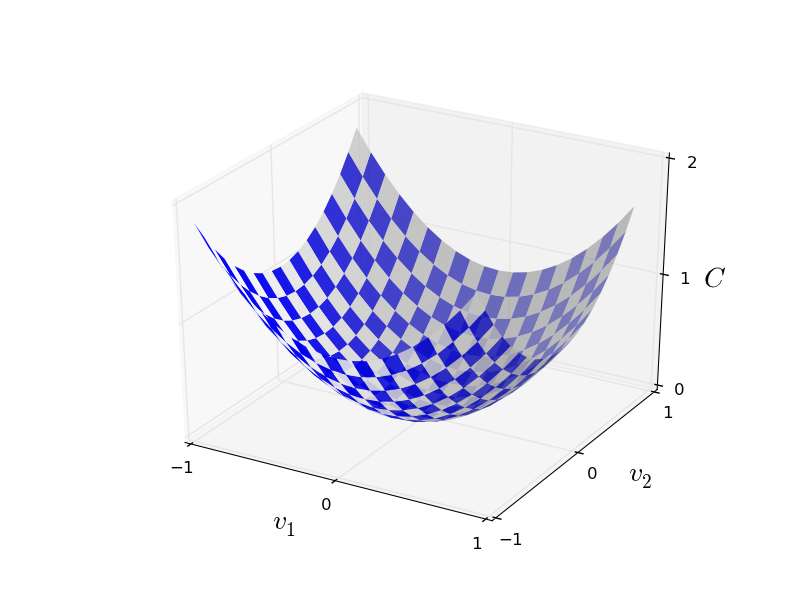
আমরা চাই খুঁজে বের করতে কোথায় তার global minimum-এ পৌঁছায়। অবশ্যই, উপরে plot করা function-এর জন্য আমরা চোখ বুলিয়েই minimum খুঁজে নিতে পারি। সেই অর্থে আমি হয়তো একটু বেশিই সরল একটা function দেখিয়েছি! একটা সাধারণ function বহু variable-এর জটিল function হতে পারে, এবং সাধারণত চোখ বুলিয়ে minimum খুঁজে পাওয়া যাবে না।
সমস্যাটায় আঘাত করার একটা উপায় হলো calculus দিয়ে analytically minimum খোঁজার চেষ্টা করা। আমরা derivative compute করে তা দিয়ে এমন জায়গা খোঁজার চেষ্টা করতে পারি যেখানে extremum। কপাল ভালো থাকলে এটা হয়তো কাজ করবে যখন এক বা কয়েকটা variable-এর function। কিন্তু variable অনেক বেশি হলে এটা দুঃস্বপ্নে পরিণত হবে। আর neural network-এর জন্য আমরা প্রায়ই অনেক বেশি variable চাইব — সবচেয়ে বড় neural network-এর cost function কোটি কোটি weight ও bias-এর উপর অত্যন্ত জটিলভাবে নির্ভর করে। সেটা minimize করতে calculus ব্যবহার করা কাজ করবে না!
ঠিক আছে, তাহলে calculus কাজ করছে না। সৌভাগ্যবশত একটা সুন্দর উপমা আছে যা এমন একটা algorithm-এর ইঙ্গিত দেয় যা বেশ ভালো কাজ করে। আমরা শুরু করি আমাদের function-কে একরকম উপত্যকা ভেবে। উপরের plot-এ একটু চোখ সরু করে তাকালে এটা কঠিন হওয়ার কথা নয়। আর কল্পনা করি একটা বল উপত্যকার ঢাল বেয়ে গড়িয়ে নামছে। আমাদের রোজকার অভিজ্ঞতা বলে বলটি শেষমেশ উপত্যকার তলায় গিয়ে থামবে। হয়তো এই ভাবনাটা function-এর minimum খোঁজার একটা উপায় হিসেবে কাজে লাগাতে পারি? আমরা একটা (কল্পিত) বলের জন্য এলোমেলোভাবে একটা শুরুর বিন্দু বেছে নেব, তারপর বলটি উপত্যকার তলায় গড়িয়ে নামার গতি simulate করব। এই simulation আমরা কেবল -এর derivative (এবং হয়তো কিছু second derivative) compute করেই করতে পারি — ওই derivative-গুলো উপত্যকার স্থানীয় "আকৃতি" সম্পর্কে আমাদের সব দরকারি তথ্য দেবে, ফলে বল কীভাবে গড়াবে তাও।
এ পর্যন্ত যা লিখলাম, তাতে তুমি ভাবতে পারো আমরা বলটির জন্য Newton-এর গতির সমীকরণ লিখতে যাচ্ছি, ঘর্ষণ ও মাধ্যাকর্ষণের প্রভাব বিবেচনা করে, ইত্যাদি। আসলে আমরা বল-গড়ানোর উপমাকে ততটা গুরুত্বে নিচ্ছি না — আমরা minimize করার একটা algorithm উদ্ভাবন করছি, পদার্থবিদ্যার নিয়মের নিখুঁত simulation নয়! বলের দৃষ্টিকোণটা আমাদের কল্পনা উদ্দীপ্ত করতে, চিন্তাকে আটকে রাখতে নয়। তাই পদার্থবিদ্যার সব জটিলতায় না গিয়ে চলো নিজেদের জিজ্ঞেস করি: যদি একদিনের জন্য আমাদের ঈশ্বর ঘোষণা করা হতো, এবং নিজেদের পদার্থবিদ্যার নিয়ম বানিয়ে বলটিকে কীভাবে গড়াতে হবে তা নির্দেশ দিতে পারতাম, তবে কোন নিয়ম বা নিয়মগুলো বেছে নিলে বলটি সবসময় উপত্যকার তলায় গড়িয়ে নামত?
প্রশ্নটা আরও নিখুঁত করতে, ভাবা যাক বলটিকে যদি দিকে সামান্য পরিমাণ এবং দিকে সামান্য পরিমাণ সরাই, তখন কী ঘটে। Calculus বলে এভাবে বদলায়:
আমরা ও এমনভাবে বেছে নেওয়ার উপায় খুঁজব যাতে ঋণাত্মক হয়; অর্থাৎ এমনভাবে বেছে নেব যাতে বল উপত্যকায় গড়িয়ে নামে। এমন পছন্দ কীভাবে করব তা বুঝতে -কে -এর পরিবর্তনের vector হিসেবে সংজ্ঞায়িত করা সাহায্য করে, , যেখানে আবার transpose operation। আমরা -এর gradient-কেও সংজ্ঞায়িত করি partial derivative-গুলোর vector হিসেবে। Gradient vector-কে আমরা দিয়ে বোঝাই, অর্থাৎ:
একটু পরে আমরা -কে ও gradient -এর ভাষায় আবার লিখব। তার আগে একটা বিষয় স্পষ্ট করি যা মাঝে মাঝে gradient নিয়ে মানুষকে আটকে দেয়। প্রথমবার notation দেখে মানুষ ভাবে চিহ্নটা কীভাবে ভাবা উচিত। আসলে -কে একটা একক গাণিতিক বস্তু — উপরে সংজ্ঞায়িত vector — হিসেবে ভাবা একদম ঠিক, যেটা ঘটনাচক্রে দুটি চিহ্ন দিয়ে লেখা। এই দৃষ্টিতে কেবল একটা notation-এর পতাকা, যা বলছে "এই দেখো, একটা gradient vector"। আরও উন্নত দৃষ্টিভঙ্গিও আছে যেখানে -কে নিজস্ব স্বাধীন গাণিতিক সত্তা (যেমন একটা differential operator) হিসেবে দেখা যায়, কিন্তু আমাদের তেমন দৃষ্টিভঙ্গি লাগবে না।
এই সংজ্ঞাগুলো দিয়ে -এর Equation (7)-এর রাশিটি আবার লেখা যায়:
এই সমীকরণ ব্যাখ্যা করে কেন -কে gradient vector বলা হয়: , -এর পরিবর্তনকে -এর পরিবর্তনের সাথে সম্পর্কিত করে — gradient নামের কোনো জিনিস থেকে আমরা ঠিক যা আশা করি। কিন্তু সমীকরণটির সত্যিকারের রোমাঞ্চকর দিক হলো এটা দেখায় কীভাবে বেছে নিলে ঋণাত্মক হয়। বিশেষ করে, ধরো আমরা বেছে নিই
যেখানে একটা ছোট, ধনাত্মক parameter (যাকে বলে learning rate)। তখন Equation (9) বলে । যেহেতু , এটা নিশ্চিত করে , অর্থাৎ Equation (10)-এর নিয়ম মেনে বদলালে সবসময় কমবে, কখনো বাড়বে না (অবশ্যই Equation (9)-এর approximation-এর সীমার মধ্যে)। ঠিক এই ধর্মটাই আমরা চাইছিলাম! তাই আমরা Equation (10)-কে আমাদের gradient descent algorithm-এ বলের "গতির নিয়ম" হিসেবে নেব। অর্থাৎ Equation (10) দিয়ে -এর মান হিসাব করব, তারপর বলের অবস্থান -কে ততটা সরাব:
তারপর এই update নিয়ম আবার ব্যবহার করব, আরেকটা move করতে। এটা বারবার করে গেলে আমরা কমাতে থাকব যতক্ষণ না — আশা করি — একটা global minimum-এ পৌঁছাই।
সংক্ষেপে, gradient descent algorithm যেভাবে কাজ করে তা হলো — বারবার gradient compute করা, তারপর তার বিপরীত দিকে সরে যাওয়া, উপত্যকার ঢাল বেয়ে "নিচে পড়া"। আমরা একে এভাবে কল্পনা করতে পারি:
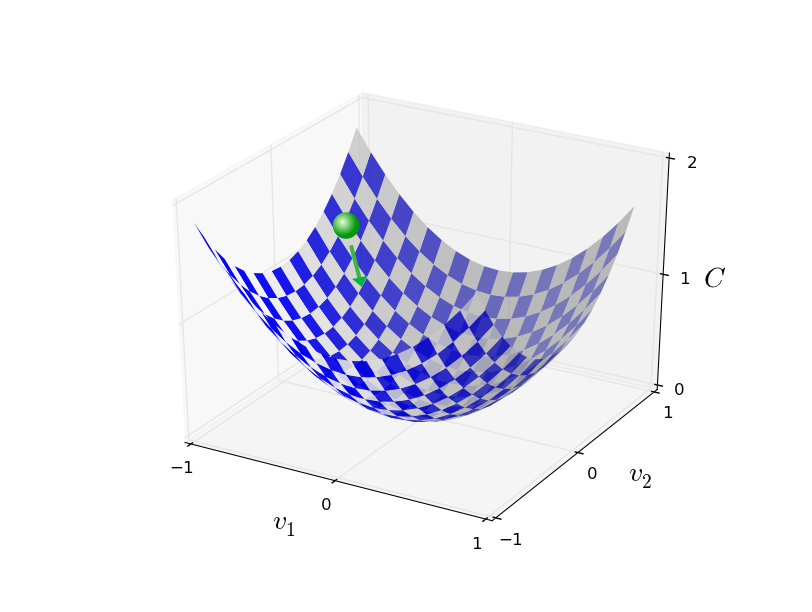
