অধ্যায় ৩
Neural network-এর শেখার পদ্ধতি উন্নত করা
Improving the way neural networks learn
একজন golf খেলোয়াড় যখন প্রথম খেলা শেখে, তখন বেশিরভাগ সময় সে একটা মৌলিক swing গড়ে তোলায় ব্যয় করে। ধীরে ধীরে সে অন্য shot গুলো রপ্ত করে — chip, draw, fade — যা ওই মৌলিক swing-এর উপর গড়ে ওঠে এবং তাকে পরিবর্তন করে। একইভাবে, এতক্ষণ আমরা backpropagation algorithm বোঝার দিকে মনোযোগ দিয়েছি। এটাই আমাদের "মৌলিক swing", neural network নিয়ে বেশিরভাগ কাজে শেখার ভিত্তি। এই অধ্যায়ে আমি এমন কিছু কৌশল ব্যাখ্যা করব যেগুলো দিয়ে আমাদের backpropagation-এর সাদামাটা implementation উন্নত করা যায়, এবং তার মাধ্যমে আমাদের network যেভাবে শেখে তা ভালো করা যায়।
এই অধ্যায়ে আমরা যে কৌশলগুলো গড়ে তুলব তার মধ্যে আছে: cost function-এর একটা ভালো পছন্দ, যা cross-entropy cost function নামে পরিচিত; চারটি "regularization" পদ্ধতি (L1 ও L2 regularization, dropout, এবং training data-র কৃত্রিম বিস্তার), যেগুলো আমাদের network-কে training data-র বাইরেও ভালোভাবে generalize করতে সাহায্য করে; network-এর weight initialize করার একটা উন্নত পদ্ধতি; এবং network-এর জন্য ভালো hyper-parameter বেছে নিতে সাহায্যকারী কিছু heuristic-এর সমষ্টি। আমি আরও কয়েকটি কৌশল কম গভীরভাবে তুলে ধরব। আলোচনাগুলো মোটামুটি একে অপরের থেকে স্বাধীন, তাই ইচ্ছে হলে তুমি সামনে এগিয়ে যেতে পারো। আমরা অনেকগুলো কৌশল চলমান code-এও implement করব, এবং সেগুলো দিয়ে অধ্যায় ১-এ অধ্যয়ন করা handwriting classification সমস্যার ফল উন্নত করব।
অবশ্যই, neural net-এ ব্যবহারের জন্য তৈরি হওয়া বহু বহু কৌশলের মধ্যে আমরা মাত্র কয়েকটিই আলোচনা করছি। দর্শনটা হলো — উপলব্ধ অসংখ্য কৌশলের জগতে প্রবেশের সবচেয়ে ভালো উপায় হলো সবচেয়ে গুরুত্বপূর্ণ কয়েকটিকে গভীরভাবে অধ্যয়ন করা। ওই গুরুত্বপূর্ণ কৌশলগুলো আয়ত্ত করা শুধু নিজে থেকেই উপকারী নয়, এটা neural network ব্যবহারের সময় কী কী সমস্যা দেখা দিতে পারে সে সম্পর্কে তোমার বোঝাও গভীর করবে। ফলে প্রয়োজন মতো অন্য কৌশল দ্রুত শিখে নিতে তুমি ভালোভাবে প্রস্তুত থাকবে।
Cross-entropy cost function
আমরা বেশিরভাগ মানুষই ভুল হলে অস্বস্তি বোধ করি। piano শেখা শুরু করার অল্প পরেই আমি দর্শকদের সামনে আমার প্রথম পরিবেশনা দিয়েছিলাম। আমি nervous ছিলাম, এবং একটা octave নিচে বাজানো শুরু করলাম। আমি বিভ্রান্ত হয়ে পড়লাম, এবং কেউ একজন আমার ভুল ধরিয়ে দেওয়ার আগ পর্যন্ত এগোতে পারলাম না। আমি ভীষণ লজ্জা পেয়েছিলাম। তবু অস্বস্তিকর হলেও আমরা দ্রুত শিখি যখন আমরা স্পষ্টভাবে ভুল করি। নিশ্চিত থাকতে পারো, এর পরেরবার দর্শকদের সামনে আমি সঠিক octave-এই বাজিয়েছিলাম! তুলনায়, আমাদের ভুলগুলো যখন কম স্পষ্ট হয়, তখন আমরা ধীরে শিখি।
আদর্শভাবে আমরা আশা ও প্রত্যাশা করি যে আমাদের neural network তাদের ভুল থেকে দ্রুত শিখবে। বাস্তবে কি তা-ই ঘটে? এই প্রশ্নের উত্তর দিতে একটা ছোট্ট খেলনা উদাহরণ দেখা যাক। উদাহরণটিতে আছে কেবল একটি input সহ একটি neuron:
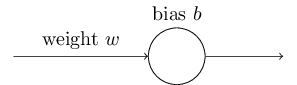
আমরা এই neuron-কে একটা হাস্যকর সহজ কাজ করতে train করব: input -কে output -তে নেওয়া। অবশ্যই এটা এতটাই তুচ্ছ একটা কাজ যে কোনো learning algorithm ছাড়াই হাতে-কলমে আমরা সহজে একটা উপযুক্ত weight ও bias বের করে ফেলতে পারতাম। তবে দেখা যায় যে এই weight ও bias শিখতে gradient descent ব্যবহার করার চেষ্টা করা বেশ আলোকপাত করে। তাই দেখা যাক neuron কীভাবে শেখে।
বিষয়টা নির্দিষ্ট করতে, আমি শুরুর weight বেছে নেব আর শুরুর bias । এগুলো শেখা শুরু করার জায়গা হিসেবে ব্যবহৃত সাধারণ পছন্দ, কোনোভাবে বিশেষ করে বেছে নিইনি। neuron-এর শুরুর output , তাই কাঙ্ক্ষিত output -র কাছে পৌঁছাতে neuron-কে বেশ খানিকটা শিখতে হবে। নিচের চলমান উপস্থাপনায় neuron শেখে; এখানে learning rate , যা যথেষ্ট ধীর যাতে আমরা কী ঘটছে অনুসরণ করতে পারি, অথচ যথেষ্ট দ্রুত যাতে কয়েক সেকেন্ডেই উল্লেখযোগ্য শেখা ঘটে। Cost হলো অধ্যায় ১-এ চালু করা quadratic cost function ।
দেখা যায়, neuron দ্রুত এমন একটা weight ও bias শেখে যা cost-কে নামিয়ে আনে, এবং neuron থেকে প্রায় output দেয়। সেটা ঠিক কাঙ্ক্ষিত output নয়, তবে বেশ ভালো। কিন্তু ধরো, তার বদলে আমরা শুরুর weight ও bias দুটোই বেছে নিলাম। এক্ষেত্রে শুরুর output , যা ভীষণ মাত্রায় ভুল। দেখা যাক এই ক্ষেত্রে neuron কীভাবে output দিতে শেখে।
যদিও এই উদাহরণে একই learning rate () ব্যবহৃত হয়েছে, আমরা দেখি যে শেখা শুরু হয় অনেক বেশি ধীরে। আসলে প্রথম প্রায় ১৫০টি learning epoch জুড়ে weight ও bias প্রায় বদলায়ই না। তারপর শেখা শুরু হয়, এবং আমাদের প্রথম উদাহরণের মতোই neuron-এর output দ্রুত -র কাছে চলে আসে।
মানুষের শেখার সাথে তুলনা করলে এই আচরণ অদ্ভুত। এই section-এর শুরুতে যেমন বলেছিলাম, কোনো কিছুতে যখন আমরা বাজেভাবে ভুল করি তখনই প্রায়ই আমরা সবচেয়ে দ্রুত শিখি। কিন্তু আমরা এইমাত্র দেখলাম যে আমাদের artificial neuron বাজেভাবে ভুল করলে শিখতে অনেক বেশি কষ্ট পায় — সামান্য ভুল করার চেয়ে অনেক বেশি কষ্ট। তাছাড়া এই আচরণ কেবল এই খেলনা model-এই নয়, আরও সাধারণ network-এও ঘটে। শেখা এত ধীর কেন? আর এই মন্থরতা এড়ানোর কোনো উপায় কি আমরা খুঁজে পেতে পারি?
সমস্যাটির উৎস বুঝতে খেয়াল করো যে আমাদের neuron শেখে weight ও bias বদলে, আর সেই বদলের হার নির্ধারিত হয় cost function-এর partial derivative ও দিয়ে। তাই "শেখা ধীর" বলা আর ওই partial derivative-গুলো ছোট বলা একই কথা। চ্যালেঞ্জটা হলো — কেন সেগুলো ছোট তা বোঝা। তা বুঝতে partial derivative-গুলো হিসেব করা যাক। মনে রাখো আমরা quadratic cost function ব্যবহার করছি, যা Equation (6) থেকে দিয়ে দেওয়া, অর্থাৎ:
যেখানে হলো training input ব্যবহার করলে neuron-এর output, আর হলো সংশ্লিষ্ট কাঙ্ক্ষিত output। weight ও bias-এর ভাষায় আরও স্পষ্টভাবে লিখতে মনে রাখো , যেখানে । weight ও bias-এর সাপেক্ষে chain rule দিয়ে differentiate করলে পাই:
যেখানে আমি ও বসিয়েছি। এই রাশিগুলোর আচরণ বুঝতে ডান দিকের পদটির দিকে আরও ভালো করে তাকানো যাক। function-এর আকৃতি মনে করো — output -এর কাছে গেলে curve-টা খুব সমতল হয়ে যায়, ফলে খুব ছোট হয়। তখন Equation (55) ও (56) আমাদের বলে যে ও খুব ছোট হয়ে যায়। এটাই শেখার মন্থরতার উৎস। আর পরে দেখব, কেবল এই খেলনা উদাহরণে নয়, আরও সাধারণ neural network-এও মোটামুটি একই কারণে শেখার মন্থরতা ঘটে।
Cross-entropy cost function-এর সূচনা
শেখার মন্থরতা আমরা কীভাবে সামলাতে পারি? দেখা যায় quadratic cost-কে একটা ভিন্ন cost function — যাকে cross-entropy বলা হয় — দিয়ে প্রতিস্থাপন করে সমস্যাটা সমাধান করা যায়। Cross-entropy বুঝতে আমাদের অতি-সরল খেলনা model থেকে একটু সরে আসা যাক। তার বদলে ধরো আমরা একটা neuron train করতে চাইছি যার একাধিক input variable , সংশ্লিষ্ট weight , এবং একটা bias :
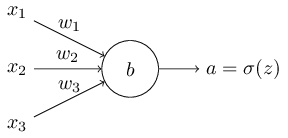
neuron-এর output অবশ্যই , যেখানে হলো input-গুলোর weighted sum। এই neuron-এর জন্য cross-entropy cost function সংজ্ঞায়িত করি:
যেখানে হলো training data-র মোট আইটেম সংখ্যা, যোগফল সমস্ত training input -এর উপর, আর হলো সংশ্লিষ্ট কাঙ্ক্ষিত output।
রাশি (57) যে শেখার মন্থরতার সমস্যা ঠিক করে দেয় তা স্পষ্ট নয়। আসলে সত্যি বলতে এটাকে cost function বলা যৌক্তিক কিনা তা-ও স্পষ্ট নয়! শেখার মন্থরতা সামলানোর আগে দেখা যাক কোন অর্থে cross-entropy-কে cost function হিসেবে ব্যাখ্যা করা যায়।
বিশেষত দুটি ধর্ম cross-entropy-কে cost function হিসেবে ব্যাখ্যা করা যুক্তিসঙ্গত করে তোলে। প্রথমত, এটা অঋণাত্মক, অর্থাৎ । দেখতে খেয়াল করো: (a) যোগফল (57)-এর প্রতিটি পদ ঋণাত্মক, কারণ দুটো logarithm-ই থেকে -এর মধ্যেকার সংখ্যার; এবং (b) যোগফলের সামনে একটা minus চিহ্ন আছে।
দ্বিতীয়ত, neuron-এর প্রকৃত output যদি সমস্ত training input -এর জন্য কাঙ্ক্ষিত output-এর কাছাকাছি হয়, তাহলে cross-entropy শূন্যের কাছাকাছি হবে। দেখতে ধরো উদাহরণস্বরূপ কোনো input -এর জন্য ও । এটা এমন একটা ক্ষেত্র যেখানে neuron ওই input-এ ভালো কাজ করছে। দেখি cost-এর রাশি (57)-এর প্রথম পদটি লোপ পায়, কারণ , আর দ্বিতীয় পদটি কেবল । একইরকম বিশ্লেষণ খাটে যখন ও । তাই প্রকৃত output কাঙ্ক্ষিত output-এর কাছাকাছি হলে cost-এ অবদান কম হবে।
সংক্ষেপে, cross-entropy ধনাত্মক, এবং neuron সমস্ত training input -এর জন্য কাঙ্ক্ষিত output compute করায় যত ভালো হয়, এটা তত শূন্যের দিকে ঝোঁকে। cost function-এর কাছ থেকে আমরা স্বজ্ঞাতভাবে এই দুটো ধর্মই প্রত্যাশা করি। আসলে quadratic cost-ও এই দুটো ধর্ম মেনে চলে। তাই cross-entropy-র জন্য এটা সুসংবাদ। কিন্তু cross-entropy cost function-এর সুবিধা হলো — quadratic cost-এর বিপরীতে, এটা শেখা ধীর হয়ে যাওয়ার সমস্যা এড়ায়। দেখতে weight-এর সাপেক্ষে cross-entropy cost-এর partial derivative হিসেব করি। (57)-এ বসিয়ে দুবার chain rule প্রয়োগ করে পাই:
সবকিছু একটা সাধারণ হর-এর উপর এনে সরল করলে এটা দাঁড়ায়:
sigmoid function-এর সংজ্ঞা ও সামান্য algebra ব্যবহার করে দেখানো যায় যে । নিচের একটা অনুশীলনীতে আমি তোমাকে এটা যাচাই করতে বলব, তবে আপাতত এটা ধরে নেওয়া যাক। দেখি উপরের সমীকরণে ও পদদুটো কেটে যায়, এবং এটা সরল হয়ে দাঁড়ায়:
এটা একটা চমৎকার রাশি। এটা আমাদের বলে যে weight যে হারে শেখে তা নিয়ন্ত্রণ করে , অর্থাৎ output-এর error। error যত বড়, neuron তত দ্রুত শিখবে। ঠিক যা আমরা স্বজ্ঞাতভাবে প্রত্যাশা করি। বিশেষত, quadratic cost-এর অনুরূপ সমীকরণ — Equation (55) — এর পদের কারণে যে শেখার মন্থরতা ঘটে তা এটা এড়ায়। cross-entropy ব্যবহার করলে পদটি কেটে যায়, এবং এটা ছোট হওয়া নিয়ে আমাদের আর দুশ্চিন্তা করতে হয় না। এই কেটে যাওয়াটাই cross-entropy cost function-এর নিশ্চিত করা বিশেষ অলৌকিকতা। আসলে এটা ঠিক অলৌকিকও নয়। পরে দেখব, cross-entropy ঠিক এই ধর্মটি পাওয়ার জন্যই বিশেষভাবে বেছে নেওয়া হয়েছিল।