লক্ষ করো এই নিয়মে gradient descent আসল ভৌত গতি অনুকরণ করে না। বাস্তব জীবনে বলের momentum থাকে, আর সেই momentum তাকে ঢাল আড়াআড়ি পার করাতে, এমনকি (ক্ষণিকের জন্য) উপরে গড়াতেও দিতে পারে। কেবল ঘর্ষণের প্রভাব শুরু হলেই বল নিশ্চিতভাবে উপত্যকায় নামে। বিপরীতে, বেছে নেওয়ার আমাদের নিয়ম কেবল বলে "এখনই নিচে নামো"। Minimum খোঁজার জন্য এটাও বেশ ভালো নিয়ম!
Gradient descent ঠিকভাবে কাজ করাতে আমাদের learning rate -কে এত ছোট বেছে নিতে হবে যাতে Equation (9) একটা ভালো approximation থাকে। নইলে আমরা হয়তো পেয়ে বসব, যা স্পষ্টতই ভালো হবে না। একই সময়ে আমরা চাই না খুব ছোট হোক, কারণ তাতে পরিবর্তন খুব ছোট হবে, ফলে gradient descent algorithm খুব ধীরে কাজ করবে। বাস্তব implementation-এ প্রায়ই এমনভাবে পরিবর্তিত হয় যাতে Equation (9) ভালো approximation থাকে অথচ algorithm খুব ধীর না হয়। পরে দেখব এটা কীভাবে কাজ করে।
আমি gradient descent ব্যাখ্যা করলাম যখন মাত্র দুটি variable-এর function। কিন্তু আসলে আরও অনেক variable-এর function হলেও সবকিছু সমানভাবে কাজ করে। বিশেষভাবে ধরো হলো টি variable -এর function। তখন একটা সামান্য পরিবর্তন দ্বারা সৃষ্ট -এর পরিবর্তন হলো
যেখানে gradient হলো vector
দুই-variable-এর ক্ষেত্রের মতোই আমরা বেছে নিতে পারি
এবং আমরা নিশ্চিত যে -এর জন্য আমাদের (approximate) Equation (12) ঋণাত্মক হবে। এটা আমাদের একটা উপায় দেয় বহু variable-এর function হলেও gradient অনুসরণ করে minimum-এ যাওয়ার, এই update নিয়ম বারবার প্রয়োগ করে:
এই update নিয়মকেই তুমি gradient descent algorithm-এর সংজ্ঞা ভাবতে পারো। এটা আমাদের function -এর minimum খুঁজতে অবস্থান বারবার বদলানোর একটা উপায় দেয়। নিয়মটা সবসময় কাজ করে না — কয়েকটা জিনিস ভুল হয়ে gradient descent-কে -এর global minimum খুঁজে পাওয়া থেকে আটকাতে পারে, যা পরের অধ্যায়ে আমরা আবার খতিয়ে দেখব। তবে বাস্তবে gradient descent প্রায়ই অসাধারণ কাজ করে, এবং neural network-এ আমরা দেখব এটা cost function minimize করার একটা শক্তিশালী উপায়, যা net-কে শিখতে সাহায্য করে।
আসলে এমন একটা অর্থও আছে যেখানে gradient descent হলো minimum খোঁজার সর্বোত্তম কৌশল। ধরো আমরা যতটা সম্ভব কমাতে অবস্থানে একটা move করতে চাই। এটা minimize করার সমতুল্য। আমরা move-এর আকার সীমাবদ্ধ রাখব যাতে কোনো ছোট স্থির -এর জন্য । অর্থাৎ আমরা একটা স্থির আকারের ছোট পদক্ষেপ চাই, এবং খুঁজছি কোন দিকে move করলে সবচেয়ে বেশি কমে। প্রমাণ করা যায় যে minimize করা -এর পছন্দ হলো , যেখানে আকার-শর্ত দিয়ে নির্ধারিত। তাই gradient descent-কে এমন একটা উপায় হিসেবে দেখা যায়, যা সেই দিকে ছোট পদক্ষেপ নেয় যেটা তাৎক্ষণিকভাবে -কে সবচেয়ে বেশি কমায়।
Gradient descent কীভাবে neural network-এ learning-এর জন্য প্রয়োগ করব? ভাবনাটা হলো — gradient descent ব্যবহার করে এমন weight ও bias খুঁজে বের করা যা Equation (6)-এর cost minimize করে। এটা কীভাবে কাজ করে দেখতে, gradient descent update নিয়মটি weight ও bias দিয়ে আবার লিখি, variable -এর জায়গায়। অর্থাৎ আমাদের "অবস্থান"-এর এখন component হলো ও , আর gradient vector -এর সংশ্লিষ্ট component হলো ও । Component-এর ভাষায় gradient descent update নিয়ম লিখলে আমরা পাই
এই update নিয়ম বারবার প্রয়োগ করে আমরা "পাহাড় বেয়ে নিচে গড়াতে" পারি, এবং আশা করি cost function-এর একটা minimum খুঁজে পেতে। অন্যভাবে বললে, এটা এমন একটা নিয়ম যা neural network-এ learning-এর জন্য ব্যবহার করা যায়।
Gradient descent নিয়ম প্রয়োগে কিছু চ্যালেঞ্জ আছে। সেগুলো পরের অধ্যায়ে গভীরভাবে দেখব। তবে আপাতত একটা সমস্যার কথা বলতে চাই। সমস্যাটা কী বুঝতে Equation (6)-এর quadratic cost-এর দিকে ফিরে তাকাই। লক্ষ করো এই cost function-এর রূপ , অর্থাৎ এটা প্রতিটি training example-এর জন্য cost -এর গড়। বাস্তবে gradient compute করতে আমাদের প্রতিটি training input -এর জন্য আলাদাভাবে gradient compute করে তারপর গড় করতে হয়, । দুর্ভাগ্যবশত, training input-এর সংখ্যা খুব বেশি হলে এতে অনেক সময় লাগে, ফলে learning ধীর হয়।
Stochastic gradient descent নামের একটা ভাবনা দিয়ে learning দ্রুত করা যায়। ভাবনাটা হলো — এলোমেলোভাবে বেছে নেওয়া অল্প কয়েকটা training input-এর জন্য compute করে gradient estimate করা। এই ছোট নমুনার উপর গড় করে দেখা যায় আমরা দ্রুত প্রকৃত gradient -এর একটা ভালো estimate পেতে পারি, যা gradient descent তথা learning দ্রুত করতে সাহায্য করে।
এই ভাবনাকে আরও নিখুঁত করতে — stochastic gradient descent এলোমেলোভাবে অল্প সংখ্যক টি training input বেছে নিয়ে কাজ করে। ওই এলোমেলো training input-গুলোকে আমরা লেবেল দেব, এবং এদের একটা mini-batch বলব। নমুনার আকার যথেষ্ট বড় হলে আমরা আশা করি -এর গড় মান সব -এর গড়ের প্রায় সমান হবে, অর্থাৎ
যেখানে দ্বিতীয় যোগফলটি পুরো training data-র উপর। পক্ষ বদল করলে আমরা পাই
যা নিশ্চিত করে যে আমরা কেবল এলোমেলোভাবে বেছে নেওয়া mini-batch-এর জন্য gradient compute করেই সামগ্রিক gradient estimate করতে পারি।
একে স্পষ্টভাবে neural network-এ learning-এর সাথে যুক্ত করতে, ধরো ও আমাদের network-এর weight ও bias বোঝায়। তখন stochastic gradient descent এলোমেলোভাবে বেছে নেওয়া একটা mini-batch দিয়ে train করে কাজ করে,