একইভাবে আমরা bias-এর জন্য partial derivative হিসেব করতে পারি। আবার সব বিস্তারিত করছি না, তবে তুমি সহজেই যাচাই করতে পারো যে:
আবারও, এটা quadratic cost-এর অনুরূপ সমীকরণ — Equation (56) — এর পদের কারণে ঘটা শেখার মন্থরতা এড়ায়।
আগে যে খেলনা উদাহরণ নিয়ে কাজ করেছিলাম তাতে ফিরে যাই, এবং quadratic cost-এর বদলে cross-entropy ব্যবহার করলে কী ঘটে তা দেখি। নিজেদের মনে করিয়ে দিতে শুরু করব ওই ক্ষেত্র দিয়ে যেখানে quadratic cost ভালোই কাজ করেছিল — শুরুর weight ও শুরুর bias নিয়ে। অবাক হওয়ার কিছু নেই, এক্ষেত্রে neuron আগের মতোই চমৎকারভাবে শেখে।
আর এখন দেখি ওই ক্ষেত্রটা যেখানে আমাদের neuron আগে আটকে গিয়েছিল — weight ও bias দুটোই থেকে শুরু করে। সফল! এবার neuron দ্রুত শিখল, ঠিক যেমন আমরা আশা করেছিলাম। মন দিয়ে লক্ষ করলে দেখবে cost curve-এর ঢাল শুরুতে অনেক বেশি খাড়া ছিল — quadratic cost-এর সংশ্লিষ্ট curve-এর শুরুর সমতল অঞ্চলের তুলনায়। ওই খাড়াত্বটাই cross-entropy আমাদের এনে দেয়, যা আমাদের ঠিক ওই মুহূর্তে আটকে যাওয়া থেকে বাঁচায় যখন আমরা আশা করি neuron দ্রুততম শিখবে — অর্থাৎ যখন neuron বাজেভাবে ভুল করে শুরু করে।
এইমাত্র দেখানো উদাহরণগুলোতে কোন learning rate ব্যবহৃত হয়েছিল তা বলিনি। আগে quadratic cost-এর সাথে আমরা ব্যবহার করেছিলাম। নতুন উদাহরণগুলোতে কি একই learning rate ব্যবহার করা উচিত ছিল? আসলে cost function বদলে যাওয়ায় "একই" learning rate ব্যবহারের অর্থ ঠিক কী তা বলা সম্ভব নয়; এটা আপেল আর কমলালেবুর তুলনা। দুটো cost function-এর জন্যই আমি কী ঘটছে তা দেখা সম্ভব হয় এমন একটা learning rate খুঁজতে শুধু পরীক্ষা-নিরীক্ষা করেছি। তবু কৌতূহল থাকলে জেনে রাখো: এইমাত্র দেওয়া উদাহরণগুলোতে আমি ব্যবহার করেছিলাম।
তুমি হয়তো আপত্তি করবে যে learning rate বদলে যাওয়ায় উপরের graph-গুলো অর্থহীন হয়ে যায়। যখন learning rate-এর পছন্দটাই শুরুতে যথেচ্ছ ছিল, তখন neuron কত দ্রুত শেখে তাতে কার কী এসে যায়! এই আপত্তি মূল বিষয়টা মিস করে যায়। graph-গুলোর উদ্দেশ্য শেখার পরম গতি নিয়ে নয়। এটা শেখার গতি কীভাবে বদলায় তা নিয়ে। বিশেষত, quadratic cost ব্যবহার করলে neuron যখন নিঃসন্দেহে ভুল তখন শেখা ধীর হয়, পরে neuron সঠিক output-এর কাছে এলে যত দ্রুত হয় তার চেয়ে; অথচ cross-entropy-র সাথে neuron নিঃসন্দেহে ভুল হলে শেখা দ্রুততর হয়। এই কথাগুলো learning rate কীভাবে সেট করা হয়েছে তার উপর নির্ভর করে না।
আমরা একটি মাত্র neuron-এর জন্য cross-entropy অধ্যয়ন করছিলাম। তবে অনেক-neuron ও বহু-layer network-এ cross-entropy-কে generalize করা সহজ। বিশেষত, ধরো হলো output neuron — অর্থাৎ শেষ layer-এর neuron — গুলোর কাঙ্ক্ষিত মান, আর হলো প্রকৃত output মান। তখন cross-entropy সংজ্ঞায়িত করি:
এটা আমাদের আগের রাশি Equation (57)-এর মতোই, কেবল এখন সমস্ত output neuron-এর উপর যোগ করছে। আমি স্পষ্টভাবে একটা derivation করছি না, তবে এটা বিশ্বাসযোগ্য হওয়া উচিত যে রাশি (63) ব্যবহার করলে অনেক-neuron network-এ শেখার মন্থরতা এড়ানো যায়। আগ্রহী হলে নিচের সমস্যায় derivation-টা করে দেখতে পারো।
প্রসঙ্গত, আমি "cross-entropy" শব্দটা এমনভাবে ব্যবহার করছি যা কিছু পাঠককে বিভ্রান্ত করেছে, কারণ এটা ভাসাভাসাভাবে অন্যান্য উৎসের সাথে সাংঘর্ষিক মনে হয়। বিশেষত, দুটো probability distribution ও -এর জন্য cross-entropy-কে হিসেবে সংজ্ঞায়িত করা প্রচলিত। একটা একক sigmoid neuron-কে যদি তার activation ও তার পরিপূরক নিয়ে গঠিত একটা probability distribution output করছে ধরা হয়, তাহলে এই সংজ্ঞাকে (57)-এর সাথে যুক্ত করা যায়।
তবে শেষ layer-এ যখন অনেকগুলো sigmoid neuron থাকে, তখন activation-এর vector সাধারণত কোনো probability distribution গঠন করে না। ফলে -এর মতো সংজ্ঞা অর্থপূর্ণই হয় না, কারণ আমরা probability distribution নিয়ে কাজ করছি না। তার বদলে তুমি (63)-কে ভাবতে পারো per-neuron cross-entropy-গুলোর একটা যোগফল হিসেবে, যেখানে প্রতিটি neuron-এর activation-কে দুই-উপাদানের একটা probability distribution-এর অংশ হিসেবে ব্যাখ্যা করা হয়। (অবশ্য আমাদের network-এ কোনো probabilistic উপাদান নেই, তাই এগুলো ঠিক probability নয়।) এই অর্থে (63) হলো probability distribution-এর জন্য cross-entropy-র একটা generalization।
কখন quadratic cost-এর বদলে cross-entropy ব্যবহার করা উচিত? আসলে output neuron-গুলো sigmoid neuron হলে cross-entropy প্রায় সবসময়ই ভালো পছন্দ। কেন তা বুঝতে ভাবো — network সেট করার সময় আমরা সাধারণত weight ও bias-গুলো কোনো ধরনের randomization দিয়ে initialize করি। এমন হতে পারে যে ওই শুরুর পছন্দগুলোর কারণে কোনো training input-এ network নিঃসন্দেহে ভুল হবে — অর্থাৎ একটা output neuron -এর কাছে saturate হয়ে আছে, যখন তার হওয়া উচিত ছিল, বা উল্টোটা। আমরা quadratic cost ব্যবহার করলে তা শেখাকে ধীর করে দেবে। এটা শেখা পুরোপুরি থামাবে না, কারণ অন্য training input থেকে weight শিখতে থাকবে, তবে স্পষ্টতই এটা অবাঞ্ছিত।
Cross-entropy দিয়ে MNIST সংখ্যা classify করা
gradient descent ও backpropagation দিয়ে শেখে এমন একটা program-এর অংশ হিসেবে cross-entropy implement করা সহজ। আমরা এই অধ্যায়ের পরে তা করব — MNIST হাতে লেখা সংখ্যা classify করার জন্য আমাদের আগের program network.py-এর একটা উন্নত সংস্করণ তৈরি করে। নতুন program-টির নাম network2.py, এবং এটাতে কেবল cross-entropy নয়, এই অধ্যায়ে গড়ে তোলা আরও কয়েকটি কৌশলও আছে (code-টা GitHub-এ পাওয়া যায়)। আপাতত দেখা যাক আমাদের নতুন program MNIST সংখ্যা কতটা ভালো classify করে। অধ্যায় ১-এর মতোই আমরা টি hidden neuron সহ একটা network ব্যবহার করব, এবং আকারের mini-batch ব্যবহার করব। আমরা learning rate সেট করব , এবং টি epoch ধরে train করব।
network2.py-এর interface network.py-এর চেয়ে সামান্য আলাদা, তবে কী ঘটছে তা স্পষ্ট হওয়ার কথা। প্রসঙ্গত, Python shell-এ help(network2.Network.SGD)-এর মতো command দিয়ে তুমি network2.py-এর interface সম্পর্কে documentation পেতে পারো।
>>> import mnist_loader
>>> training_data, validation_data, test_data = \
... mnist_loader.load_data_wrapper()
>>> import network2
>>> net = network2.Network([784, 30, 10], cost=network2.CrossEntropyCost)
>>> net.large_weight_initializer()
>>> net.SGD(training_data, 30, 10, 0.5, evaluation_data=test_data,
... monitor_evaluation_accuracy=True)প্রসঙ্গত খেয়াল করো, net.large_weight_initializer() command-টি ব্যবহার করা হয় অধ্যায় ১-এ বর্ণিত পদ্ধতিতেই weight ও bias initialize করার জন্য। এই command চালাতে হয় কারণ এই অধ্যায়ের পরে আমরা আমাদের network-এ default weight initialization বদলে দেব। উপরের command-গুলোর ধারা চালানোর ফল হলো শতাংশ accuracy-যুক্ত একটা network। এটা quadratic cost দিয়ে অধ্যায় ১-এ পাওয়া ফল শতাংশের বেশ কাছাকাছি।
চলো সেই ক্ষেত্রটাও দেখি যেখানে আমরা টি hidden neuron, cross-entropy ব্যবহার করি, আর বাকি parameter একই রাখি। এই ক্ষেত্রে আমরা শতাংশ accuracy পাই। অধ্যায় ১-এর ফলের তুলনায় এটা একটা উল্লেখযোগ্য উন্নতি, যেখানে quadratic cost দিয়ে আমরা শতাংশ classification accuracy পেয়েছিলাম। এটা ছোট পরিবর্তন মনে হতে পারে, তবে ভাবো error rate শতাংশ থেকে শতাংশে নেমেছে। অর্থাৎ আমরা মূল error-এর প্রায় চৌদ্দ ভাগের এক ভাগ দূর করেছি। বেশ কাজের একটা উন্নতি।
উৎসাহজনক যে cross-entropy cost আমাদের quadratic cost-এর সমান বা তার চেয়ে ভালো ফল দেয়। তবে এই ফলগুলো নিশ্চিতভাবে প্রমাণ করে না যে cross-entropy ভালো পছন্দ। কারণ আমি learning rate, mini-batch size প্রভৃতি hyper-parameter বেছে নিতে সামান্যই পরিশ্রম করেছি। উন্নতিটা সত্যিকার বিশ্বাসযোগ্য হতে হলে আমাদের এই hyper-parameter গুলো নিখুঁতভাবে optimize করার পুরো কাজটা করতে হতো। তবু ফল উৎসাহজনক, এবং cross-entropy যে quadratic cost-এর চেয়ে ভালো পছন্দ — আমাদের আগের তত্ত্বীয় যুক্তিকে এটা জোরালো করে।
প্রসঙ্গত, এটা একটা সাধারণ ধাঁচের অংশ যা আমরা এই অধ্যায়ে — এবং আসলে বইয়ের বাকি অনেকটা জুড়ে — দেখব। আমরা একটা নতুন কৌশল গড়ব, সেটা পরখ করব, এবং "উন্নত" ফল পাব। অবশ্যই এমন উন্নতি দেখা ভালো। কিন্তু এমন উন্নতির ব্যাখ্যা সবসময় সমস্যা সংকুল। সেগুলো তখনই সত্যিকার বিশ্বাসযোগ্য যখন বাকি সব hyper-parameter optimize করায় প্রচুর পরিশ্রম দেওয়ার পর আমরা একটা উন্নতি দেখি। সেটা প্রচুর কাজ, প্রচুর computing power দরকার, আর সাধারণত আমরা এমন নিঃশেষ অনুসন্ধান করব না। তার বদলে আমরা উপরের মতো অনানুষ্ঠানিক পরীক্ষার ভিত্তিতে এগোব। তবু মনে রেখো এমন পরীক্ষা চূড়ান্ত প্রমাণের থেকে কম, এবং যুক্তিগুলো ভেঙে পড়ার লক্ষণের প্রতি সতর্ক থাকো।
এতক্ষণে আমরা cross-entropy নিয়ে বিস্তারিত আলোচনা করলাম। আমাদের MNIST ফলে সামান্য উন্নতি দিলেও এত পরিশ্রম কেন? অধ্যায়ের পরে আমরা অন্য কৌশল দেখব — বিশেষত regularization — যা অনেক বড় উন্নতি দেয়। তাহলে cross-entropy-তে এত মনোযোগ কেন? এর একটা কারণ হলো cross-entropy একটা ব্যাপকভাবে ব্যবহৃত cost function, তাই ভালোভাবে বোঝা সার্থক। তবে আরও গুরুত্বপূর্ণ কারণ হলো neuron saturation neural net-এ একটা গুরুত্বপূর্ণ সমস্যা, যেটায় আমরা বইয়ের সর্বত্র বারবার ফিরব। তাই neuron saturation ও তা কীভাবে সামলানো যায় তা বোঝা শুরু করার একটা ভালো গবেষণাগার হিসেবে আমি cross-entropy নিয়ে বিস্তারিত আলোচনা করেছি।
Cross-entropy-র অর্থ কী? এটা কোথা থেকে আসে?
cross-entropy নিয়ে আমাদের আলোচনা algebraic বিশ্লেষণ ও বাস্তব implementation-এ মনোযোগ দিয়েছে। সেটা উপকারী, তবে এটা কিছু বৃহত্তর ধারণাগত প্রশ্ন অনুত্তরিত রেখে যায়, যেমন: cross-entropy-র অর্থ কী? cross-entropy নিয়ে ভাবার কোনো স্বজ্ঞাত উপায় আছে কি? আর শুরুতে cross-entropy-র কথা আমরা আদৌ ভাবলামই বা কীভাবে?