যেখানে যোগফলগুলো বর্তমান mini-batch-এর সব training example -এর উপর। তারপর আমরা আরেকটা এলোমেলো mini-batch বেছে নিয়ে তা দিয়ে train করি। এভাবে চলতে থাকে যতক্ষণ না আমরা সব training input শেষ করি, যাকে বলা হয় একটা training epoch সম্পূর্ণ করা। সেই মুহূর্তে আমরা একটা নতুন training epoch দিয়ে আবার শুরু করি।
প্রসঙ্গত, উল্লেখ করার মতো যে cost function ও weight-bias-এর mini-batch update-এর scaling নিয়ে convention নানারকম হয়। Equation (6)-এ আমরা সামগ্রিক cost function-কে দিয়ে scale করেছি। কেউ কেউ বাদ দিয়ে গড় না করে আলাদা training example-এর cost যোগ করেন। মোট training example-এর সংখ্যা আগে থেকে জানা না থাকলে এটা বিশেষ উপযোগী। যেমন real time-এ আরও training data তৈরি হতে থাকলে এমন হতে পারে। একইভাবে mini-batch update নিয়ম (20) ও (21) কখনো কখনো যোগফলের সামনের পদটি বাদ দেয়। ধারণাগতভাবে এতে খুব একটা পার্থক্য হয় না, কারণ এটা learning rate -কে আবার scale করার সমতুল্য। তবে বিভিন্ন কাজের খুঁটিনাটি তুলনা করার সময় এদিকে নজর রাখা ভালো।
Stochastic gradient descent-কে আমরা রাজনৈতিক জরিপের মতো ভাবতে পারি: পুরো batch-এ gradient descent প্রয়োগ করার চেয়ে একটা ছোট mini-batch নমুনা নেওয়া অনেক সহজ, ঠিক যেমন একটা পূর্ণ নির্বাচন চালানোর চেয়ে একটা জরিপ করা সহজ। যেমন MNIST-এর মতো আকারের training set থাকলে এবং mini-batch আকার (বলা যাক) বেছে নিলে, এর মানে gradient estimate করায় আমরা গুণ দ্রুততা পাব! অবশ্যই estimate-টা নিখুঁত হবে না — statistical ওঠানামা থাকবে — কিন্তু সেটা নিখুঁত হওয়ার দরকারও নেই: আমরা আসলে কেবল এমন একটা সাধারণ দিকে সরতে চাই যা কমাতে সাহায্য করবে, তাই gradient-এর নিখুঁত হিসাব দরকার নেই। বাস্তবে stochastic gradient descent neural network-এ learning-এর একটা বহুল-ব্যবহৃত ও শক্তিশালী কৌশল, এবং এই বইয়ে আমরা যেসব learning কৌশল গড়ে তুলব তার বেশিরভাগের ভিত্তি এটাই।
এই অংশ শেষ করি gradient descent-এ নতুন মানুষদের মাঝে মাঝে যে বিষয়টা খটকা লাগায় তা আলোচনা করে। Neural network-এ cost অবশ্যই বহু variable-এর — সব weight ও bias-এর — function, তাই এক অর্থে এটা একটা অতি-উচ্চ-মাত্রিক জগতে একটা পৃষ্ঠ সংজ্ঞায়িত করে। কেউ কেউ আটকে গিয়ে ভাবে: "আরে, আমাকে তো এই সব অতিরিক্ত মাত্রা কল্পনা করতে পারতে হবে"। আর তারা দুশ্চিন্তা শুরু করে: "আমি তো চার মাত্রায় ভাবতে পারি না, পাঁচ (বা পঞ্চাশ লক্ষ) তো দূরের কথা"। তাদের কি কোনো বিশেষ ক্ষমতার অভাব আছে, যা "আসল" super-গণিতবিদদের আছে? অবশ্যই উত্তর হলো — না। বেশিরভাগ পেশাদার গণিতবিদও চার মাত্রা বিশেষ ভালো কল্পনা করতে পারেন না, পারলেও সামান্যই। তাঁরা যে কৌশল ব্যবহার করেন তা হলো — কী ঘটছে তা প্রকাশের অন্য উপায় গড়ে তোলা। উপরে আমরা ঠিক তা-ই করেছি: -এর একটা algebraic (visual নয়) প্রকাশ ব্যবহার করে বের করেছি কীভাবে সরলে কমে। যারা উচ্চ মাত্রায় ভাবতে দক্ষ, তাঁদের মাথায় এমন নানা কৌশলের একটা ভাণ্ডার থাকে; আমাদের algebraic কৌশল তার একটা উদাহরণ মাত্র। এই কৌশলগুলোতে হয়তো তিন মাত্রা কল্পনার সেই সরলতা নেই, কিন্তু এমন কৌশলের ভাণ্ডার গড়ে তুললে তুমিও উচ্চ মাত্রায় বেশ ভালোভাবে ভাবতে পারবে।
সংখ্যা classify করার network implement করা
চলো এবার একটা program লিখি যা stochastic gradient descent ও MNIST training data ব্যবহার করে হাতে লেখা সংখ্যা চিনতে শেখে। আমরা এটা করব একটা ছোট Python (2.7) program দিয়ে, মাত্র ৭৪ লাইনের code! প্রথমেই আমাদের MNIST data দরকার। তুমি git ব্যবহারকারী হলে এই বইয়ের code repository clone করে data পেতে পারো,
git clone https://github.com/mnielsen/neural-networks-and-deep-learning.gitGit ব্যবহার না করলে data ও code এখান থেকে download করতে পারো।
প্রসঙ্গত, আগে MNIST data বর্ণনা করার সময় বলেছিলাম এটা 60,000 training ছবি ও 10,000 test ছবিতে ভাগ করা। এটাই official MNIST বর্ণনা। আসলে আমরা data-টা একটু ভিন্নভাবে ভাগ করব। Test ছবিগুলো যেমন আছে তেমন রাখব, কিন্তু 60,000-ছবির MNIST training set-কে দুই ভাগে ভাগ করব: 50,000 ছবির একটা সেট, যা দিয়ে আমরা neural network train করব, আর আলাদা 10,000 ছবির একটা validation set। এই অধ্যায়ে আমরা validation data ব্যবহার করব না, তবে বইয়ের পরে এটা neural network-এর কিছু hyper-parameter — যেমন learning rate, যেগুলো আমাদের learning algorithm সরাসরি বেছে নেয় না — কীভাবে ঠিক করব তা বুঝতে কাজে লাগবে। Validation data মূল MNIST specification-এর অংশ না হলেও অনেকে MNIST এভাবে ব্যবহার করেন, এবং neural network-এ validation data ব্যবহার করা সাধারণ। এখন থেকে "MNIST training data" বললে আমি আমাদের 50,000-ছবির data set বোঝাব, মূল 60,000-ছবির set নয়।
MNIST data ছাড়াও আমাদের Numpy নামের একটা Python library দরকার, দ্রুত linear algebra-র জন্য। Numpy install করা না থাকলে এখান থেকে পেতে পারো।
পুরো listing দেওয়ার আগে neural network code-এর মূল বৈশিষ্ট্যগুলো ব্যাখ্যা করি। কেন্দ্রে আছে একটা Network class, যা দিয়ে আমরা একটা neural network উপস্থাপন করি। একটা Network object initialize করতে যে code ব্যবহার করি:
class Network(object):
def __init__(self, sizes):
self.num_layers = len(sizes)
self.sizes = sizes
self.biases = [np.random.randn(y, 1) for y in sizes[1:]]
self.weights = [np.random.randn(y, x)
for x, y in zip(sizes[:-1], sizes[1:])]এই code-এ sizes list-এ থাকে নিজ নিজ layer-এর neuron সংখ্যা। যেমন প্রথম layer-এ 2, দ্বিতীয় layer-এ 3 ও শেষ layer-এ 1 neuron সহ একটা Network object বানাতে চাইলে এই code লিখব:
net = Network([2, 3, 1])Network object-এ bias ও weight-গুলো এলোমেলোভাবে initialize করা হয়, Numpy-র np.random.randn function দিয়ে — যা mean ও standard deviation -এর Gaussian distribution তৈরি করে। এই এলোমেলো initialization আমাদের stochastic gradient descent algorithm-কে একটা শুরুর জায়গা দেয়। পরের অধ্যায়গুলোতে weight ও bias initialize করার আরও ভালো উপায় পাব, তবে আপাতত এটাই চলবে। লক্ষ করো Network initialization code ধরে নেয় প্রথম layer একটা input layer, এবং সেই neuron-গুলোর জন্য কোনো bias সেট করে না, কারণ bias কেবল পরের layer-গুলোর output হিসাবেই ব্যবহৃত হয়।
আরও লক্ষ করো bias ও weight-গুলো Numpy matrix-এর list হিসেবে রাখা। যেমন net.weights[1] একটা Numpy matrix যা neuron-এর দ্বিতীয় ও তৃতীয় layer সংযোগকারী weight রাখে। (এটা প্রথম ও দ্বিতীয় layer নয়, কারণ Python-এর list index থেকে শুরু হয়।) net.weights[1] বেশ লম্বা, তাই এই matrix-কে শুধু দিয়ে বোঝাই। এটা এমন একটা matrix যাতে হলো দ্বিতীয় layer-এর neuron ও তৃতীয় layer-এর neuron-এর সংযোগের weight। ও index-এর এই ক্রম অদ্ভুত লাগতে পারে — নিশ্চয়ই index দুটো অদলবদল করাই বেশি যুক্তিযুক্ত হতো? এই ক্রম ব্যবহারের বড় সুবিধা হলো তৃতীয় layer-এর neuron-গুলোর activation-এর vector দাঁড়ায়:
এই সমীকরণে অনেক কিছু ঘটছে, তাই একে টুকরো টুকরো করে দেখি। হলো দ্বিতীয় layer-এর neuron-গুলোর activation-এর vector। পেতে আমরা -কে weight matrix দিয়ে গুণ করি এবং bias-এর vector যোগ করি। তারপর vector-এর প্রতিটি entry-তে function elementwise প্রয়োগ করি। (একে বলা হয় function-কে vectorize করা।) সহজেই যাচাই করা যায় যে Equation (22) sigmoid neuron-এর output হিসাব করার আগের নিয়ম, Equation (4)-এর মতোই একই ফল দেয়।
এসব মাথায় রেখে একটা Network instance থেকে output হিসাব করার code লেখা সহজ। আমরা শুরু করি sigmoid function সংজ্ঞায়িত করে:
def sigmoid(z):
return 1.0/(1.0+np.exp(-z))লক্ষ করো input z একটা vector বা Numpy array হলে Numpy স্বয়ংক্রিয়ভাবে sigmoid function-কে elementwise, অর্থাৎ vectorized আকারে প্রয়োগ করে।
তারপর আমরা Network class-এ একটা feedforward method যোগ করি, যা একটা input a দিলে সংশ্লিষ্ট output ফেরত দেয়। Method-টি প্রতিটি layer-এ কেবল Equation (22) প্রয়োগ করে:
def feedforward(self, a):
"""Return the output of the network if "a" is input."""
for b, w in zip(self.biases, self.weights):
a = sigmoid(np.dot(w, a)+b)
return aঅবশ্যই, আমরা মূলত চাই আমাদের Network object শিখুক। এ জন্য তাদের একটা SGD method দেব যা stochastic gradient descent implement করে। এই হলো code। কয়েক জায়গায় এটা একটু রহস্যময়, তবে listing-এর পরে আমি তা ভেঙে বুঝিয়ে দেব।
def SGD(self, training_data, epochs, mini_batch_size, eta,
test_data=None):
"""Train the neural network using mini-batch stochastic
gradient descent. The "training_data" is a list of tuples
"(x, y)" representing the training inputs and the desired
outputs. The other non-optional parameters are
self-explanatory. If "test_data" is provided then the
network will be evaluated against the test data after each
epoch, and partial progress printed out. This is useful for
tracking progress, but slows things down substantially."""
if test_data: n_test = len(test_data)
n = len(training_data)
for j in xrange(epochs):
random.shuffle(training_data)
mini_batches = [
training_data[k:k+mini_batch_size]
for k in xrange(0, n, mini_batch_size)]
for mini_batch in mini_batches:
self.update_mini_batch(mini_batch, eta)
if test_data:
print "Epoch {0}: {1} / {2}".format(
j, self.evaluate(test_data), n_test)
else:
print "Epoch {0} complete".format(j)training_data হলো (x, y) tuple-এর একটা list, যা training input ও সংশ্লিষ্ট কাঙ্ক্ষিত output প্রকাশ করে। epochs ও mini_batch_size যা আশা করো তা-ই — কত epoch train করব, এবং নমুনা নেওয়ার সময় mini-batch-এর আকার। eta হলো learning rate । ঐচ্ছিক argument test_data দিলে program প্রতিটি training epoch-এর পরে network মূল্যায়ন করে আংশিক অগ্রগতি print করবে। এটা অগ্রগতি দেখায় কাজে লাগে, তবে অনেকটা ধীর করে দেয়।
Code-টি যেভাবে কাজ করে: প্রতিটি epoch-এ এটা প্রথমে training data এলোমেলোভাবে shuffle করে, তারপর যথাযথ আকারের mini-batch-এ ভাগ করে। Training data থেকে এলোমেলোভাবে নমুনা নেওয়ার এটা একটা সহজ উপায়। তারপর প্রতিটি mini_batch-এ আমরা gradient descent-এর একটা মাত্র পদক্ষেপ প্রয়োগ করি। এটা করে self.update_mini_batch(mini_batch, eta) code, যা কেবল mini_batch-এর training data ব্যবহার করে gradient descent-এর একটা iteration অনুযায়ী network-এর weight ও bias update করে। এই হলো update_mini_batch method-এর code:
def update_mini_batch(self, mini_batch, eta):
"""Update the network's weights and biases by applying
gradient descent using backpropagation to a single mini batch.
The "mini_batch" is a list of tuples "(x, y)", and "eta"
is the learning rate."""