এর শেষেরটা দিয়ে শুরু করি: শুরুতে cross-entropy ভাবতে আমাদের কী অনুপ্রাণিত করতে পারত? ধরো আমরা আগে বর্ণিত শেখার মন্থরতা আবিষ্কার করেছিলাম, এবং বুঝেছিলাম যে এর উৎস Equation (55) ও (56)-এর পদ। ওই সমীকরণগুলোর দিকে কিছুক্ষণ তাকিয়ে আমরা ভাবতে পারতাম — এমন একটা cost function বেছে নেওয়া কি সম্ভব যাতে পদটি অদৃশ্য হয়ে যায়? সেক্ষেত্রে একটি একক training example -এর cost মেনে চলত:
আমরা যদি cost function-কে এমনভাবে বেছে নিতে পারতাম যাতে এই সমীকরণগুলো সত্যি হয়, তবে সেগুলো সরল উপায়ে সেই স্বজ্ঞাকে ধরত যে শুরুর error যত বড়, neuron তত দ্রুত শেখে। সেগুলো শেখার মন্থরতার সমস্যাও দূর করত। আসলে এই সমীকরণগুলো থেকে শুরু করে আমরা এখন দেখাব যে শুধু গাণিতিক চিন্তার সূত্র অনুসরণ করে cross-entropy-র রূপ উদ্ভাবন করা সম্ভব। দেখতে খেয়াল করো chain rule থেকে আমরা পাই:
ব্যবহার করে শেষ সমীকরণটি দাঁড়ায়:
Equation (72)-এর সাথে তুলনা করে পাই:
এই রাশিকে -এর সাপেক্ষে integrate করলে পাই:
কোনো একটা integration constant-সহ। এটা একটা একক training example থেকে cost-এ অবদান। পূর্ণ cost function পেতে আমাদের training example-গুলোর উপর গড় নিতে হবে, যাতে পাই:
যেখানে এখানকার constant হলো প্রতিটি training example-এর আলাদা constant-গুলোর গড়। আর তাই আমরা দেখি যে Equation (71) ও (72) একটা সার্বিক constant পদ পর্যন্ত cross-entropy-র রূপ অনন্যভাবে নির্ধারণ করে। cross-entropy অলৌকিকভাবে শূন্য থেকে টেনে বের করা কিছু নয়। বরং এটা এমন কিছু যা আমরা সরল ও স্বাভাবিক উপায়েই আবিষ্কার করতে পারতাম।
cross-entropy-র স্বজ্ঞাত অর্থ কী? এটা নিয়ে আমরা কীভাবে ভাবব? এটা গভীরভাবে ব্যাখ্যা করতে গেলে আমি যতদূর যেতে চাই তার বাইরে চলে যাবে। তবে উল্লেখযোগ্য যে information theory ক্ষেত্র থেকে আসা cross-entropy ব্যাখ্যার একটা standard উপায় আছে। মোটামুটিভাবে ধারণাটা হলো — cross-entropy হলো বিস্ময়ের একটা পরিমাপ। বিশেষত, আমাদের neuron function compute করার চেষ্টা করছে। কিন্তু তার বদলে এটা compute করে function। ধরো -কে আমরা ভাবি neuron-এর অনুমিত probability হিসেবে যে হলো , আর হলো অনুমিত probability যে -এর সঠিক মান । তখন cross-entropy পরিমাপ করে -এর প্রকৃত মান জানার সময় আমরা গড়ে কতটা "বিস্মিত" হই। output যেমন প্রত্যাশা করি তেমন হলে কম বিস্ময়, আর অপ্রত্যাশিত হলে বেশি বিস্ময়। অবশ্যই "বিস্ময়" বলতে ঠিক কী বোঝায় তা বলিনি, তাই এটা হয়তো ফাঁকা বাগাড়ম্বর মনে হতে পারে। কিন্তু আসলে বিস্ময় বলতে কী বোঝায় তা বলার একটা সুনির্দিষ্ট information-theoretic উপায় আছে। দুর্ভাগ্যবশত এই বিষয়ে অনলাইনে একটা ভালো, সংক্ষিপ্ত, স্বয়ংসম্পূর্ণ আলোচনা আমার জানা নেই। আরও গভীরে যেতে চাইলে Wikipedia-তে একটা সংক্ষিপ্ত সারাংশ আছে যা তোমাকে সঠিক পথে যাত্রা শুরু করাবে, এবং বিস্তারিত পাওয়া যাবে Cover ও Thomas-এর information theory বইয়ের ৫ম অধ্যায়ের Kraft inequality সংক্রান্ত উপাদানগুলোতে।
Softmax
এই অধ্যায়ে আমরা শেখার মন্থরতার সমস্যা সামলাতে বেশিরভাগ ক্ষেত্রে cross-entropy cost ব্যবহার করব। তবে সমস্যাটির আরেকটা পদ্ধতি সংক্ষেপে বর্ণনা করতে চাই, যা softmax নামক neuron-এর layer-এর উপর ভিত্তি করে। অধ্যায়ের বাকি অংশে আমরা softmax layer আসলে ব্যবহার করব না, তাই খুব তাড়া থাকলে পরের section-এ চলে যেতে পারো। তবে softmax বোঝা সার্থক, আংশিক কারণ এটা নিজে থেকেই কৌতূহলোদ্দীপক, এবং আংশিক কারণ আমরা অধ্যায় ৬-এ deep neural network নিয়ে আলোচনায় softmax layer ব্যবহার করব।
softmax-এর ধারণা হলো আমাদের neural network-এর জন্য একটা নতুন ধরনের output layer সংজ্ঞায়িত করা। এটা sigmoid layer-এর মতোই শুরু হয়, weighted input গঠন করে। তবে output পেতে আমরা sigmoid function প্রয়োগ করি না। তার বদলে একটা softmax layer-এ আমরা -এর উপর softmax function প্রয়োগ করি। এই function অনুসারে -তম output neuron-এর activation হলো:
যেখানে হর-এ আমরা সমস্ত output neuron-এর উপর যোগ করি।
softmax function-এর সাথে পরিচিত না হলে Equation (78) বেশ দুর্বোধ্য মনে হতে পারে। আমরা কেন এই function ব্যবহার করতে চাই তা স্পষ্ট নয়। আর এটা যে শেখার মন্থরতার সমস্যা সামলাতে সাহায্য করবে তা-ও স্পষ্ট নয়। Equation (78) আরও ভালো করে বুঝতে ধরো আমাদের চারটি output neuron সহ একটা network আছে, আর সংশ্লিষ্ট চারটি weighted input, যাদের আমরা ও দিয়ে চিহ্নিত করব। নিচের slider-গুলো weighted input-এর সম্ভাব্য মান ও সংশ্লিষ্ট output activation-এর graph দেখায়; অনুসন্ধান শুরু করার একটা ভালো জায়গা হলো বাড়ানো।
তুমি বাড়ালে সংশ্লিষ্ট output activation বাড়তে দেখবে, আর বাকি output activation কমতে দেখবে। একইভাবে কমালে কমবে, আর বাকি সব output activation বাড়বে। আসলে মন দিয়ে দেখলে দেখবে দুই ক্ষেত্রেই বাকি activation-গুলোর মোট পরিবর্তন -এর পরিবর্তনকে ঠিক পুষিয়ে দেয়। কারণ output activation-গুলোর যোগফল সবসময় হওয়ার নিশ্চয়তা দেওয়া আছে, যা Equation (78) ও সামান্য algebra দিয়ে আমরা প্রমাণ করতে পারি:
ফলে বাড়লে বাকি output activation-গুলোকে একই মোট পরিমাণে কমতে হবে, যাতে সব activation-এর যোগফল থাকে। আর অবশ্যই বাকি সব activation-এর ক্ষেত্রেও একইরকম কথা খাটে।
Equation (78) আরও বোঝায় যে output activation-গুলো সবই ধনাত্মক, কারণ exponential function ধনাত্মক। একে গত অনুচ্ছেদের পর্যবেক্ষণের সাথে মিলিয়ে দেখি যে softmax layer-এর output হলো এমন একগুচ্ছ ধনাত্মক সংখ্যা যাদের যোগফল । অন্যভাবে বললে, softmax layer-এর output-কে একটা probability distribution হিসেবে ভাবা যায়।
softmax layer যে একটা probability distribution output করে তা বেশ আনন্দদায়ক। অনেক সমস্যায় output activation -কে সঠিক output হওয়ার probability সম্পর্কে network-এর অনুমান হিসেবে ব্যাখ্যা করতে পারা সুবিধাজনক। যেমন MNIST classification সমস্যায় আমরা -কে সঠিক সংখ্যা-classification যে তার সম্পর্কে network-এর অনুমিত probability হিসেবে ব্যাখ্যা করতে পারি।
তুলনায়, output layer যদি sigmoid layer হতো তবে activation-গুলো একটা probability distribution গঠন করে — এটা নিশ্চিত ধরে নেওয়া যেত না। আমি স্পষ্টভাবে প্রমাণ করব না, তবে এটা বিশ্বাসযোগ্য হওয়া উচিত যে sigmoid layer-এর activation-গুলো সাধারণভাবে কোনো probability distribution গঠন করবে না। তাই sigmoid output layer-এর সাথে output activation-গুলোর এমন সরল ব্যাখ্যা আমাদের নেই।
আমরা softmax function ও softmax layer যেভাবে আচরণ করে সে সম্পর্কে কিছুটা অনুভূতি গড়ে তুলতে শুরু করেছি। আমরা কোথায় আছি তা একবার দেখে নিই: Equation (78)-এর exponential-গুলো নিশ্চিত করে যে সব output activation ধনাত্মক। আর হর-এর যোগফল নিশ্চিত করে যে softmax output-গুলো -এ যোগ হয়। তাই ওই নির্দিষ্ট রূপটা আর অতটা রহস্যময় মনে হয় না: বরং output activation-গুলোকে একটা probability distribution গঠন করানোর এটা একটা স্বাভাবিক উপায়। softmax-কে তুমি -গুলোকে পুনরায় স্কেল করে, তারপর একসাথে চেপে একটা probability distribution গঠন করার একটা উপায় হিসেবে ভাবতে পারো।
শেখার মন্থরতার সমস্যা: আমরা এখন softmax neuron-এর layer সম্পর্কে যথেষ্ট পরিচিতি গড়ে তুলেছি। কিন্তু softmax layer কীভাবে শেখার মন্থরতার সমস্যা সামলাতে দেয় তা এখনও দেখিনি। তা বুঝতে চলো log-likelihood cost function সংজ্ঞায়িত করি। আমরা দিয়ে network-এর একটা training input বোঝাব, আর দিয়ে সংশ্লিষ্ট কাঙ্ক্ষিত output। তখন এই training input-এর সাথে যুক্ত log-likelihood cost হলো:
যেমন, আমরা MNIST ছবি দিয়ে train করছি, এবং একটা -এর ছবি input দিলাম, তখন log-likelihood cost হলো । এটা যে স্বজ্ঞাতভাবে অর্থপূর্ণ তা দেখতে ভাবো — network যখন ভালো কাজ করছে, অর্থাৎ এটা নিশ্চিত যে input একটা । সেক্ষেত্রে এটা সংশ্লিষ্ট probability -এর জন্য -এর কাছাকাছি একটা মান অনুমান করবে, তাই cost ছোট হবে। তুলনায়, network ততটা ভালো কাজ না করলে probability ছোট হবে, আর cost বড় হবে। তাই log-likelihood cost একটা cost function থেকে আমরা যেমন আচরণ আশা করি তেমনই আচরণ করে।
শেখার মন্থরতার সমস্যা সম্পর্কে কী বলা যায়? তা বিশ্লেষণ করতে মনে করো শেখার মন্থরতার মূল চাবিকাঠি হলো ও রাশিগুলোর আচরণ। আমি স্পষ্টভাবে derivation করব না — নিচের সমস্যায় তা করতে বলব — তবে সামান্য algebra দিয়ে দেখানো যায় যে:
এই সমীকরণগুলো cross-entropy-র আমাদের আগের বিশ্লেষণে পাওয়া অনুরূপ রাশিগুলোর সমান। উদাহরণস্বরূপ Equation (82)-কে Equation (67)-এর সাথে তুলনা করো। এটা একই সমীকরণ, যদিও পরেরটিতে আমি training instance-গুলোর উপর গড় নিয়েছি। আর আগের বিশ্লেষণের মতোই এই রাশিগুলো নিশ্চিত করে যে আমরা শেখার মন্থরতার সম্মুখীন হব না। আসলে log-likelihood cost সহ একটা softmax output layer-কে cross-entropy cost সহ একটা sigmoid output layer-এর সাথে বেশ সদৃশ ভাবা উপকারী।
এই সাদৃশ্য দেওয়া থাকলে, তোমার কি একটা sigmoid output layer ও cross-entropy ব্যবহার করা উচিত, নাকি একটা softmax output layer ও log-likelihood? আসলে অনেক পরিস্থিতিতে দুটো পদ্ধতিই ভালো কাজ করে। এই অধ্যায়ের বাকি অংশে আমরা cross-entropy cost সহ একটা sigmoid output layer ব্যবহার করব। পরে অধ্যায় ৬-এ আমরা মাঝে মাঝে log-likelihood cost সহ একটা softmax output layer ব্যবহার করব। এই বদলের কারণ হলো আমাদের পরের কিছু network-কে কিছু প্রভাবশালী academic paper-এ পাওয়া network-এর সাথে আরও সদৃশ করা। আরও সাধারণ নীতি হিসেবে, output activation-গুলোকে probability হিসেবে ব্যাখ্যা করতে চাইলে softmax আর log-likelihood ব্যবহার করা সার্থক। সেটা সবসময় উদ্বেগের বিষয় নয়, তবে পরস্পর-বিচ্ছিন্ন class জড়িত classification সমস্যায় (যেমন MNIST) উপকারী হতে পারে।
Overfitting ও regularization
নোবেলজয়ী পদার্থবিদ Enrico Fermi-কে একবার তাঁর কয়েকজন সহকর্মীর প্রস্তাবিত একটা গাণিতিক model সম্পর্কে মতামত জিজ্ঞেস করা হয়েছিল, যা একটা গুরুত্বপূর্ণ অমীমাংসিত পদার্থবিজ্ঞান সমস্যার সমাধান হিসেবে দেওয়া হয়েছিল। model-টা পরীক্ষার সাথে চমৎকার মিল দিয়েছিল, কিন্তু Fermi সন্দিহান ছিলেন। তিনি জিজ্ঞেস করলেন model-এ কতগুলো free parameter সেট করা যায়। উত্তর ছিল "চারটি"। Fermi জবাব দিলেন: "আমার বন্ধু Johnny von Neumann বলতেন, চারটি parameter দিয়ে আমি একটা হাতি fit করতে পারি, আর পাঁচটি দিয়ে তাকে শুঁড় নাড়াতে পারি।"
মূল কথাটা অবশ্যই এই যে — প্রচুর free parameter-যুক্ত model বিস্ময়কর বিস্তৃত পরিসরের ঘটনা বর্ণনা করতে পারে। এমন model উপলব্ধ data-র সাথে ভালো মিললেও তা একে ভালো model করে তোলে না। এর অর্থ হয়তো শুধু এই যে model-এ যথেষ্ট স্বাধীনতা আছে যাতে এটা অন্তর্নিহিত ঘটনা সম্পর্কে কোনো প্রকৃত অন্তর্দৃষ্টি ধরা ছাড়াই দেওয়া আকারের প্রায় যেকোনো data set বর্ণনা করতে পারে। তেমন হলে model বিদ্যমান data-র জন্য ভালো কাজ করবে, কিন্তু নতুন পরিস্থিতিতে generalize করতে ব্যর্থ হবে। একটা model-এর প্রকৃত পরীক্ষা হলো আগে দেখেনি এমন পরিস্থিতিতে ভবিষ্যদ্বাণী করার ক্ষমতা।
Fermi ও von Neumann চার-parameter model নিয়ে সন্দিহান ছিলেন। MNIST সংখ্যা classify করার জন্য আমাদের 30 hidden neuron-এর network-এ প্রায় 24,000 parameter আছে! অনেক parameter। আমাদের 100 hidden neuron-এর network-এ প্রায় 80,000 parameter, আর state-of-the-art deep neural net-এ কখনও কখনও লক্ষ এমনকি কোটি parameter থাকে। আমাদের কি ফলগুলোতে আস্থা রাখা উচিত?