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights]
for x, y in mini_batch:
delta_nabla_b, delta_nabla_w = self.backprop(x, y)
nabla_b = [nb+dnb for nb, dnb in zip(nabla_b, delta_nabla_b)]
nabla_w = [nw+dnw for nw, dnw in zip(nabla_w, delta_nabla_w)]
self.weights = [w-(eta/len(mini_batch))*nw
for w, nw in zip(self.weights, nabla_w)]
self.biases = [b-(eta/len(mini_batch))*nb
for b, nb in zip(self.biases, nabla_b)]বেশিরভাগ কাজ করে এই লাইনটি:
delta_nabla_b, delta_nabla_w = self.backprop(x, y)এটা backpropagation নামের একটা জিনিস ডাকে, যা cost function-এর gradient হিসাব করার একটা দ্রুত উপায়। তাই update_mini_batch কেবল mini_batch-এর প্রতিটি training example-এর জন্য এই gradient-গুলো হিসাব করে, তারপর self.weights ও self.biases যথাযথভাবে update করে কাজ সারে।
self.backprop-এর code এখনই দেখাচ্ছি না। Backpropagation কীভাবে কাজ করে, এর code সহ, আমরা পরের অধ্যায়ে অধ্যয়ন করব। আপাতত ধরে নাও এটা দাবি অনুযায়ী আচরণ করে, training example -এর সাথে যুক্ত cost-এর যথাযথ gradient ফেরত দেয়।
চলো পুরো program-টা দেখি, documentation string সহ, যেগুলো আমি উপরে বাদ দিয়েছিলাম। self.backprop বাদ দিলে program-টি স্বব্যাখ্যাত — সব ভারী কাজ self.SGD ও self.update_mini_batch-এ হয়, যা আমরা আগেই আলোচনা করেছি। self.backprop method gradient হিসাবে সাহায্যের জন্য কয়েকটা অতিরিক্ত function ব্যবহার করে, যেমন sigmoid_prime যা function-এর derivative হিসাব করে, আর self.cost_derivative যা এখানে বর্ণনা করছি না। Program দীর্ঘ মনে হলেও এর বেশিরভাগ code আসলে documentation string, যা code বোঝা সহজ করতে। প্রকৃতপক্ষে program-এ মাত্র ৭৪ লাইন non-whitespace, non-comment code আছে।
"""
network.py
~~~~~~~~~~
A module to implement the stochastic gradient descent learning
algorithm for a feedforward neural network. Gradients are calculated
using backpropagation. Note that I have focused on making the code
simple, easily readable, and easily modifiable. It is not optimized,
and omits many desirable features.
"""
#### Libraries
# Standard library
import random
# Third-party libraries
import numpy as np
class Network(object):
def __init__(self, sizes):
"""The list ``sizes`` contains the number of neurons in the
respective layers of the network. For example, if the list
was [2, 3, 1] then it would be a three-layer network, with the
first layer containing 2 neurons, the second layer 3 neurons,
and the third layer 1 neuron. The biases and weights for the
network are initialized randomly, using a Gaussian
distribution with mean 0, and variance 1. Note that the first
layer is assumed to be an input layer, and by convention we
won't set any biases for those neurons, since biases are only
ever used in computing the outputs from later layers."""
self.num_layers = len(sizes)
self.sizes = sizes
self.biases = [np.random.randn(y, 1) for y in sizes[1:]]
self.weights = [np.random.randn(y, x)
for x, y in zip(sizes[:-1], sizes[1:])]
def feedforward(self, a):
"""Return the output of the network if ``a`` is input."""
for b, w in zip(self.biases, self.weights):
a = sigmoid(np.dot(w, a)+b)
return a
def SGD(self, training_data, epochs, mini_batch_size, eta,
test_data=None):
"""Train the neural network using mini-batch stochastic
gradient descent. The ``training_data`` is a list of tuples
``(x, y)`` representing the training inputs and the desired
outputs. The other non-optional parameters are
self-explanatory. If ``test_data`` is provided then the
network will be evaluated against the test data after each
epoch, and partial progress printed out. This is useful for
tracking progress, but slows things down substantially."""
if test_data: n_test = len(test_data)
n = len(training_data)
for j in xrange(epochs):
random.shuffle(training_data)
mini_batches = [
training_data[k:k+mini_batch_size]
for k in xrange(0, n, mini_batch_size)]
for mini_batch in mini_batches:
self.update_mini_batch(mini_batch, eta)
if test_data:
print "Epoch {0}: {1} / {2}".format(
j, self.evaluate(test_data), n_test)
else:
print "Epoch {0} complete".format(j)
def update_mini_batch(self, mini_batch, eta):
"""Update the network's weights and biases by applying
gradient descent using backpropagation to a single mini batch.
The ``mini_batch`` is a list of tuples ``(x, y)``, and ``eta``
is the learning rate."""
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights]
for x, y in mini_batch:
delta_nabla_b, delta_nabla_w = self.backprop(x, y)
nabla_b = [nb+dnb for nb, dnb in zip(nabla_b, delta_nabla_b)]
nabla_w = [nw+dnw for nw, dnw in zip(nabla_w, delta_nabla_w)]
self.weights = [w-(eta/len(mini_batch))*nw
for w, nw in zip(self.weights, nabla_w)]
self.biases = [b-(eta/len(mini_batch))*nb
for b, nb in zip(self.biases, nabla_b)]
def backprop(self, x, y):
"""Return a tuple ``(nabla_b, nabla_w)`` representing the
gradient for the cost function C_x. ``nabla_b`` and
``nabla_w`` are layer-by-layer lists of numpy arrays, similar
to ``self.biases`` and ``self.weights``."""
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights]
# feedforward
activation = x
activations = [x] # list to store all the activations, layer by layer
zs = [] # list to store all the z vectors, layer by layer
for b, w in zip(self.biases, self.weights):
z = np.dot(w, activation)+b
zs.append(z)
activation = sigmoid(z)
activations.append(activation)
# backward pass
delta = self.cost_derivative(activations[-1], y) * \
sigmoid_prime(zs[-1])
nabla_b[-1] = delta
nabla_w[-1] = np.dot(delta, activations[-2].transpose())
# Note that the variable l in the loop below is used a little
# differently to the notation in Chapter 2 of the book. Here,
# l = 1 means the last layer of neurons, l = 2 is the
# second-last layer, and so on. It's a renumbering of the
# scheme in the book, used here to take advantage of the fact
# that Python can use negative indices in lists.
for l in xrange(2, self.num_layers):
z = zs[-l]
sp = sigmoid_prime(z)
delta = np.dot(self.weights[-l+1].transpose(), delta) * sp
nabla_b[-l] = delta
nabla_w[-l] = np.dot(delta, activations[-l-1].transpose())
return (nabla_b, nabla_w)
def evaluate(self, test_data):
"""Return the number of test inputs for which the neural
network outputs the correct result. Note that the neural
network's output is assumed to be the index of whichever
neuron in the final layer has the highest activation."""
test_results = [(np.argmax(self.feedforward(x)), y)
for (x, y) in test_data]
return sum(int(x == y) for (x, y) in test_results)
def cost_derivative(self, output_activations, y):
"""Return the vector of partial derivatives \partial C_x /
\partial a for the output activations."""
return (output_activations-y)
#### Miscellaneous functions
def sigmoid(z):
"""The sigmoid function."""
return 1.0/(1.0+np.exp(-z))
def sigmoid_prime(z):
"""Derivative of the sigmoid function."""
return sigmoid(z)*(1-sigmoid(z))Program-টি হাতে লেখা সংখ্যা কতটা ভালো চেনে? চলো MNIST data load করে শুরু করি। আমি এটা করব mnist_loader.py নামের একটা ছোট helper program দিয়ে, যা নিচে বর্ণনা করব। একটা Python shell-এ আমরা এই command-গুলো চালাই,
>>> import mnist_loader
>>> training_data, validation_data, test_data = \
... mnist_loader.load_data_wrapper()MNIST data load করার পর আমরা hidden neuron সহ একটা Network সেট আপ করব। উপরে তালিকাভুক্ত Python program — যার নাম network — import করার পর এটা করি,
>>> import network
>>> net = network.Network([784, 30, 10])শেষে, MNIST training_data থেকে epoch ধরে, আকারের mini-batch ও learning rate দিয়ে stochastic gradient descent ব্যবহার করে শিখব,
>>> net.SGD(training_data, 30, 10, 3.0, test_data=test_data)লক্ষ করো, পড়তে পড়তে code চালালে এটা চলতে কিছুটা সময় নেবে — সাধারণ একটা machine-এ (2015 অনুযায়ী) সম্ভবত কয়েক মিনিট লাগবে। আমি পরামর্শ দিই code চালিয়ে দিয়ে পড়া চালিয়ে যাও, আর মাঝে মাঝে output দেখো। তাড়া থাকলে epoch সংখ্যা কমিয়ে, hidden neuron কমিয়ে, বা training data-র অংশবিশেষ ব্যবহার করে গতি বাড়াতে পারো। উৎপাদন-পর্যায়ের code অনেক, অনেক দ্রুত হতো: এই Python script-গুলো neural net কীভাবে কাজ করে তা বোঝাতে, high-performance code হতে নয়! একটা training run-এর output-এর একটা আংশিক transcript এই — যা প্রতিটি training epoch-এর পরে network কতগুলো test ছবি সঠিকভাবে চিনল তা দেখায়। দেখো, মাত্র একটা epoch-এর পরেই এটা 10,000-এর মধ্যে 9,129-এ পৌঁছেছে, এবং সংখ্যা বাড়তেই থাকে,
Epoch 0: 9129 / 10000
Epoch 1: 9295 / 10000
Epoch 2: 9348 / 10000
...
Epoch 27: 9528 / 10000
Epoch 28: 9542 / 10000
Epoch 29: 9534 / 10000অর্থাৎ train-করা network আমাদের প্রায় শতাংশ — শীর্ষে ("Epoch 28") শতাংশ — classification rate দেয়! প্রথম চেষ্টা হিসেবে এটা বেশ উৎসাহজনক। তবে সতর্ক করি, তুমি code চালালে তোমার ফল আমার মতো হুবহু না-ও হতে পারে, কারণ আমরা network-কে (ভিন্ন) এলোমেলো weight ও bias দিয়ে initialize করছি। এই অধ্যায়ের ফল তৈরিতে আমি তিনটি run-এর সেরাটা নিয়েছি।
চলো উপরের পরীক্ষাটা আবার চালাই, hidden neuron সংখ্যা করে। আগের মতোই, পড়তে পড়তে চালালে সতর্ক থেকো এটা চলতে বেশ সময় নেয় (আমার machine-এ প্রতিটি epoch-এ কয়েক দশ সেকেন্ড লাগে), তাই code চলাকালে সমান্তরালে পড়া চালিয়ে যাওয়াই বুদ্ধিমানের কাজ।
>>> net = network.Network([784, 100, 10])
>>> net.SGD(training_data, 30, 10, 3.0, test_data=test_data)ঠিক যেমনটা ভাবা যায়, এতে ফল উন্নত হয়ে শতাংশ হয়। অন্তত এই ক্ষেত্রে, বেশি hidden neuron ব্যবহার আমাদের ভালো ফল পেতে সাহায্য করে।
অবশ্যই, এই accuracy পেতে আমাকে epoch সংখ্যা, mini-batch আকার ও learning rate -এর জন্য নির্দিষ্ট পছন্দ করতে হয়েছে। উপরে বলেছি, এগুলোকে আমাদের network-এর hyper-parameter বলা হয়, learning algorithm-এর শেখা parameter (weight ও bias) থেকে আলাদা করতে। Hyper-parameter খারাপভাবে বাছলে আমরা খারাপ ফল পেতে পারি। ধরো, যেমন, আমরা learning rate বেছে নিলাম ,
>>> net = network.Network([784, 100, 10])
>>> net.SGD(training_data, 30, 10, 0.001, test_data=test_data)ফলাফল অনেক কম উৎসাহজনক,
Epoch 0: 1139 / 10000
Epoch 1: 1136 / 10000
Epoch 2: 1135 / 10000
...
Epoch 27: 2101 / 10000
Epoch 28: 2123 / 10000
Epoch 29: 2142 / 10000তবে দেখা যাচ্ছে network-এর কর্মক্ষমতা সময়ের সাথে ধীরে ধীরে ভালো হচ্ছে। এটা ইঙ্গিত দেয় learning rate বাড়ানোর, ধরো । তা করলে আমরা ভালো ফল পাই, যা আবার learning rate বাড়ানোর ইঙ্গিত দেয়। (কোনো পরিবর্তন উন্নতি ঘটালে, আরও বেশি করে দেখো!) এটা কয়েকবার করলে আমরা শেষমেশ -এর মতো একটা learning rate-এ পৌঁছাব (এবং হয়তো -এ fine tune করব), যা আমাদের আগের পরীক্ষার কাছাকাছি। তাই প্রথমে hyper-parameter-এর খারাপ পছন্দ করলেও, অন্তত আমাদের পছন্দ উন্নত করার মতো যথেষ্ট তথ্য পেয়েছি।
সাধারণভাবে neural network debug করা চ্যালেঞ্জিং হতে পারে। বিশেষ করে যখন hyper-parameter-এর প্রাথমিক পছন্দ এলোমেলো noise-এর চেয়ে ভালো কোনো ফল দেয় না। ধরো আমরা আগের সফল 30 hidden neuron-এর architecture চেষ্টা করি, কিন্তু learning rate বদলে করি:
>>> net = network.Network([784, 30, 10])
>>> net.SGD(training_data, 30, 10, 100.0, test_data=test_data)এই পর্যায়ে আমরা আসলে বাড়াবাড়ি করে ফেলেছি, learning rate খুব বেশি:
Epoch 0: 1009 / 10000
Epoch 1: 1009 / 10000
Epoch 2: 1009 / 10000
Epoch 3: 1009 / 10000
...
Epoch 27: 982 / 10000
Epoch 28: 982 / 10000
Epoch 29: 982 / 10000এখন কল্পনা করো আমরা প্রথমবারের মতো এই সমস্যায় এসেছি। অবশ্যই আমাদের আগের পরীক্ষা থেকে জানা আছে যে সঠিক কাজ হলো learning rate কমানো। কিন্তু প্রথমবার এলে output-এ আমাদের পথ দেখানোর মতো বেশি কিছু থাকত না। আমরা কেবল learning rate নয়, network-এর প্রতিটি দিক নিয়ে দুশ্চিন্তা করতাম। ভাবতাম — weight ও bias কি এমনভাবে initialize করেছি যাতে network-এর শেখা কঠিন? নাকি অর্থপূর্ণ learning-এর জন্য যথেষ্ট training data নেই? হয়তো যথেষ্ট epoch চালাইনি? অথবা হয়তো এই architecture-এর একটা network-এর পক্ষে হাতে লেখা সংখ্যা চিনতে শেখা অসম্ভব? হয়তো learning rate খুব কম? নাকি, হয়তো, learning rate খুব বেশি? প্রথমবার কোনো সমস্যায় এলে তুমি সবসময় নিশ্চিত থাকো না।
এ থেকে শিক্ষা হলো — neural network debug করা সহজ কাজ নয়, এবং সাধারণ programming-এর মতোই এতে একটা শিল্পকলা আছে। ভালো ফল পেতে তোমাকে সেই debugging শিল্পটা শিখতে হবে। আরও সাধারণভাবে, ভালো hyper-parameter ও ভালো architecture বাছার জন্য আমাদের heuristic গড়ে তুলতে হবে। বই জুড়ে আমরা এসব বিস্তারিত আলোচনা করব, এমনকি উপরে আমি কীভাবে hyper-parameter বেছেছি তাও।
আগে MNIST data কীভাবে load হয় তার খুঁটিনাটি এড়িয়ে গিয়েছিলাম। এটা বেশ সরল। সম্পূর্ণতার জন্য এই হলো code। MNIST data রাখতে ব্যবহৃত data structure-গুলো documentation string-এ বর্ণিত — সরল ব্যাপার, Numpy ndarray object-এর tuple ও list (ndarray-এর সাথে পরিচিত না হলে এদের vector ভাবো):
"""
mnist_loader
~~~~~~~~~~~~
A library to load the MNIST image data. For details of the data
structures that are returned, see the doc strings for ``load_data``
and ``load_data_wrapper``. In practice, ``load_data_wrapper`` is the
function usually called by our neural network code.
"""
#### Libraries
# Standard library
import cPickle
import gzip
# Third-party libraries
import numpy as np
def load_data():
"""Return the MNIST data as a tuple containing the training data,
the validation data, and the test data."""
f = gzip.open('../data/mnist.pkl.gz', 'rb')
training_data, validation_data, test_data = cPickle.load(f)
f.close()
return (training_data, validation_data, test_data)
def load_data_wrapper():
"""Return a tuple containing ``(training_data, validation_data,
test_data)``. Based on ``load_data``, but the format is more
convenient for use in our implementation of neural networks."""
tr_d, va_d, te_d = load_data()
training_inputs = [np.reshape(x, (784, 1)) for x in tr_d[0]]
training_results = [vectorized_result(y) for y in tr_d[1]]
training_data = zip(training_inputs, training_results)
validation_inputs = [np.reshape(x, (784, 1)) for x in va_d[0]]
validation_data = zip(validation_inputs, va_d[1])
test_inputs = [np.reshape(x, (784, 1)) for x in te_d[0]]
test_data = zip(test_inputs, te_d[1])
return (training_data, validation_data, test_data)
def vectorized_result(j):
"""Return a 10-dimensional unit vector with a 1.0 in the jth
position and zeroes elsewhere. This is used to convert a digit
(0...9) into a corresponding desired output from the neural
network."""
e = np.zeros((10, 1))
e[j] = 1.0
return eউপরে বলেছি আমাদের program বেশ ভালো ফল পায়। তার মানে কী? কীসের তুলনায় ভালো? কোনটা ভালো করা বোঝে, তা বুঝতে কিছু সরল (non-neural-network) baseline পরীক্ষার সাথে তুলনা করা তথ্যপূর্ণ। সবচেয়ে সরল baseline অবশ্যই হলো এলোমেলোভাবে সংখ্যা অনুমান করা। সেটা প্রায় দশ শতাংশ সময় ঠিক হবে। আমরা তার চেয়ে অনেক ভালো করছি!