এই সমস্যাটাকে আরও তীক্ষ্ণ করতে এমন একটা পরিস্থিতি গড়ি যেখানে আমাদের network নতুন পরিস্থিতিতে generalize করায় খারাপ করে। আমরা আমাদের 30 hidden neuron-এর network ব্যবহার করব, যার 23,860 parameter আছে। কিন্তু network-কে আমরা সব 50,000 MNIST training ছবি দিয়ে train করব না। তার বদলে কেবল প্রথম 1,000 training ছবি ব্যবহার করব। ওই সীমিত সেট ব্যবহার করলে generalization-এর সমস্যা অনেক বেশি স্পষ্ট হবে। আমরা আগের মতোই cross-entropy cost function, learning rate ও mini-batch size দিয়ে train করব। তবে এবার আমরা 400 epoch ধরে train করব, আগের চেয়ে কিছুটা বেশি, কারণ আমরা ততগুলো training example ব্যবহার করছি না। network2 দিয়ে cost function কীভাবে বদলায় তা দেখি:
>>> import mnist_loader
>>> training_data, validation_data, test_data = \
... mnist_loader.load_data_wrapper()
>>> import network2
>>> net = network2.Network([784, 30, 10], cost=network2.CrossEntropyCost)
>>> net.large_weight_initializer()
>>> net.SGD(training_data[:1000], 400, 10, 0.5, evaluation_data=test_data,
... monitor_evaluation_accuracy=True, monitor_training_cost=True)ফলাফল ব্যবহার করে network শেখার সাথে সাথে cost কীভাবে বদলায় তা plot করতে পারি:
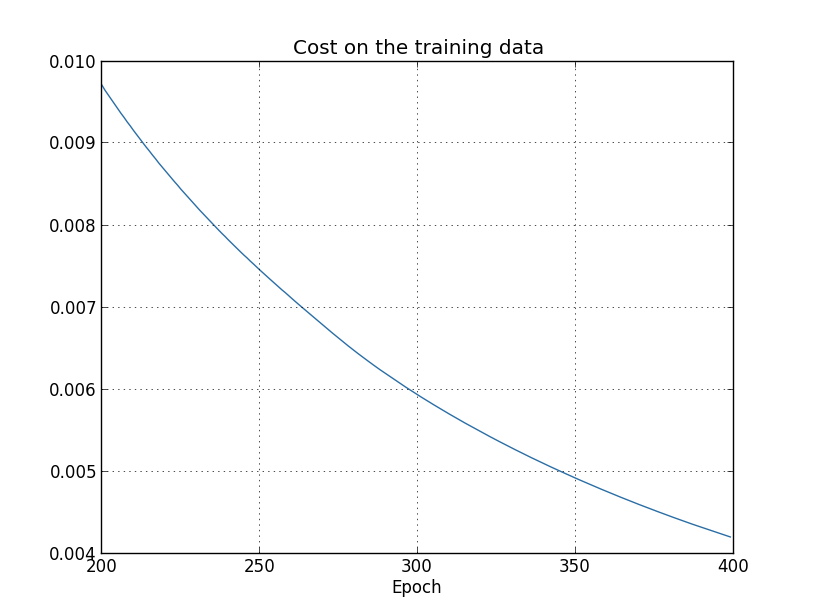
এটা উৎসাহজনক দেখাচ্ছে, cost-এ একটা মসৃণ হ্রাস দেখা যাচ্ছে, ঠিক যেমন আমরা আশা করি। খেয়াল করো আমি কেবল training epoch 200 থেকে 399 দেখিয়েছি। এটা শেখার পরের ধাপগুলোর একটা সুন্দর কাছ থেকে দেখা দৃশ্য দেয়, যেখানে — যেমন দেখব — মজার ঘটনা ঘটে।
এবার দেখি test data-র উপর classification accuracy সময়ের সাথে কীভাবে বদলায়:
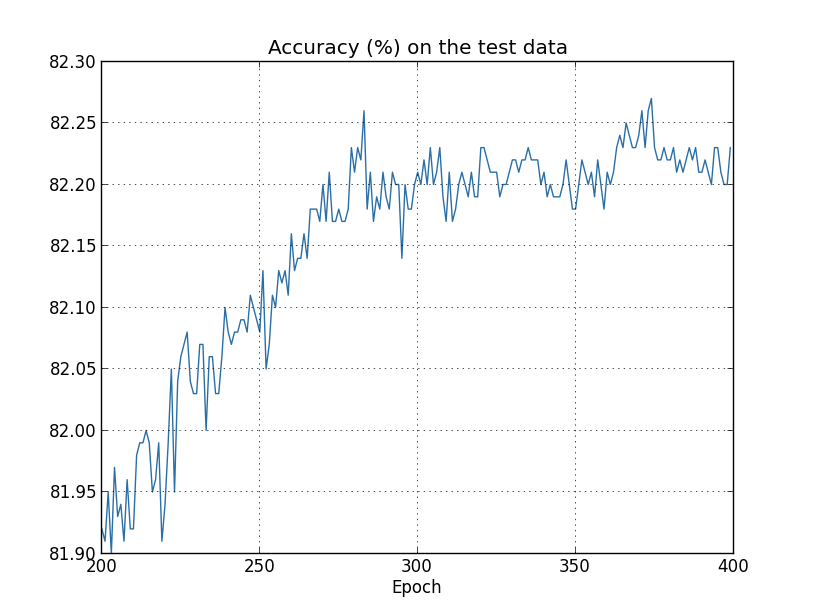
আবারও আমি বেশ খানিকটা zoom করেছি। প্রথম 200 epoch-এ (দেখানো হয়নি) accuracy ঠিক 82 শতাংশের নিচ পর্যন্ত ওঠে। তারপর শেখা ক্রমশ ধীর হয়। অবশেষে প্রায় epoch 280-এর কাছে classification accuracy প্রায় উন্নত হওয়া থামিয়ে দেয়। পরের epoch-গুলো কেবল epoch 280-এর accuracy মানের কাছে ছোট ছোট stochastic ওঠানামা দেখায়। এর সাথে আগের graph-এর তুলনা করো, যেখানে training data-র cost মসৃণভাবে কমতে থাকে। শুধু ওই cost দেখলে মনে হয় আমাদের model এখনও "ভালো" হচ্ছে। কিন্তু test accuracy-র ফল দেখায় যে উন্নতিটা একটা বিভ্রম। Fermi-র অপছন্দের model-এর মতোই, epoch 280-এর পর আমাদের network যা শেখে তা আর test data-তে generalize করে না। তাই এটা উপকারী শেখা নয়। আমরা বলি network epoch 280-এর পর overfitting বা overtraining করছে।
তুমি ভাবতে পারো এখানে সমস্যাটা কি এই যে আমি training data-র উপর cost দেখছি, যেখানে test data-র উপর classification accuracy দেখা উচিত। অন্যভাবে বললে, হয়তো সমস্যাটা আপেল-আর-কমলালেবুর তুলনা করা। যদি আমরা training data-র cost আর test data-র cost তুলনা করতাম — অর্থাৎ একই ধরনের পরিমাপ তুলনা করতাম — তাহলে কী হতো? কিংবা হয়তো আমরা training ও test data দুটোর উপরই classification accuracy তুলনা করতে পারতাম? আসলে যেভাবেই তুলনা করি না কেন মূলত একই ঘটনা দেখা যায়। তবে বিস্তারিত বদলায়। যেমন test data-র cost দেখি:
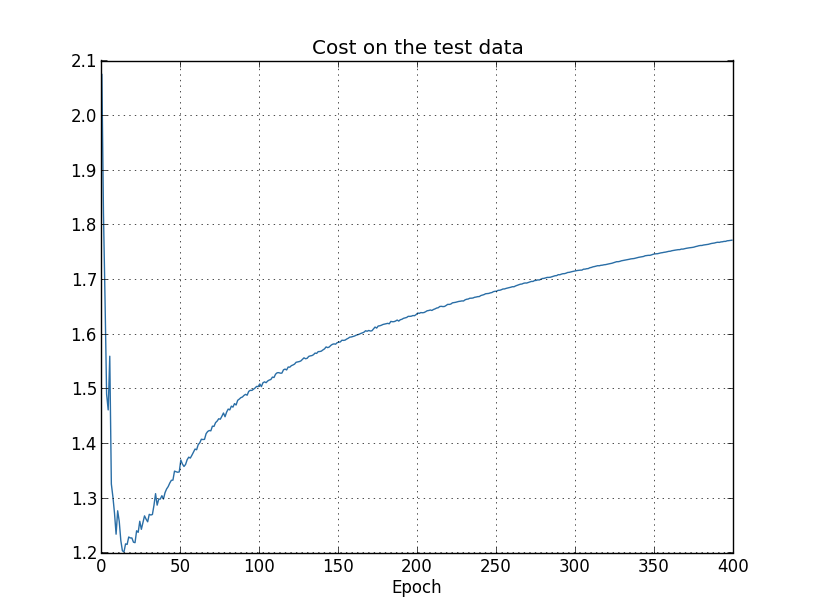
আমরা দেখি test data-র cost প্রায় epoch 15 পর্যন্ত উন্নত হয়, কিন্তু এরপর তা আসলে খারাপ হতে শুরু করে, যদিও training data-র cost আরও ভালো হতে থাকে। এটা আমাদের model overfitting করছে তার আরেকটা লক্ষণ। তবে এটা একটা ধাঁধা তৈরি করে — আমরা কি epoch 15 নাকি epoch 280-কে সেই বিন্দু ধরব যেখানে overfitting শেখায় প্রাধান্য পেতে শুরু করে? বাস্তব দৃষ্টিকোণ থেকে আমরা যা সত্যিই গুরুত্ব দিই তা হলো test data-র উপর classification accuracy উন্নত করা, যেখানে test data-র উপর cost classification accuracy-র একটা proxy মাত্র। তাই epoch 280-কেই সেই বিন্দু ধরা সবচেয়ে যৌক্তিক, যার পর আমাদের neural network-এ overfitting শেখায় প্রাধান্য পাচ্ছে।
Overfitting-এর আরেকটা লক্ষণ training data-র উপর classification accuracy-তে দেখা যায়:
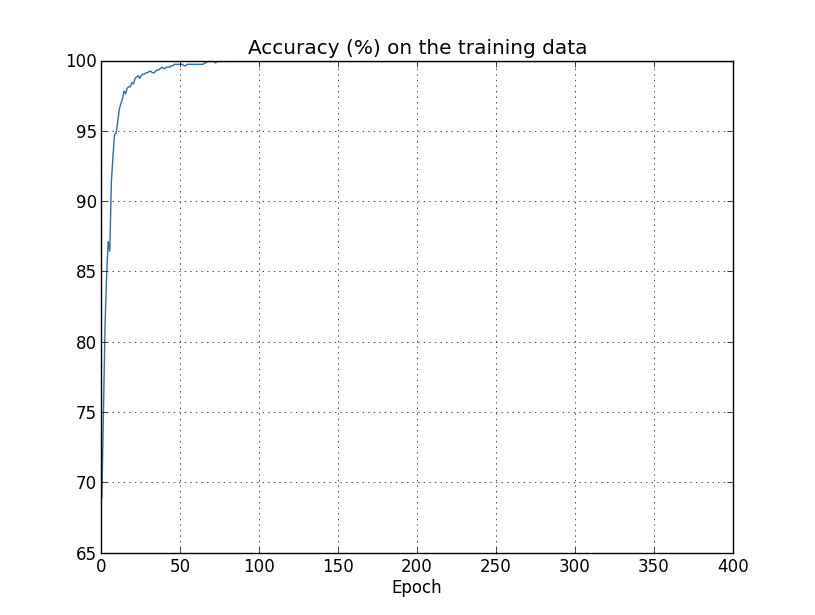
accuracy একেবারে শতাংশ পর্যন্ত ওঠে। অর্থাৎ আমাদের network সঠিকভাবে সব টি training ছবি classify করে! এদিকে আমাদের test accuracy কেবল শতাংশে আটকে যায়। তাই আমাদের network আসলে training set-এর বিশেষত্ব সম্পর্কে শিখছে, শুধু সাধারণভাবে সংখ্যা চেনা শিখছে না। এ যেন আমাদের network কেবল training set মুখস্থ করছে, সংখ্যা যথেষ্ট ভালো বোঝে না যে test set-এ generalize করতে পারে।
Overfitting neural network-এ একটা বড় সমস্যা। আধুনিক network-এ এটা বিশেষভাবে সত্যি, যেগুলোতে প্রায়ই খুব বেশি সংখ্যক weight ও bias থাকে। কার্যকরভাবে train করতে আমাদের একটা উপায় দরকার যা সনাক্ত করবে কখন overfitting ঘটছে, যাতে আমরা overtrain না করি। আর আমরা চাই overfitting-এর প্রভাব কমানোর কৌশল।
Overfitting সনাক্ত করার স্পষ্ট উপায় হলো উপরের পদ্ধতি — network train হওয়ার সাথে সাথে test data-র উপর accuracy-র হিসেব রাখা। test data-র accuracy আর উন্নত না হলে আমাদের train করা থামানো উচিত। অবশ্য কঠোরভাবে বললে, এটা অগত্যা overfitting-এর লক্ষণ নয়। এমন হতে পারে যে test ও training data দুটোর accuracy-ই একই সময়ে উন্নত হওয়া থামিয়ে দেয়। তবু এই কৌশল অবলম্বন করলে overfitting প্রতিরোধ হবে।
আসলে আমরা এই কৌশলের একটা ভিন্ন রূপ ব্যবহার করব। মনে করো MNIST data load করার সময় আমরা তিনটি data set load করি:
>>> import mnist_loader
>>> training_data, validation_data, test_data = \
... mnist_loader.load_data_wrapper()এতক্ষণ আমরা training_data ও test_data ব্যবহার করছিলাম, আর validation_data উপেক্ষা করছিলাম। validation_data-তে টি সংখ্যার ছবি আছে, যেগুলো MNIST training set-এর টি ও MNIST test set-এর টি ছবি থেকে আলাদা। Overfitting প্রতিরোধ করতে test_data ব্যবহারের বদলে আমরা validation_data ব্যবহার করব। এটা করতে আমরা উপরে test_data-র জন্য বর্ণিত প্রায় একই কৌশল ব্যবহার করব। অর্থাৎ প্রতিটি epoch-এর শেষে আমরা validation_data-র উপর classification accuracy হিসেব করব। একবার validation_data-র classification accuracy saturate হয়ে গেলে আমরা train করা থামাই। এই কৌশলকে বলা হয় early stopping। অবশ্য বাস্তবে accuracy কখন saturate হয়েছে তা সাথে সাথে জানব না। তার বদলে আমরা train করতে থাকি যতক্ষণ না নিশ্চিত হই যে accuracy saturate হয়েছে।
Overfitting প্রতিরোধ করতে test_data-র বদলে validation_data ব্যবহার করি কেন? আসলে এটা একটা আরও সাধারণ কৌশলের অংশ, যা হলো — train করার epoch সংখ্যা, learning rate, সেরা network architecture প্রভৃতি hyper-parameter-এর বিভিন্ন পরীক্ষামূলক পছন্দ মূল্যায়ন করতে validation_data ব্যবহার করা। এমন মূল্যায়ন ব্যবহার করে আমরা hyper-parameter-গুলোর ভালো মান খুঁজি ও সেট করি। আসলে, এখনও পর্যন্ত উল্লেখ না করলেও, এভাবেই আংশিকভাবে আমি এই বইয়ের আগের অংশের hyper-parameter পছন্দে পৌঁছেছি।
অবশ্য এটা কোনোভাবেই এই প্রশ্নের উত্তর দেয় না যে overfitting প্রতিরোধ করতে আমরা test_data-র বদলে validation_data কেন ব্যবহার করছি। বরং এটাকে একটা আরও সাধারণ প্রশ্ন দিয়ে প্রতিস্থাপন করে — ভালো hyper-parameter সেট করতে আমরা test_data-র বদলে validation_data কেন ব্যবহার করছি? কেন তা বুঝতে ভাবো — hyper-parameter সেট করার সময় আমরা সম্ভবত তাদের অনেক ভিন্ন পছন্দ চেষ্টা করব। test_data-র মূল্যায়নের ভিত্তিতে hyper-parameter সেট করলে সম্ভব যে আমরা test_data-তে আমাদের hyper-parameter overfit করে ফেলব। অর্থাৎ আমরা এমন hyper-parameter পেতে পারি যা test_data-র বিশেষ বিশেষত্বের সাথে fit করে, কিন্তু যেখানে network-এর performance অন্য data set-এ generalize করবে না। validation_data দিয়ে hyper-parameter বের করে আমরা তা থেকে রক্ষা পাই। তারপর একবার আমাদের কাঙ্ক্ষিত hyper-parameter পেয়ে গেলে আমরা test_data দিয়ে accuracy-র একটা চূড়ান্ত মূল্যায়ন করি। এটা আমাদের আস্থা দেয় যে test_data-র উপর আমাদের ফল আমাদের neural network কতটা ভালো generalize করে তার একটা সত্যিকার পরিমাপ। অন্যভাবে বললে, validation data-কে তুমি এক ধরনের training data হিসেবে ভাবতে পারো যা আমাদের ভালো hyper-parameter শিখতে সাহায্য করে। ভালো hyper-parameter খোঁজার এই পদ্ধতিকে কখনও কখনও hold out method বলা হয়, যেহেতু validation_data-কে training_data থেকে আলাদা বা "hold out" করে রাখা হয়।
এখন বাস্তবে, test_data-র উপর performance মূল্যায়নের পরও আমরা মত বদলে আরেকটা পদ্ধতি — হয়তো একটা ভিন্ন network architecture — চেষ্টা করতে চাইতে পারি, যাতে নতুন একগুচ্ছ hyper-parameter খোঁজা জড়িত। আমরা তা করলে কি আমরা test_data-তেও overfit করে ফেলার বিপদে পড়ব না? আমাদের কি data set-এর সম্ভাব্য অসীম পশ্চাদপসরণ দরকার, যাতে আমরা নিশ্চিত হতে পারি যে আমাদের ফল generalize করবে? এই উদ্বেগ সম্পূর্ণরূপে সমাধান করা একটা গভীর ও কঠিন সমস্যা। তবে আমাদের ব্যবহারিক উদ্দেশ্যে আমরা এই প্রশ্ন নিয়ে খুব বেশি দুশ্চিন্তা করব না। তার বদলে আমরা উপরে বর্ণিত মৌলিক hold out method ব্যবহার করে এগিয়ে যাব।
এতক্ষণ আমরা কেবল 1,000 training ছবি ব্যবহার করার সময় overfitting দেখছিলাম। 50,000 ছবির পুরো training set ব্যবহার করলে কী হয়? আমরা বাকি সব parameter একই রাখব (30 hidden neuron, learning rate 0.5, 10 mini-batch size), কিন্তু সব 50,000 ছবি দিয়ে 30 epoch ধরে train করব। আগের graph-গুলোর সাথে ফল আরও সরাসরি তুলনাযোগ্য করতে এখানে আমি validation data-র বদলে test data ব্যবহার করেছি।
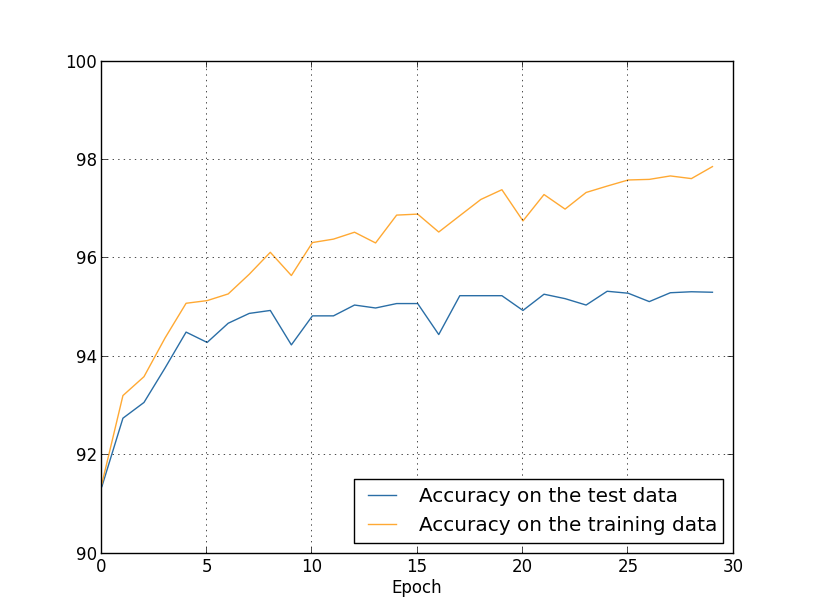
দেখতে পাচ্ছ, 1,000 training example ব্যবহারের তুলনায় test ও training data-র accuracy অনেক বেশি কাছাকাছি থাকে। বিশেষত, training data-র উপর সেরা classification accuracy শতাংশ test data-র শতাংশের চেয়ে কেবল শতাংশ বেশি। এর তুলনায় আগে আমাদের শতাংশ ব্যবধান ছিল! Overfitting এখনও ঘটছে, তবে অনেক কমেছে। আমাদের network training data থেকে test data-তে অনেক ভালো generalize করছে। সাধারণভাবে, overfitting কমানোর সেরা উপায়গুলোর একটা হলো training data-র আকার বাড়ানো। যথেষ্ট training data থাকলে খুব বড় network-এর পক্ষেও overfit করা কঠিন। দুর্ভাগ্যবশত training data ব্যয়বহুল বা সংগ্রহ করা কঠিন হতে পারে, তাই এটা সবসময় একটা ব্যবহারিক বিকল্প নয়।
Regularization
Training data-র পরিমাণ বাড়ানো overfitting কমানোর একটা উপায়। overfitting যতটা ঘটে তা কমানোর কি আর কোনো উপায় আছে? একটা সম্ভাব্য পদ্ধতি হলো আমাদের network-এর আকার কমানো। তবে বড় network ছোট network-এর চেয়ে আরও শক্তিশালী হওয়ার সম্ভাবনা রাখে, তাই এটা এমন একটা বিকল্প যা আমরা অনিচ্ছাসত্ত্বেই কেবল গ্রহণ করব।
সৌভাগ্যবশত আরও কিছু কৌশল আছে যা একটা নির্দিষ্ট network ও নির্দিষ্ট training data থাকলেও overfitting কমাতে পারে। এগুলোকে regularization কৌশল বলা হয়। এই section-এ আমি সবচেয়ে বেশি ব্যবহৃত regularization কৌশলগুলোর একটা বর্ণনা করব, যা কখনও কখনও weight decay বা L2 regularization নামে পরিচিত। L2 regularization-এর ধারণা হলো cost function-এ একটা বাড়তি পদ যোগ করা, যাকে বলে regularization term। এই হলো regularized cross-entropy:
প্রথম পদটি কেবল cross-entropy-র চিরাচরিত রাশি। কিন্তু আমরা একটা দ্বিতীয় পদ যোগ করেছি, যথা network-এর সব weight-এর বর্গের যোগফল। এটাকে একটা factor দিয়ে স্কেল করা হয়, যেখানে হলো regularization parameter, আর যথারীতি আমাদের training set-এর আকার। আমি পরে আলোচনা করব কীভাবে বেছে নেওয়া হয়। এটাও উল্লেখযোগ্য যে regularization term bias-গুলো অন্তর্ভুক্ত করে না। এ নিয়েও পরে ফিরব।
অবশ্যই অন্য cost function-ও regularize করা সম্ভব, যেমন quadratic cost। এটা একইভাবে করা যায়:
দুই ক্ষেত্রেই regularized cost function লিখতে পারি:
যেখানে হলো মূল, unregularized cost function।
স্বজ্ঞাতভাবে, regularization-এর প্রভাব হলো — অন্য সব কিছু সমান থাকলে network-কে ছোট weight শিখতে পছন্দ করানো। বড় weight কেবল তখনই অনুমোদিত হবে যদি তা cost function-এর প্রথম অংশকে যথেষ্ট উন্নত করে। অন্যভাবে বললে, regularization-কে ছোট weight খোঁজা ও মূল cost function minimize করার মধ্যে একটা আপস হিসেবে দেখা যায়। এই আপসের দুই উপাদানের আপেক্ষিক গুরুত্ব -এর মানের উপর নির্ভর করে: ছোট হলে আমরা মূল cost function minimize করতে পছন্দ করি, কিন্তু বড় হলে আমরা ছোট weight পছন্দ করি।
এখন এমন একটা আপস কেন overfitting কমাতে সাহায্য করবে তা মোটেই স্পষ্ট নয়! কিন্তু দেখা যায় এটা সত্যিই করে। কেন তা সাহায্য করে সেই প্রশ্ন আমরা পরের section-এ সামলাব। তবে আগে একটা উদাহরণের মধ্য দিয়ে দেখাই যে regularization সত্যিই overfitting কমায়।
এমন একটা উদাহরণ গড়তে আমাদের প্রথমে বের করতে হবে একটা regularized neural network-এ আমাদের stochastic gradient descent learning algorithm কীভাবে প্রয়োগ করব। বিশেষত আমাদের জানতে হবে network-এর সব weight ও bias-এর জন্য partial derivative ও কীভাবে হিসেব করব। Equation (87)-এর partial derivative নিলে পাই:
ও পদগুলো গত অধ্যায়ে বর্ণিত backpropagation দিয়ে হিসেব করা যায়। তাই আমরা দেখি যে regularized cost function-এর gradient হিসেব করা সহজ: যথারীতি backpropagation ব্যবহার করো, তারপর সব weight পদের partial derivative-এ যোগ করো। bias-এর সাপেক্ষে partial derivative অপরিবর্তিত, তাই bias-এর জন্য gradient descent learning rule চিরাচরিত নিয়ম থেকে বদলায় না:
weight-এর জন্য learning rule দাঁড়ায়:
এটা চিরাচরিত gradient descent learning rule-এর ঠিক সমান, কেবল আমরা প্রথমে weight -কে একটা factor দিয়ে পুনরায় স্কেল করি। এই পুনঃস্কেলিংকে কখনও কখনও weight decay বলা হয়, যেহেতু এটা weight-গুলো ছোট করে। প্রথম দর্শনে মনে হয় এর অর্থ weight-গুলো অপ্রতিরোধ্যভাবে শূন্যের দিকে চালিত হচ্ছে। কিন্তু তা ঠিক নয়, কারণ অন্য পদটি weight বাড়াতে পারে, যদি তা করায় unregularized cost function কমে।
ঠিক আছে, এই হলো gradient descent কীভাবে কাজ করে। Stochastic gradient descent সম্পর্কে কী বলা যায়? unregularized stochastic gradient descent-এর মতোই, আমরা টি training example-এর একটা mini-batch-এর উপর গড় নিয়ে অনুমান করতে পারি। তাই stochastic gradient descent-এর জন্য regularized learning rule দাঁড়ায় (cf. Equation (20)):
যেখানে যোগফল mini-batch-এর training example -গুলোর উপর, আর হলো প্রতিটি training example-এর (unregularized) cost। এটা stochastic gradient descent-এর চিরাচরিত নিয়মের ঠিক সমান, কেবল weight decay factor ছাড়া। অবশেষে, সম্পূর্ণতার জন্য, bias-এর জন্য regularized learning rule বলি। এটা অবশ্যই unregularized ক্ষেত্রের ঠিক সমান (cf. Equation (21)):
যেখানে যোগফল mini-batch-এর training example -গুলোর উপর।