একটু কম তুচ্ছ baseline নিয়ে কী বলা যায়? চলো একটা অত্যন্ত সরল ভাবনা চেষ্টা করি: ছবিটা কতটা গাঢ় তা দেখব। যেমন একটা -এর ছবি সাধারণত একটা -এর ছবির চেয়ে বেশ গাঢ় হবে, কারণ বেশি pixel কালো করা থাকে — নিচের উদাহরণগুলো যেমন দেখায়:

এটা ইঙ্গিত দেয় training data ব্যবহার করে প্রতিটি সংখ্যা -এর গড় গাঢ়তা হিসাব করার। নতুন একটা ছবি পেলে আমরা হিসাব করি ছবিটা কতটা গাঢ়, তারপর অনুমান করি এটা সেই সংখ্যা যার গড় গাঢ়তা সবচেয়ে কাছাকাছি। এটা একটা সরল পদ্ধতি, সহজে code করা যায়, তাই code স্পষ্টভাবে লিখছি না — আগ্রহী হলে তা GitHub repository-তে আছে। তবে এটা এলোমেলো অনুমানের চেয়ে অনেক বড় উন্নতি, test ছবির মধ্যে টি সঠিক করে, অর্থাৎ শতাংশ accuracy।
থেকে শতাংশ পরিসরে accuracy দেয় এমন আরও ভাবনা খুঁজে পাওয়া কঠিন নয়। একটু বেশি খাটলে শতাংশের উপরেও যেতে পারো। কিন্তু অনেক বেশি accuracy পেতে প্রতিষ্ঠিত machine learning algorithm ব্যবহার করা সাহায্য করে। চলো সবচেয়ে পরিচিত algorithm-গুলোর একটা ব্যবহার করি, support vector machine বা SVM। SVM-এর সাথে পরিচিত না হলে চিন্তা নেই, আমরা SVM কীভাবে কাজ করে তার খুঁটিনাটি বুঝতে যাব না। বরং scikit-learn নামের একটা Python library ব্যবহার করব, যা LIBSVM নামের একটা দ্রুত C-ভিত্তিক SVM library-র জন্য সরল Python interface দেয়।
Scikit-learn-এর SVM classifier default setting-এ চালালে এটা test ছবির মধ্যে টি সঠিক করে। ছবিটা কতটা গাঢ় তার ভিত্তিতে classify করার আমাদের সরল approach-এর চেয়ে এটা বড় উন্নতি। আসলে এর মানে SVM প্রায় আমাদের neural network-এর মতোই ভালো করছে, সামান্য খারাপ। পরের অধ্যায়গুলোতে আমরা নতুন কৌশল পরিচয় করিয়ে দেব যা আমাদের neural network-কে SVM-এর চেয়ে অনেক ভালো করতে সাহায্য করবে।
তবে গল্প এখানেই শেষ নয়। ফলটি scikit-learn-এর SVM-এর default setting-এর জন্য। SVM-এর কিছু tunable parameter আছে, এবং এই out-of-the-box কর্মক্ষমতা উন্নত করে এমন parameter খোঁজা সম্ভব। আমি স্পষ্টভাবে এই খোঁজ চালাব না, বরং তোমাকে Andreas Mueller-এর একটা blog post-এ পাঠাব আরও জানতে চাইলে। Mueller দেখান যে SVM-এর parameter optimize করায় কিছুটা খাটলে কর্মক্ষমতা শতাংশ accuracy-র উপরে নেওয়া সম্ভব। অন্যভাবে বললে, একটা ভালোভাবে tune করা SVM প্রতি প্রায় 70টি সংখ্যায় মাত্র একটি ভুল করে। বেশ ভালো! Neural network কি আরও ভালো করতে পারে?
আসলে পারে। এই মুহূর্তে, ভালোভাবে design করা neural network MNIST সমাধানের জন্য SVM সহ অন্য প্রতিটি কৌশলকে ছাড়িয়ে যায়। বর্তমান (2013) record হলো ছবির মধ্যে টি সঠিকভাবে classify করা। এটা করেছেন Li Wan, Matthew Zeiler, Sixin Zhang, Yann LeCun ও Rob Fergus। তাঁরা যেসব কৌশল ব্যবহার করেছেন তার বেশিরভাগ আমরা বইয়ের পরে দেখব। ওই স্তরে কর্মক্ষমতা মানুষ-সমতুল্যের কাছাকাছি, এবং তর্কসাপেক্ষে ভালো, কারণ MNIST-এর বেশ কিছু ছবি মানুষের পক্ষেও আত্মবিশ্বাসের সাথে চেনা কঠিন, যেমন:
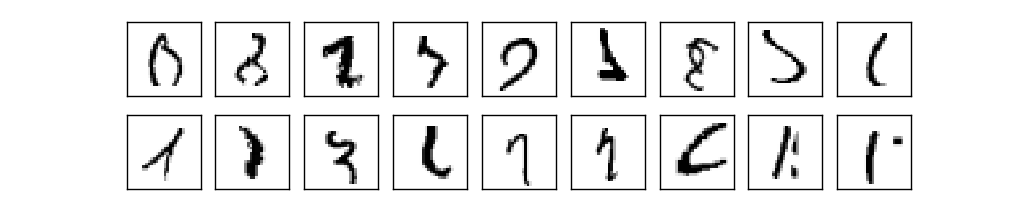
আশা করি তুমি একমত হবে যে এগুলো classify করা কঠিন! MNIST data set-এ এমন ছবি থাকা সত্ত্বেও neural network যে test ছবির মধ্যে কেবল 21টি ছাড়া সব নির্ভুলভাবে classify করতে পারে, তা উল্লেখযোগ্য। সাধারণত programming-এর সময় আমরা মনে করি MNIST সংখ্যা চেনার মতো জটিল সমস্যা সমাধানে একটা পরিশীলিত algorithm দরকার। কিন্তু এইমাত্র উল্লেখ করা Wan et al paper-এর neural network-গুলোও বেশ সরল algorithm — এই অধ্যায়ে দেখা algorithm-এর নানা রূপ। সব জটিলতা training data থেকে স্বয়ংক্রিয়ভাবে শেখা। এক অর্থে, আমাদের ফল এবং আরও পরিশীলিত paper-এর ফল — উভয়ের নৈতিক শিক্ষা হলো কিছু সমস্যার জন্য:
পরিশীলিত algorithm সরল learning algorithm + ভালো training data।
Deep learning-এর দিকে
আমাদের neural network চমৎকার কর্মক্ষমতা দিলেও, সেই কর্মক্ষমতা কিছুটা রহস্যময়। Network-এর weight ও bias স্বয়ংক্রিয়ভাবে আবিষ্কৃত হয়েছে। আর এর মানে network যা করছে তা কীভাবে করছে তার তাৎক্ষণিক কোনো ব্যাখ্যা আমাদের কাছে নেই। আমাদের network কোন নীতিতে হাতে লেখা সংখ্যা classify করছে তা বোঝার কোনো উপায় কি আমরা খুঁজে পাব? আর সেই নীতি পেলে, আমরা কি আরও ভালো করতে পারব?
প্রশ্নগুলো আরও তীক্ষ্ণ করে বলি — ধরো কয়েক দশক পরে neural network artificial intelligence (AI)-এ পৌঁছে দেয়। আমরা কি বুঝব এমন বুদ্ধিমান network কীভাবে কাজ করে? হয়তো network-গুলো আমাদের কাছে অস্বচ্ছ থাকবে, এমন weight ও bias সহ যা আমরা বুঝি না, কারণ সেগুলো স্বয়ংক্রিয়ভাবে শেখা। AI গবেষণার শুরুর দিকে মানুষ আশা করত AI বানানোর প্রচেষ্টা আমাদের বুদ্ধিমত্তার পেছনের নীতি এবং হয়তো মানব মস্তিষ্কের কার্যপ্রণালীও বুঝতে সাহায্য করবে। কিন্তু হয়তো পরিণতি এমন হবে যে আমরা না মস্তিষ্ক বুঝব, না AI কীভাবে কাজ করে তা!
এসব প্রশ্নের জবাব দিতে চলো অধ্যায়ের শুরুতে দেওয়া artificial neuron-এর সেই ব্যাখ্যায় ফিরে যাই — প্রমাণ ওজন করার একটা উপায় হিসেবে। ধরো আমরা ঠিক করতে চাই একটা ছবি মানুষের মুখ দেখাচ্ছে কিনা:


Credits: 1. Ester Inbar. 2. Unknown. 3. NASA, ESA, G. Illingworth, D. Magee, P. Oesch, R. Bouwens, ও HUDF09 Team।
আমরা এই সমস্যায় handwriting recognition-এর মতোই আঘাত করতে পারি — ছবির pixel-গুলোকে একটা neural network-এর input হিসেবে ব্যবহার করে, যেখানে network-এর output একটা মাত্র neuron যা বলে হয় "হ্যাঁ, এটা একটা মুখ", নয়তো "না, এটা মুখ নয়"।
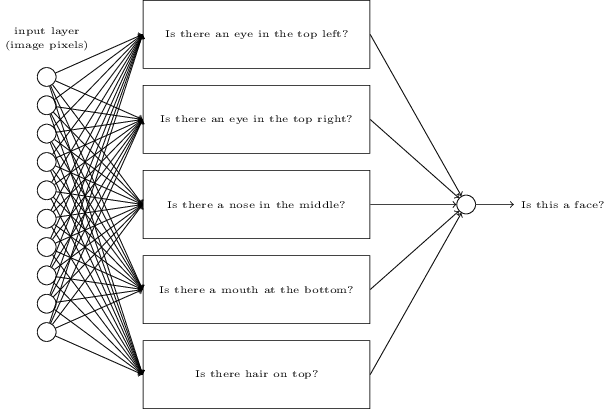
ধরো আমরা এটা করছি, কিন্তু কোনো learning algorithm ব্যবহার করছি না। বরং উপযুক্ত weight ও bias বেছে নিয়ে হাতে network design করার চেষ্টা করছি। কীভাবে এগোব? Neural network আপাতত পুরোপুরি ভুলে গিয়ে একটা heuristic হতে পারে — সমস্যাটিকে উপ-সমস্যায় ভাঙা: ছবির উপরের-বাঁ দিকে কি একটা চোখ আছে? উপরের-ডানে কি একটা চোখ আছে? মাঝখানে কি একটা নাক আছে? নিচের-মাঝে কি একটা মুখ আছে? উপরে কি চুল আছে? এমন আরও।
এই প্রশ্নগুলোর কয়েকটির উত্তর "হ্যাঁ", এমনকি শুধু "সম্ভবত হ্যাঁ" হলেও, আমরা সিদ্ধান্তে আসতাম যে ছবিটা সম্ভবত একটা মুখ। বিপরীতে, বেশিরভাগ প্রশ্নের উত্তর "না" হলে ছবিটা সম্ভবত মুখ নয়।
অবশ্যই এটা কেবল একটা স্থূল heuristic, এবং এর অনেক ত্রুটি আছে। হয়তো মানুষটা টাক, তাই চুল নেই। হয়তো আমরা মুখের একটা অংশই দেখছি, বা মুখটা কাত হয়ে আছে, তাই কিছু বৈশিষ্ট্য আড়াল। তবু heuristic-টা ইঙ্গিত দেয় যে আমরা যদি উপ-সমস্যাগুলো neural network দিয়ে সমাধান করতে পারি, তাহলে হয়তো উপ-সমস্যার network-গুলো মিলিয়ে face-detection-এর একটা network বানাতে পারি। এই হলো একটা সম্ভাব্য architecture, যেখানে আয়তক্ষেত্রগুলো উপ-network বোঝায়। লক্ষ করো এটা face-detection সমস্যার বাস্তবসম্মত সমাধান হিসেবে নয়, বরং network কীভাবে কাজ করে সে সম্পর্কে intuition গড়তে। এই হলো architecture:
এটাও যুক্তিসঙ্গত যে উপ-network-গুলোকেও আরও ভাঙা যায়। ধরো আমরা ভাবছি: "উপরের-বাঁয়ে কি একটা চোখ আছে?" একে এমন প্রশ্নে ভাঙা যায়: "একটা ভ্রু কি আছে?"; "চোখের পাপড়ি আছে কি?"; "একটা iris আছে কি?"; এমন আরও। অবশ্যই এই প্রশ্নগুলোতে আসলে অবস্থানগত তথ্যও থাকা উচিত — "ভ্রুটা কি উপরের-বাঁয়ে এবং iris-এর উপরে?", সেরকম কিছু — তবে চলো সরল রাখি। "উপরের-বাঁয়ে কি একটা চোখ আছে?" প্রশ্নের উত্তর দেওয়া network-কে এখন এভাবে ভাঙা যায়:
ওই প্রশ্নগুলোও আরও ভাঙা যায়, একাধিক layer ধরে আরও আরও গভীরে। শেষমেশ আমরা এমন উপ-network নিয়ে কাজ করব যারা এত সরল প্রশ্নের উত্তর দেয় যা একক pixel-এর স্তরে সহজেই দেওয়া যায়। ওই প্রশ্নগুলো হতে পারে, যেমন, ছবির নির্দিষ্ট বিন্দুতে খুব সরল কোনো আকৃতির উপস্থিতি বা অনুপস্থিতি নিয়ে। এমন প্রশ্নের উত্তর দিতে পারে ছবির raw pixel-এর সাথে যুক্ত একক neuron।
শেষ ফল হলো এমন একটা network যা একটা খুব জটিল প্রশ্ন — এই ছবিটা কি মুখ দেখাচ্ছে কিনা — কে একক pixel-এর স্তরে উত্তরযোগ্য খুব সরল প্রশ্নে ভেঙে ফেলে। এটা করে একগুচ্ছ অনেক layer-এর মাধ্যমে, যেখানে শুরুর layer-গুলো input ছবি নিয়ে খুব সরল ও নির্দিষ্ট প্রশ্নের উত্তর দেয়, আর পরের layer-গুলো ক্রমশ আরও জটিল ও বিমূর্ত ধারণার একটা শ্রেণিবিন্যাস গড়ে তোলে। এমন বহু-layer গঠনের network — দুই বা ততোধিক hidden layer সহ — কে বলা হয় deep neural network।
অবশ্যই আমি বলিনি এই recursive ভাঙাটা উপ-network-এ কীভাবে করতে হয়। হাতে network-এর weight ও bias design করা মোটেই বাস্তবসম্মত নয়। বরং আমরা চাই learning algorithm ব্যবহার করতে, যাতে network training data থেকে স্বয়ংক্রিয়ভাবে weight ও bias — তথা ধারণার শ্রেণিবিন্যাস — শিখে নিতে পারে। ১৯৮০ ও ১৯৯০-এর দশকের গবেষকরা stochastic gradient descent ও backpropagation দিয়ে deep network train করার চেষ্টা করেন। দুর্ভাগ্যবশত, কয়েকটি বিশেষ architecture ছাড়া তাঁদের তেমন সাফল্য আসেনি। Network শিখত, কিন্তু খুব ধীরে, এবং বাস্তবে প্রায়ই কাজে আসার মতো নয় এমন ধীরে।
২০০৬ সাল থেকে একগুচ্ছ কৌশল গড়ে উঠেছে যা deep neural net-এ learning সম্ভব করে। এই deep learning কৌশলগুলো stochastic gradient descent ও backpropagation-এর ভিত্তিতে, তবে নতুন কিছু ধারণাও আনে। এই কৌশল অনেক গভীর (ও বড়) network train করা সম্ভব করেছে — মানুষ এখন রুটিনমাফিক 5 থেকে 10 hidden layer-এর network train করে। আর দেখা যায়, এগুলো অনেক সমস্যায় shallow neural network — অর্থাৎ একটি মাত্র hidden layer-এর network — এর চেয়ে অনেক ভালো করে। কারণ অবশ্যই deep net-এর ধারণার একটা জটিল শ্রেণিবিন্যাস গড়ে তোলার ক্ষমতা। এটা অনেকটা সেভাবে, যেভাবে প্রচলিত programming language জটিল computer program তৈরিতে modular design ও abstraction-এর ধারণা ব্যবহার করে। একটা deep network-কে একটা shallow network-এর সাথে তুলনা করা অনেকটা function call করার ক্ষমতাসম্পন্ন একটা programming language-কে এমন একটা ছাঁটাই-করা language-এর সাথে তুলনা করার মতো যার কোনো call করার ক্ষমতা নেই। Neural network-এ abstraction প্রচলিত programming-এর চেয়ে ভিন্ন রূপ নেয়, কিন্তু তা সমান গুরুত্বপূর্ণ।