দেখা যাক regularization আমাদের neural network-এর performance কীভাবে বদলায়। আমরা 30 hidden neuron, mini-batch size, learning rate ও cross-entropy cost function সহ একটা network ব্যবহার করব। তবে এবার আমরা regularization parameter ব্যবহার করব। খেয়াল করো code-এ আমরা variable-এর নাম lmbda ব্যবহার করি, কারণ Python-এ lambda একটা reserved word যার একটা অসংশ্লিষ্ট অর্থ আছে। আগের, unregularized ফলের সাথে আরও সরাসরি তুলনাযোগ্য করতে আমি এখানেও আবার test_data ব্যবহার করেছি, validation_data নয়।
>>> import mnist_loader
>>> training_data, validation_data, test_data = \
... mnist_loader.load_data_wrapper()
>>> import network2
>>> net = network2.Network([784, 30, 10], cost=network2.CrossEntropyCost)
>>> net.large_weight_initializer()
>>> net.SGD(training_data[:1000], 400, 10, 0.5,
... evaluation_data=test_data, lmbda = 0.1,
... monitor_evaluation_cost=True, monitor_evaluation_accuracy=True,
... monitor_training_cost=True, monitor_training_accuracy=True)training data-র cost পুরো সময় জুড়ে কমে, অনেকটা আগের unregularized ক্ষেত্রের মতোই:
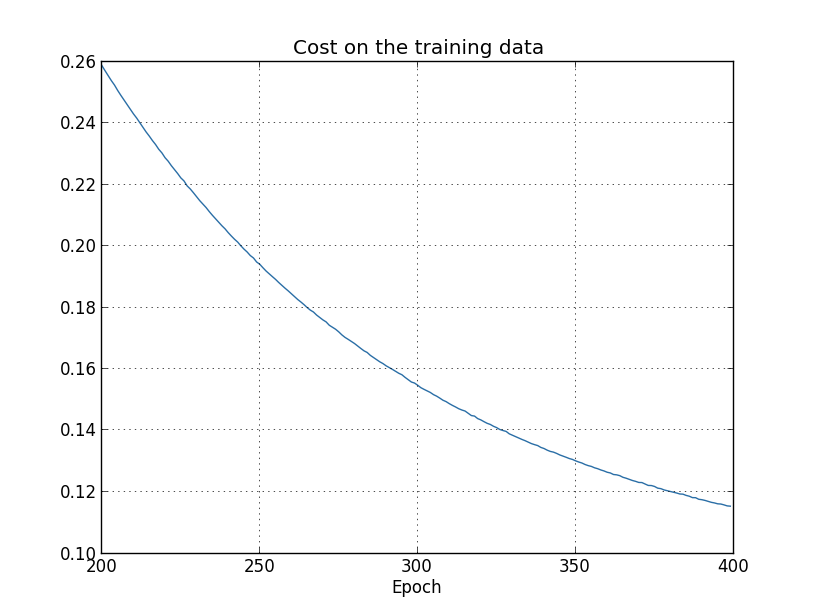
কিন্তু এবার test_data-র accuracy পুরো 400 epoch জুড়ে বাড়তে থাকে:
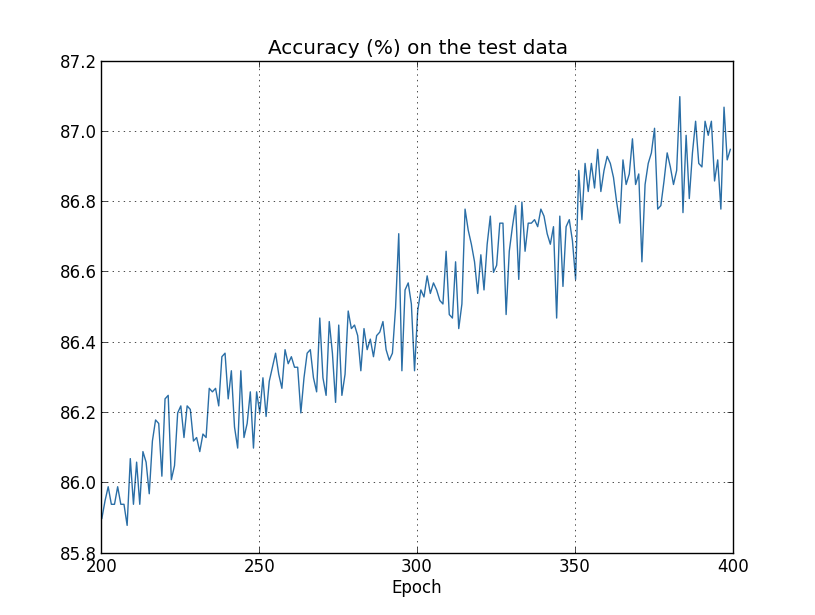
স্পষ্টতই regularization ব্যবহার overfitting দমন করেছে। তাছাড়া accuracy উল্লেখযোগ্যভাবে বেশি, সর্বোচ্চ classification accuracy শতাংশ, যেখানে unregularized ক্ষেত্রে সর্বোচ্চ শতাংশ পেয়েছিলাম। আসলে 400 epoch-এর পরও train করতে থাকলে প্রায় নিশ্চিতভাবে আমরা যথেষ্ট ভালো ফল পেতাম। মনে হচ্ছে অভিজ্ঞতাগতভাবে regularization আমাদের network-কে আরও ভালো generalize করাচ্ছে, এবং overfitting-এর প্রভাব যথেষ্ট কমাচ্ছে।
শুধু 1,000 training ছবি থাকার কৃত্রিম পরিবেশ থেকে বেরিয়ে 50,000 ছবির পুরো training set-এ ফিরলে কী হয়? অবশ্যই আমরা ইতিমধ্যেই দেখেছি যে পুরো 50,000 ছবি থাকলে overfitting অনেক কম সমস্যা। regularization কি আর কোনো সাহায্য করে? আমরা hyper-parameter আগের মতোই রাখব — 30 epoch, learning rate 0.5, 10 mini-batch size। তবে আমাদের regularization parameter পরিবর্তন করতে হবে। কারণ training set-এর আকার পরিবর্তিত হয়েছে থেকে -এ, আর এটা weight decay factor বদলে দেয়। আমরা যদি ব্যবহার করতে থাকতাম তাহলে অনেক কম weight decay হতো, ফলে অনেক কম regularization প্রভাব। আমরা -এ বদলে তা পুষিয়ে দিই।
আমাদের network train করি, আগে weight পুনরায় initialize করার জন্য থেমে:
>>> net.large_weight_initializer()
>>> net.SGD(training_data, 30, 10, 0.5,
... evaluation_data=test_data, lmbda = 5.0,
... monitor_evaluation_accuracy=True, monitor_training_accuracy=True)আমরা যে ফল পাই:
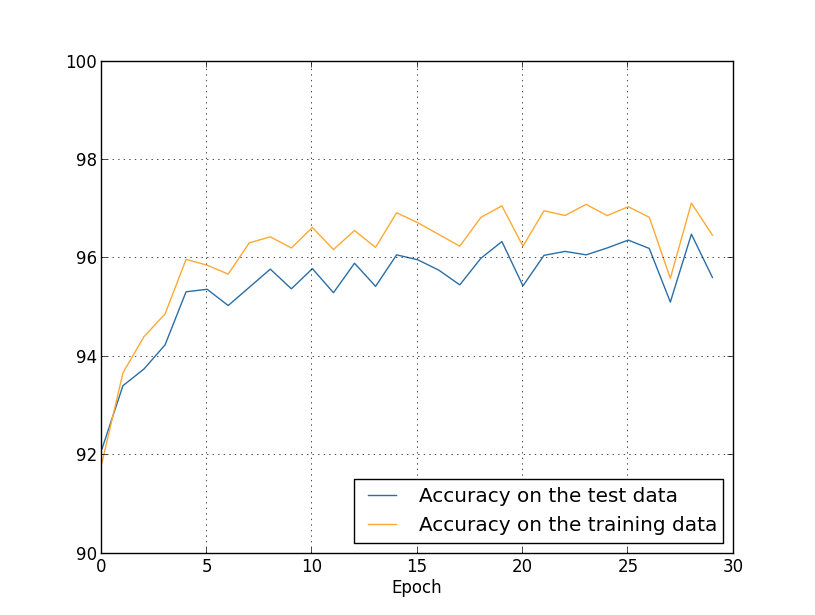
এখানে অনেক সুসংবাদ। প্রথমত, test data-র উপর আমাদের classification accuracy বেড়েছে, unregularized চালানোর সময়ের শতাংশ থেকে শতাংশে। এটা একটা বড় উন্নতি। দ্বিতীয়ত, আমরা দেখি training ও test data-র ফলের মধ্যে ব্যবধান আগের চেয়ে অনেক সংকীর্ণ, এক শতাংশের নিচে। এটা এখনও একটা উল্লেখযোগ্য ব্যবধান, তবে আমরা স্পষ্টতই overfitting কমানোয় যথেষ্ট অগ্রগতি করেছি।
অবশেষে দেখি 100 hidden neuron ও regularization parameter ব্যবহার করলে আমরা কত test classification accuracy পাই। আমি এখানে overfitting-এর বিস্তারিত বিশ্লেষণ করব না, এটা নিছক মজার জন্য — আমাদের নতুন কৌশল cross-entropy cost function ও L2 regularization ব্যবহার করে কত উঁচু accuracy পেতে পারি তা দেখতে।
>>> net = network2.Network([784, 100, 10], cost=network2.CrossEntropyCost)
>>> net.large_weight_initializer()
>>> net.SGD(training_data, 30, 10, 0.5, lmbda=5.0,
... evaluation_data=validation_data,
... monitor_evaluation_accuracy=True)চূড়ান্ত ফল হলো validation data-র উপর শতাংশ classification accuracy। 30 hidden neuron-এর ক্ষেত্র থেকে এটা একটা বড় লাফ। আসলে আরেকটু tune করে, ও -তে 60 epoch ধরে চালালে আমরা শতাংশের বাধা ভেঙে validation data-র উপর শতাংশ classification accuracy অর্জন করি। মাত্র 152 লাইন code-এর জন্য খারাপ নয়!
আমি regularization-কে overfitting কমানো ও classification accuracy বাড়ানোর একটা উপায় হিসেবে বর্ণনা করেছি। আসলে এটাই একমাত্র সুবিধা নয়। অভিজ্ঞতাগতভাবে, আমাদের MNIST network-গুলো বিভিন্ন (random) weight initialization দিয়ে একাধিকবার চালানোর সময় আমি দেখেছি যে unregularized চালানোগুলো মাঝে মাঝে "আটকে" যায়, আপাতদৃষ্টিতে cost function-এর local minima-তে ধরা পড়ে। ফলে ভিন্ন ভিন্ন চালানো কখনও কখনও বেশ ভিন্ন ফল দেয়। তুলনায়, regularized চালানোগুলো অনেক বেশি সহজে পুনরুৎপাদনযোগ্য ফল দিয়েছে।
এটা কেন ঘটছে? Heuristic-ভাবে, cost function unregularized হলে weight vector-এর দৈর্ঘ্য বাড়ার সম্ভাবনা থাকে, অন্য সব কিছু সমান থাকলে। সময়ের সাথে এটা weight vector-কে সত্যিই খুব বড় করে তুলতে পারে। এতে weight vector মোটামুটি একই দিকে নির্দেশ করে আটকে যেতে পারে, কারণ দৈর্ঘ্য লম্বা হলে gradient descent-এর কারণে ঘটা পরিবর্তন কেবল দিকের সামান্য পরিবর্তন করে। আমার বিশ্বাস এই ঘটনা আমাদের learning algorithm-এর পক্ষে weight space ঠিকমতো অন্বেষণ করা কঠিন করে তোলে, এবং ফলে cost function-এর ভালো minima খুঁজে পাওয়া কঠিন করে।
Regularization কেন overfitting কমাতে সাহায্য করে?
আমরা অভিজ্ঞতাগতভাবে দেখেছি যে regularization overfitting কমাতে সাহায্য করে। এটা উৎসাহজনক, কিন্তু দুর্ভাগ্যবশত regularization কেন সাহায্য করে তা স্পষ্ট নয়! কী ঘটছে তা ব্যাখ্যা করতে মানুষ একটা standard গল্প বলে, যা মোটামুটি এরকম: ছোট weight কোনো অর্থে কম জটিল, তাই data-র জন্য একটা সরল ও আরও শক্তিশালী ব্যাখ্যা দেয়, তাই সেগুলোকে অগ্রাধিকার দেওয়া উচিত। তবে এটা বেশ সংক্ষিপ্ত একটা গল্প, এবং এতে এমন কয়েকটা উপাদান আছে যা হয়তো সন্দেহজনক বা রহস্যময় মনে হয়। গল্পটা খুলে দেখি ও সমালোচনামূলকভাবে পরীক্ষা করি। তা করতে ধরো আমাদের কাছে একটা সরল data set আছে যার জন্য আমরা একটা model বানাতে চাই:
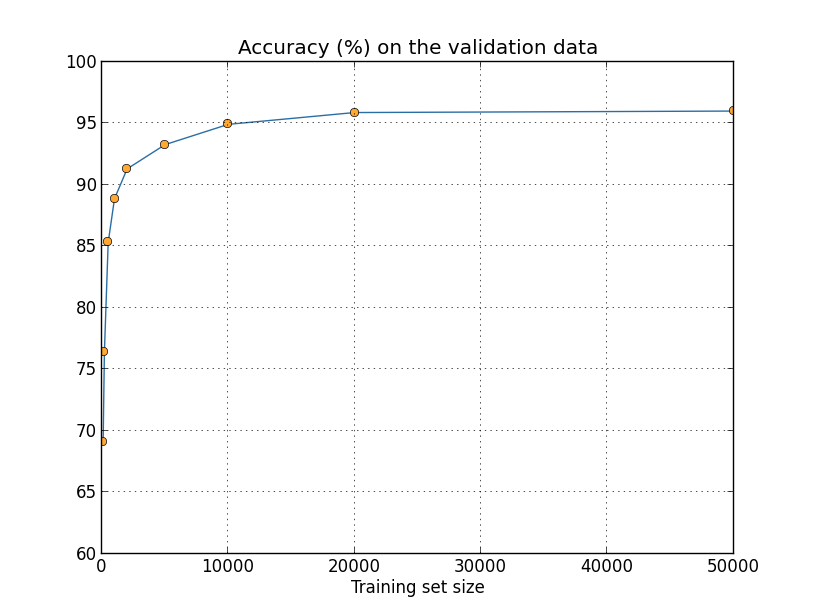
অন্তর্নিহিতভাবে আমরা এখানে কোনো বাস্তব-জগতের ঘটনা অধ্যয়ন করছি, যেখানে ও বাস্তব-জগতের data উপস্থাপন করছে। আমাদের লক্ষ্য একটা model বানানো যা আমাদের -এর function হিসেবে ভবিষ্যদ্বাণী করতে দেয়। আমরা এমন একটা model বানাতে neural network চেষ্টা করতে পারতাম, কিন্তু আমি আরও সরল কিছু করব: আমি -কে -এর একটা polynomial হিসেবে model করার চেষ্টা করব। neural net ব্যবহারের বদলে এটা করছি কারণ polynomial ব্যবহার বিষয়টাকে বিশেষভাবে স্বচ্ছ করবে। একবার polynomial ক্ষেত্রটা বুঝে নিলে আমরা neural network-এ অনুবাদ করব। এখন উপরের graph-এ দশটি point আছে, অর্থাৎ আমরা একটা অনন্য th-order polynomial খুঁজে পেতে পারি যা data-র সাথে হুবহু fit করে। এই হলো ওই polynomial-এর graph (আমি coefficient-গুলো স্পষ্টভাবে দেখাব না, যদিও Numpy-র polyfit-এর মতো routine দিয়ে সেগুলো সহজে খুঁজে পাওয়া যায়)।
সেটা একটা হুবহু fit দেয়। কিন্তু আমরা linear model ব্যবহার করেও একটা ভালো fit পেতে পারি।
এই দুটোর মধ্যে কোনটা ভালো model? কোনটার সত্যি হওয়ার সম্ভাবনা বেশি? আর কোন model একই অন্তর্নিহিত বাস্তব-জগতের ঘটনার অন্যান্য উদাহরণে ভালো generalize করার সম্ভাবনা বেশি?
এগুলো কঠিন প্রশ্ন। আসলে অন্তর্নিহিত বাস্তব-জগতের ঘটনা সম্পর্কে আরও অনেক তথ্য ছাড়া উপরের কোনো প্রশ্নের উত্তরই আমরা নিশ্চিতভাবে নির্ধারণ করতে পারি না। তবে দুটো সম্ভাবনা বিবেচনা করি: (1) th order polynomial-ই আসলে সেই model যা সত্যিকার অর্থে বাস্তব-জগতের ঘটনা বর্ণনা করে, তাই model নিখুঁতভাবে generalize করবে; (2) সঠিক model হলো , কিন্তু — ধরো measurement error-এর কারণে — সামান্য বাড়তি noise আছে, আর সে জন্যই model একটা হুবহু fit নয়।
এই দুটো সম্ভাবনার কোনটা সঠিক তা a priori বলা সম্ভব নয়। (বা, আসলে, কোনো তৃতীয় সম্ভাবনা সত্যি কিনা।) যুক্তিগতভাবে যেকোনোটাই সত্যি হতে পারে। আর পার্থক্যটা তুচ্ছ নয়। সত্যি যে দেওয়া data-তে দুটো model-এর মধ্যে সামান্যই পার্থক্য আছে। কিন্তু ধরো আমরা উপরের graph-এ দেখানো যেকোনো মানের চেয়ে অনেক বড় -এর সংশ্লিষ্ট -এর মান ভবিষ্যদ্বাণী করতে চাই। তা করতে গেলে দুটো model-এর ভবিষ্যদ্বাণীর মধ্যে নাটকীয় পার্থক্য থাকবে, কারণ th order polynomial model-এ পদটি প্রাধান্য পেতে শুরু করবে, যেখানে linear model, well, linear-ই থাকবে।
একটা দৃষ্টিভঙ্গি হলো বলা যে বিজ্ঞানে আমাদের সরল ব্যাখ্যার সাথে যাওয়া উচিত, যতক্ষণ না বাধ্য হই অন্যথা করতে। যখন আমরা একটা সরল model পাই যা অনেক data point ব্যাখ্যা করে বলে মনে হয়, তখন আমরা "ইউরেকা!" বলে চিৎকার করতে প্রলুব্ধ হই। কারণ মনে হয় না যে একটা সরল ব্যাখ্যা নিছক কাকতালীয়ভাবে ঘটবে। বরং আমরা সন্দেহ করি model অবশ্যই ঘটনা সম্পর্কে কোনো অন্তর্নিহিত সত্য প্রকাশ করছে। এই ক্ষেত্রে model -এর চেয়ে অনেক সরল মনে হয়। ওই সরলতা যদি কাকতালীয়ভাবে ঘটত তবে অবাক হতাম, তাই আমরা সন্দেহ করি কোনো অন্তর্নিহিত সত্য প্রকাশ করছে। এই দৃষ্টিভঙ্গিতে 9th order model আসলে কেবল local noise-এর প্রভাব শিখছে। তাই এই নির্দিষ্ট data point-গুলোর জন্য 9th order model নিখুঁতভাবে কাজ করলেও model অন্য data point-এ generalize করতে ব্যর্থ হবে, এবং noisy linear model-এর বেশি ভবিষ্যদ্বাণীমূলক ক্ষমতা থাকবে।
এই দৃষ্টিভঙ্গি neural network-এর জন্য কী বোঝায় তা দেখি। ধরো আমাদের network-এর বেশিরভাগ weight ছোট, যেমন একটা regularized network-এ ঘটে। weight ছোট হওয়ার অর্থ এখানে-সেখানে কয়েকটা random input বদলালে network-এর আচরণ খুব বেশি বদলাবে না। এটা একটা regularized network-এর পক্ষে data-র local noise-এর প্রভাব শেখা কঠিন করে তোলে। একে এমন একটা উপায় হিসেবে ভাবো যা প্রমাণের একক টুকরোগুলোকে network-এর output-এ খুব বেশি গুরুত্বপূর্ণ হতে দেয় না। তার বদলে একটা regularized network এমন ধরনের প্রমাণে সাড়া দিতে শেখে যা training set জুড়ে প্রায়ই দেখা যায়। তুলনায়, বড় weight-যুক্ত network input-এর ছোট পরিবর্তনে তার আচরণ বেশ খানিকটা বদলে ফেলতে পারে। তাই একটা unregularized network বড় weight ব্যবহার করে একটা জটিল model শিখতে পারে যা training data-র noise সম্পর্কে অনেক তথ্য বহন করে। সংক্ষেপে, regularized network training data-তে প্রায়ই দেখা pattern-এর ভিত্তিতে অপেক্ষাকৃত সরল model গড়তে বাধ্য, এবং training data-র noise-এর বিশেষত্ব শেখায় প্রতিরোধী। আশা হলো এটা আমাদের network-কে হাতের কাছের ঘটনা সম্পর্কে প্রকৃত শেখায় বাধ্য করবে, এবং যা শেখে তা থেকে আরও ভালো generalize করবে।
তা সত্ত্বেও, সরল ব্যাখ্যা পছন্দ করার এই ধারণা তোমাকে nervous করা উচিত। মানুষ কখনও কখনও এই ধারণাকে "Occam's Razor" বলে উল্লেখ করে, এবং একে এমনভাবে উৎসাহের সাথে প্রয়োগ করে যেন এর কোনো সাধারণ বৈজ্ঞানিক নীতির মর্যাদা আছে। কিন্তু অবশ্যই এটা কোনো সাধারণ বৈজ্ঞানিক নীতি নয়। জটিল ব্যাখ্যার চেয়ে সরল ব্যাখ্যা পছন্দ করার কোনো a priori যৌক্তিক কারণ নেই। আসলে কখনও কখনও আরও জটিল ব্যাখ্যাটাই সঠিক প্রমাণিত হয়।
আরও জটিল ব্যাখ্যা সঠিক প্রমাণিত হয়েছে এমন দুটো উদাহরণ বর্ণনা করি। ১৯৪০-এর দশকে পদার্থবিদ Marcel Schein প্রকৃতির একটা নতুন কণা আবিষ্কারের ঘোষণা দিয়েছিলেন। তিনি যে কোম্পানিতে কাজ করতেন, General Electric, উচ্ছ্বসিত হয়ে আবিষ্কারটি ব্যাপকভাবে প্রচার করেছিল। কিন্তু পদার্থবিদ Hans Bethe সন্দিহান ছিলেন। Bethe Schein-এর কাছে গিয়ে তাঁর নতুন কণার track দেখানো plate-গুলো দেখলেন। Schein একটার পর একটা plate দেখালেন, কিন্তু প্রতিটি plate-এ Bethe এমন কোনো সমস্যা চিহ্নিত করলেন যা ইঙ্গিত করে data বাতিল করা উচিত। অবশেষে Schein এমন একটা plate দেখালেন যা ভালো দেখাচ্ছিল। Bethe বললেন এটা হয়তো নিছক একটা statistical দৈবমাত্র। Schein: "হ্যাঁ, কিন্তু তোমার নিজের সূত্র অনুযায়ীও এটা statistics হওয়ার সম্ভাবনা পাঁচে এক।" Bethe: "কিন্তু আমরা ইতিমধ্যেই পাঁচটা plate দেখেছি।" শেষে Schein বললেন: "কিন্তু আমার plate-গুলোতে, প্রতিটা ভালো plate, প্রতিটা ভালো ছবি তুমি একটা করে ভিন্ন তত্ত্ব দিয়ে ব্যাখ্যা করো, যেখানে আমার একটা hypothesis সব plate ব্যাখ্যা করে — যে সেগুলো [নতুন কণা]।" Bethe জবাব দিলেন: "তোমার ও আমার ব্যাখ্যার একমাত্র পার্থক্য হলো তোমারটা ভুল আর আমার সবগুলো সঠিক। তোমার একক ব্যাখ্যা ভুল, আর আমার একাধিক ব্যাখ্যা সব সঠিক।" পরবর্তী কাজ নিশ্চিত করল যে প্রকৃতি Bethe-র সাথে একমত, এবং Schein-এর কণা আর নেই।
দ্বিতীয় উদাহরণ হিসেবে, ১৮৫৯ সালে জ্যোতির্বিদ Urbain Le Verrier লক্ষ করলেন যে Mercury গ্রহের কক্ষপথের আকৃতি ঠিক সেটা নয় যা Newton-এর মহাকর্ষ তত্ত্ব বলে। এটা ছিল Newton-এর তত্ত্ব থেকে একটা ক্ষুদ্রাতিক্ষুদ্র বিচ্যুতি, এবং তখন প্রস্তাবিত কয়েকটা ব্যাখ্যা মূলত এই বলে দাঁড়াল যে Newton-এর তত্ত্ব মোটামুটি সঠিক, কেবল একটা ক্ষুদ্র পরিবর্তন দরকার। ১৯১৬ সালে Einstein দেখালেন যে বিচ্যুতিটা তাঁর general theory of relativity দিয়ে খুব ভালোভাবে ব্যাখ্যা করা যায় — Newtonian মহাকর্ষের থেকে আমূল ভিন্ন একটা তত্ত্ব, যা অনেক বেশি জটিল গণিতের উপর ভিত্তি করে। ওই বাড়তি জটিলতা সত্ত্বেও আজ গৃহীত যে Einstein-এর ব্যাখ্যা সঠিক, এবং Newtonian মহাকর্ষ, এমনকি তার পরিবর্তিত রূপেও, ভুল। এটা আংশিকভাবে কারণ আমরা এখন জানি যে Einstein-এর তত্ত্ব আরও অনেক ঘটনা ব্যাখ্যা করে যেগুলোতে Newton-এর তত্ত্ব হিমশিম খায়। তাছাড়া, আরও চমকপ্রদভাবে, Einstein-এর তত্ত্ব এমন কয়েকটা ঘটনা সঠিকভাবে ভবিষ্যদ্বাণী করে যেগুলো Newtonian মহাকর্ষ আদৌ ভবিষ্যদ্বাণী করে না। কিন্তু এই চমকপ্রদ গুণগুলো প্রথম দিকে পুরোপুরি স্পষ্ট ছিল না। কেউ যদি কেবল সরলতার ভিত্তিতে বিচার করত, তবে Newton-এর তত্ত্বের কোনো পরিবর্তিত রূপ যুক্তিযুক্তভাবে আরও আকর্ষণীয় হতো।
এই গল্পগুলো থেকে তিনটি শিক্ষা নেওয়ার আছে। প্রথমত, দুটো ব্যাখ্যার কোনটা সত্যিকার অর্থে "সরল" তা নির্ধারণ করা বেশ সূক্ষ্ম একটা ব্যাপার হতে পারে। দ্বিতীয়ত, এমন বিচার করতে পারলেও, সরলতা এমন একটা পথনির্দেশক যা অত্যন্ত সতর্কতার সাথে ব্যবহার করতে হবে! তৃতীয়ত, একটা model-এর প্রকৃত পরীক্ষা সরলতা নয়, বরং নতুন আচরণের নতুন পরিসরে নতুন ঘটনা ভবিষ্যদ্বাণীতে এটা কতটা ভালো করে।
তা সত্ত্বেও, এবং সতর্কতার প্রয়োজন মনে রেখে, এটা একটা অভিজ্ঞতাগত সত্য যে regularized neural network সাধারণত unregularized network-এর চেয়ে ভালো generalize করে। তাই বইয়ের বাকি অংশে আমরা প্রায়ই regularization ব্যবহার করব। উপরের গল্পগুলো আমি কেবল এটা বোঝাতে অন্তর্ভুক্ত করেছি যে regularization কেন network-কে generalize করতে সাহায্য করে তার একটা সম্পূর্ণ বিশ্বাসযোগ্য তত্ত্বীয় ব্যাখ্যা এখনও কেউ গড়ে তোলেনি। আসলে গবেষকরা এখনও এমন paper লেখেন যেখানে তাঁরা regularization-এর বিভিন্ন পদ্ধতি চেষ্টা করেন, কোনটা ভালো কাজ করে তা দেখতে তুলনা করেন, এবং বিভিন্ন পদ্ধতি কেন ভালো বা খারাপ কাজ করে তা বোঝার চেষ্টা করেন। তাই regularization-কে তুমি একরকম kludge হিসেবে দেখতে পারো। এটা প্রায়ই সাহায্য করলেও, কী ঘটছে তার একটা সম্পূর্ণ সন্তোষজনক পদ্ধতিগত বোঝাপড়া আমাদের নেই, কেবল অসম্পূর্ণ heuristic ও বুড়ো আঙুলের নিয়ম আছে।
এখানে আরও গভীর কিছু সমস্যা আছে, যেগুলো বিজ্ঞানের মর্মে পৌঁছায়। এটা এই প্রশ্ন যে আমরা কীভাবে generalize করি। regularization হয়তো আমাদের একটা computational জাদুর কাঠি দেয় যা আমাদের network-কে ভালো generalize করতে সাহায্য করে, কিন্তু এটা আমাদের generalization কীভাবে কাজ করে বা সেরা পদ্ধতি কী তার নীতিগত বোঝাপড়া দেয় না।
এটা বিশেষভাবে বিরক্তিকর কারণ দৈনন্দিন জীবনে আমরা মানুষরা অসাধারণভাবে ভালো generalize করি। একটা হাতির মাত্র কয়েকটা ছবি দেখানো হলে একটা শিশু দ্রুত অন্য হাতি চিনতে শিখে নেয়। অবশ্যই তারা মাঝে মাঝে ভুল করতে পারে, হয়তো একটা গন্ডারকে হাতি ভেবে গুলিয়ে ফেলে, কিন্তু সাধারণভাবে এই প্রক্রিয়া উল্লেখযোগ্যভাবে নিখুঁতভাবে কাজ করে। তাই আমাদের কাছে একটা system আছে — মানুষের মস্তিষ্ক — যার বিপুল সংখ্যক free parameter আছে। আর মাত্র এক বা কয়েকটা training ছবি দেখানোর পর সেই system অন্য ছবিতে generalize করতে শেখে। আমাদের মস্তিষ্ক কোনো অর্থে বিস্ময়করভাবে ভালো regularize করছে! আমরা এটা কীভাবে করি? এই মুহূর্তে আমরা জানি না। আমি প্রত্যাশা করি আগামী বছরগুলোতে আমরা artificial neural network-এ regularization-এর আরও শক্তিশালী কৌশল গড়ে তুলব, এমন কৌশল যা শেষমেশ neural net-কে ছোট data set থেকেও ভালো generalize করতে সক্ষম করবে।
আসলে আমাদের network ইতিমধ্যেই এমন ভালো generalize করে যা a priori প্রত্যাশার চেয়ে বেশি। 100 hidden neuron-এর একটা network-এ প্রায় 80,000 parameter আছে। আমাদের training data-তে কেবল 50,000 ছবি আছে। এটা যেন 50,000 data point-এ একটা 80,000-degree polynomial fit করার চেষ্টা। সব হিসেবে আমাদের network-এর ভয়ংকরভাবে overfit করার কথা। অথচ, যেমন আগে দেখলাম, এমন একটা network আসলে generalize করায় বেশ ভালো কাজ করে। তা কেন? এটা ভালোভাবে বোঝা যায় না। অনুমান করা হয়েছে যে "multilayer net-এ gradient descent learning-এর dynamics-এর একটা 'self-regularization' প্রভাব আছে"। এটা ব্যতিক্রমীভাবে সৌভাগ্যের, তবে এটা কিছুটা অস্বস্তিকরও যে আমরা বুঝি না কেন তা সত্যি। ইতিমধ্যে আমরা ব্যবহারিক পন্থা নেব এবং যখনই পারি regularization ব্যবহার করব। আমাদের neural network তাতে আরও ভালো হবে।
এই section শেষ করি আগে অব্যাখ্যাত রেখে আসা একটা বিষয়ে ফিরে: এই সত্য যে L2 regularization bias-গুলো সীমাবদ্ধ করে না। অবশ্যই bias-গুলো regularize করতে regularization পদ্ধতিটা সহজে পরিবর্তন করা যেত। অভিজ্ঞতাগতভাবে, তা করলে প্রায়ই ফল খুব বেশি বদলায় না, তাই অনেকটাই এটা একটা প্রথা যে bias regularize করা হবে কিনা। তবে উল্লেখযোগ্য যে একটা বড় bias থাকা একটা neuron-কে তার input-এর প্রতি সংবেদনশীল করে তোলে না যেভাবে বড় weight করে। তাই আমাদের দুশ্চিন্তা করার দরকার নেই যে বড় bias আমাদের network-কে training data-র noise শিখতে সক্ষম করবে। একই সাথে, বড় bias অনুমোদন করা আমাদের network-কে আচরণে আরও নমনীয়তা দেয় — বিশেষত বড় bias neuron-কে saturate করা সহজ করে, যা কখনও কখনও কাঙ্ক্ষিত। এসব কারণে আমরা সাধারণত regularize করার সময় bias পদ অন্তর্ভুক্ত করি না।
Regularization-এর অন্যান্য কৌশল
L2 regularization ছাড়াও আরও অনেক regularization কৌশল আছে। আসলে এত কৌশল গড়ে উঠেছে যে আমার পক্ষে সেগুলো সব সংক্ষেপে বলা অসম্ভব। এই section-এ আমি overfitting কমানোর আরও তিনটি পদ্ধতি সংক্ষেপে বর্ণনা করব: L1 regularization, dropout, এবং কৃত্রিমভাবে training set-এর আকার বাড়ানো। এই কৌশলগুলো আমরা আগের মতো অতটা গভীরভাবে অধ্যয়ন করব না। বরং উদ্দেশ্য হলো মূল ধারণাগুলোর সাথে পরিচিত হওয়া, এবং উপলব্ধ regularization কৌশলের বৈচিত্র্যের কিছুটা উপলব্ধি করা।
L1 regularization: এই পদ্ধতিতে আমরা unregularized cost function-এ weight-গুলোর পরম মানের যোগফল যোগ করে তা পরিবর্তন করি:
স্বজ্ঞাতভাবে এটা L2 regularization-এর সদৃশ, বড় weight-কে শাস্তি দেয়, এবং network-কে ছোট weight পছন্দ করানোর প্রবণতা রাখে। অবশ্যই L1 regularization term L2 regularization term-এর সমান নয়, তাই আমাদের ঠিক একই আচরণ আশা করা উচিত নয়। L1 regularization দিয়ে train করা একটা network-এর আচরণ L2 regularization দিয়ে train করা network থেকে কীভাবে আলাদা তা বোঝার চেষ্টা করি।
তা করতে আমরা cost function-এর partial derivative দেখব। (95) differentiate করে পাই:
যেখানে হলো -এর চিহ্ন, অর্থাৎ যদি ধনাত্মক হয়, আর যদি ঋণাত্মক হয়। এই রাশি ব্যবহার করে আমরা সহজেই backpropagation পরিবর্তন করে L1 regularization দিয়ে stochastic gradient descent করতে পারি। একটা L1 regularized network-এর ফলস্বরূপ update rule হলো:
যেখানে যথারীতি আমরা ইচ্ছে করলে একটা mini-batch গড় দিয়ে অনুমান করতে পারি। এটাকে L2 regularization-এর update rule-এর সাথে তুলনা করো (cf. Equation (93)):
দুটো রাশিতেই regularization-এর প্রভাব হলো weight-গুলো ছোট করা। এটা আমাদের স্বজ্ঞার সাথে মেলে যে দুই ধরনের regularization-ই বড় weight-কে শাস্তি দেয়। কিন্তু weight যেভাবে ছোট হয় তা আলাদা। L1 regularization-এ weight একটা ধ্রুব পরিমাণে -এর দিকে ছোট হয়। L2 regularization-এ weight এমন একটা পরিমাণে ছোট হয় যা -এর সমানুপাতিক। তাই কোনো নির্দিষ্ট weight-এর মান বড় হলে, , L1 regularization weight-কে L2 regularization-এর চেয়ে অনেক কম ছোট করে। তুলনায়, ছোট হলে L1 regularization weight-কে L2 regularization-এর চেয়ে অনেক বেশি ছোট করে। নিট ফল হলো L1 regularization network-এর weight অপেক্ষাকৃত অল্প সংখ্যক উচ্চ-গুরুত্বপূর্ণ connection-এ কেন্দ্রীভূত করার প্রবণতা রাখে, যেখানে বাকি weight শূন্যের দিকে চালিত হয়।
উপরের আলোচনায় আমি একটা বিষয় এড়িয়ে গেছি, যা হলো partial derivative হলে সংজ্ঞায়িত নয়। কারণ function-এর -এ একটা তীক্ষ্ণ "কোণা" আছে, তাই ওই বিন্দুতে এটা differentiable নয়। তবে সেটা ঠিক আছে। আমরা যা করব তা হলো হলে কেবল stochastic gradient descent-এর চিরাচরিত (unregularized) নিয়ম প্রয়োগ করব। সেটা ঠিক হওয়ার কথা — স্বজ্ঞাতভাবে, regularization-এর প্রভাব হলো weight ছোট করা, আর স্পষ্টতই এটা এমন একটা weight ছোট করতে পারে না যা ইতিমধ্যেই । আরও সুনির্দিষ্টভাবে বললে, আমরা Equation (96) ও (97) ব্যবহার করব এই প্রথা সহ যে । এটা L1 regularization দিয়ে stochastic gradient descent করার একটা সুন্দর, সংক্ষিপ্ত নিয়ম দেয়।
Dropout: Dropout regularization-এর একটা আমূল ভিন্ন কৌশল। L1 ও L2 regularization-এর বিপরীতে, dropout cost function পরিবর্তনের উপর নির্ভর করে না। তার বদলে dropout-এ আমরা network নিজেই পরিবর্তন করি। dropout কীভাবে কাজ করে তার মৌলিক যান্ত্রিকতা বর্ণনা করি, এটা কেন কাজ করে ও ফল কী তাতে যাওয়ার আগে।
ধরো আমরা একটা network train করার চেষ্টা করছি:
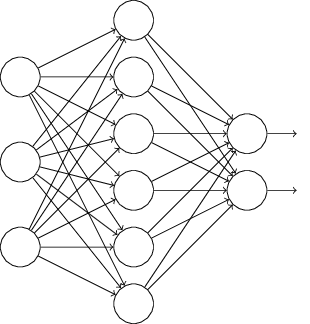
বিশেষত ধরো আমাদের একটা training input ও সংশ্লিষ্ট কাঙ্ক্ষিত output আছে। সাধারণত আমরা network-এর মধ্য দিয়ে forward-propagate করে, তারপর gradient-এ অবদান নির্ধারণ করতে backpropagate করে train করতাম। dropout-এ এই প্রক্রিয়া পরিবর্তিত হয়। আমরা শুরু করি network-এর অর্ধেক hidden neuron randomly (ও সাময়িকভাবে) মুছে দিয়ে, আর input ও output neuron অস্পর্শ রেখে। এটা করার পর আমরা নিচের ধাঁচের একটা network পাব। খেয়াল করো dropout neuron-গুলো, অর্থাৎ যেগুলো সাময়িকভাবে মুছে দেওয়া হয়েছে, সেগুলো এখনও আবছাভাবে দেখানো আছে:
আমরা পরিবর্তিত network-এর মধ্য দিয়ে input forward-propagate করি, তারপর ফলটা — আবার পরিবর্তিত network-এর মধ্য দিয়ে — backpropagate করি। একগুচ্ছ example-এর একটা mini-batch-এর উপর এটা করার পর আমরা উপযুক্ত weight ও bias update করি। তারপর প্রক্রিয়াটা পুনরাবৃত্তি করি — প্রথমে dropout neuron-গুলো পুনরুদ্ধার করে, তারপর মুছে দেওয়ার জন্য hidden neuron-এর একটা নতুন random subset বেছে নিয়ে, একটা ভিন্ন mini-batch-এর জন্য gradient অনুমান করে, এবং network-এর weight ও bias update করে।
এই প্রক্রিয়া বারবার পুনরাবৃত্তি করে আমাদের network একগুচ্ছ weight ও bias শিখবে। অবশ্যই ওই weight ও bias এমন পরিস্থিতিতে শেখা হবে যেখানে অর্ধেক hidden neuron dropout করা ছিল। আমরা যখন আসলে পূর্ণ network চালাই তখন তার মানে দ্বিগুণ সংখ্যক hidden neuron সক্রিয় থাকবে। তা পুষিয়ে দিতে আমরা hidden neuron থেকে বেরিয়ে আসা weight-গুলো অর্ধেক করি।
এই dropout পদ্ধতি অদ্ভুত ও ad hoc মনে হতে পারে। এটা regularization-এ সাহায্য করবে বলে আমরা কেন আশা করব? কী ঘটছে তা ব্যাখ্যা করতে আমি চাই তুমি কিছুক্ষণের জন্য dropout নিয়ে ভাবা বন্ধ করো, এবং তার বদলে standard উপায়ে (dropout ছাড়া) neural network train করার কথা কল্পনা করো। বিশেষত কল্পনা করো আমরা একই training data ব্যবহার করে কয়েকটা ভিন্ন neural network train করি। অবশ্যই network-গুলো একই রকম শুরু না-ও হতে পারে, এবং ফলে train করার পর সেগুলো কখনও কখনও ভিন্ন ফল দিতে পারে। তেমন হলে আমরা কোন output গ্রহণ করব তা ঠিক করতে কোনো ধরনের গড় বা ভোটিং scheme ব্যবহার করতে পারি। যেমন আমরা পাঁচটা network train করলে, আর তাদের তিনটে একটা সংখ্যাকে "3" হিসেবে classify করলে, তবে এটা সম্ভবত সত্যিই একটা "3"। বাকি দুটো network সম্ভবত কেবল ভুল করছে। এই ধরনের গড়-পদ্ধতি প্রায়ই overfitting কমানোর একটা শক্তিশালী (যদিও ব্যয়বহুল) উপায় বলে দেখা যায়। কারণ ভিন্ন network ভিন্ন উপায়ে overfit করতে পারে, আর গড় নেওয়া সেই ধরনের overfitting দূর করতে সাহায্য করতে পারে।
এর সাথে dropout-এর কী সম্পর্ক? Heuristic-ভাবে, আমরা যখন neuron-এর ভিন্ন ভিন্ন সেট dropout করি, এটা যেন আমরা ভিন্ন ভিন্ন neural network train করছি। তাই dropout পদ্ধতি যেন বিপুল সংখ্যক ভিন্ন network-এর প্রভাব গড় করা। ভিন্ন network ভিন্ন উপায়ে overfit করবে, তাই আশা করা যায় dropout-এর নিট প্রভাব হবে overfitting কমানো।
dropout-এর একটা সম্পর্কিত heuristic ব্যাখ্যা কৌশলটি ব্যবহারকারী প্রথম দিকের একটা paper-এ দেওয়া আছে: "এই কৌশল neuron-এর জটিল co-adaptation কমায়, যেহেতু একটা neuron নির্দিষ্ট অন্য neuron-এর উপস্থিতির উপর নির্ভর করতে পারে না। তাই এটা আরও শক্তিশালী feature শিখতে বাধ্য হয় যা অন্য neuron-এর অনেক ভিন্ন random subset-এর সাথে মিলে উপকারী।" অন্যভাবে বললে, আমরা যদি আমাদের network-কে একটা model হিসেবে ভাবি যা ভবিষ্যদ্বাণী করছে, তবে dropout-কে এমন একটা উপায় হিসেবে ভাবতে পারি যা নিশ্চিত করে model প্রমাণের যেকোনো একক টুকরো হারানোর প্রতি শক্তিশালী। এতে এটা L1 ও L2 regularization-এর কিছুটা সদৃশ, যেগুলো weight কমানোর প্রবণতা রাখে, এবং তাই network-এর যেকোনো একক connection হারানোর প্রতি network-কে আরও শক্তিশালী করে।
অবশ্যই dropout-এর প্রকৃত পরিমাপ হলো এটা neural network-এর performance উন্নত করায় খুব সফল হয়েছে। কৌশলটি প্রবর্তনকারী মূল paper-টি এটাকে অনেক ভিন্ন কাজে প্রয়োগ করেছিল। আমাদের জন্য এটা বিশেষভাবে আগ্রহের যে তারা dropout-কে MNIST সংখ্যা classification-এ প্রয়োগ করেছিল, আমরা যে ধরনের সাদামাটা feedforward neural network বিবেচনা করছি তার অনুরূপ একটা network ব্যবহার করে। paper-টি উল্লেখ করেছিল যে তখন পর্যন্ত এমন একটা architecture দিয়ে কেউ অর্জন করা সেরা ফল ছিল test set-এ শতাংশ classification accuracy। তারা dropout ও L2 regularization-এর একটা পরিবর্তিত রূপের সমন্বয়ে তা শতাংশ accuracy-তে উন্নত করেছিল। image ও speech recognition এবং natural language processing-এর সমস্যাসহ আরও অনেক কাজের জন্য একইরকম চমকপ্রদ ফল পাওয়া গেছে। বড়, deep network train করায় dropout বিশেষভাবে উপকারী হয়েছে, যেখানে overfitting-এর সমস্যা প্রায়ই তীব্র।
কৃত্রিমভাবে training data বিস্তার করা: আমরা আগে দেখেছি যে কেবল 1,000 training ছবি ব্যবহার করলে আমাদের MNIST classification accuracy 80-এর মাঝামাঝি শতাংশে নেমে যায়। এটা অবাক করার মতো নয়, কারণ কম training data মানে আমাদের network মানুষ কীভাবে সংখ্যা লেখে তার কম বৈচিত্র্যের সম্মুখীন হবে। চলো আমাদের 30 hidden neuron-এর network বিভিন্ন আকারের training data set দিয়ে train করি, performance কীভাবে বদলায় তা দেখতে। আমরা mini-batch size, learning rate, regularization parameter ও cross-entropy cost function দিয়ে train করব। পুরো training data set ব্যবহার করলে আমরা 30 epoch ধরে train করব, এবং ছোট training set ব্যবহার করলে epoch সংখ্যা সমানুপাতিকভাবে বাড়াব। weight decay factor training set জুড়ে একই রাখতে আমরা পুরো training data set ব্যবহার করলে ব্যবহার করব, এবং ছোট training set ব্যবহার করলে সমানুপাতিকভাবে কমাব।
দেখতে পাচ্ছ, আমরা যত বেশি training data ব্যবহার করি classification accuracy তত উল্লেখযোগ্যভাবে উন্নত হয়। সম্ভবত আরও বেশি data পাওয়া গেলে এই উন্নতি আরও চলত। অবশ্য উপরের graph দেখে মনে হয় আমরা saturation-এর কাছে পৌঁছাচ্ছি। তবে ধরো আমরা training set-এর আকার logarithmically plot করে graph-টা আবার আঁকি:
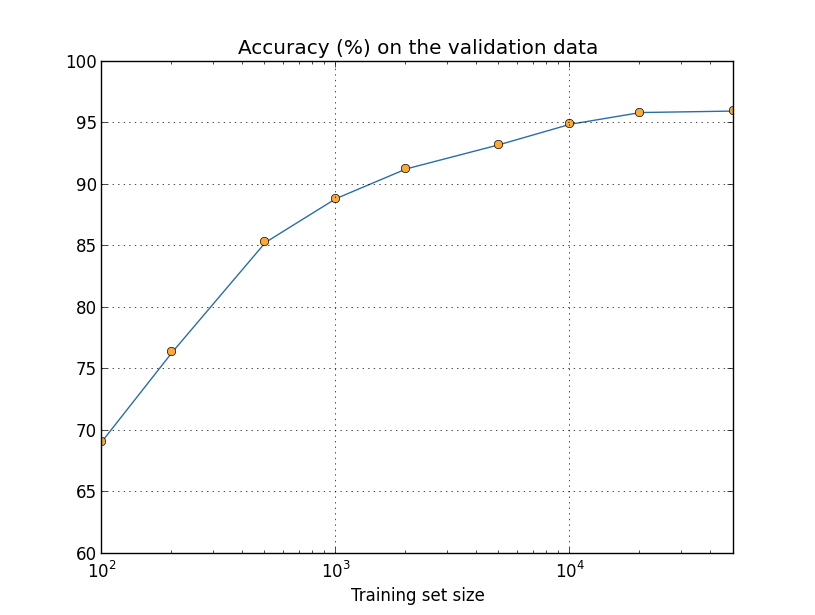
মনে হচ্ছে graph-টা শেষের দিকেও স্পষ্টভাবে উপরে উঠছে। এটা ইঙ্গিত করে যে আমরা যদি অনেক বেশি training data — ধরো লক্ষ এমনকি কোটি হাতের লেখা নমুনা, কেবল 50,000-এর বদলে — ব্যবহার করতাম, তবে সম্ভবত এই খুব ছোট network থেকেও যথেষ্ট ভালো performance পেতাম।
আরও training data পাওয়া একটা চমৎকার ধারণা। দুর্ভাগ্যবশত এটা ব্যয়বহুল হতে পারে, তাই বাস্তবে সবসময় সম্ভব নয়। তবে আরেকটা ধারণা আছে যা প্রায় ততটাই ভালো কাজ করতে পারে, আর তা হলো কৃত্রিমভাবে training data বিস্তার করা। ধরো উদাহরণস্বরূপ আমরা একটা পাঁচের MNIST training ছবি নিই,

আর সেটাকে সামান্য পরিমাণে, ধরো 15 ডিগ্রি, ঘোরাই:

এটা এখনও চিনতে-পারা সেই একই সংখ্যা। অথচ pixel স্তরে এটা MNIST training data-তে বর্তমানে থাকা যেকোনো ছবির থেকে বেশ আলাদা। এটা ধারণা করা যায় যে এই ছবি training data-তে যোগ করলে আমাদের network সংখ্যা কীভাবে classify করতে হয় সে সম্পর্কে আরও শিখতে পারে। তাছাড়া স্পষ্টতই আমরা কেবল এই একটা ছবি যোগ করায় সীমাবদ্ধ নই। আমরা সব MNIST training ছবির অনেক ছোট ঘূর্ণন করে আমাদের training data বিস্তার করতে পারি, এবং তারপর বিস্তৃত training data ব্যবহার করে আমাদের network-এর performance উন্নত করতে পারি।
এই ধারণা খুব শক্তিশালী এবং ব্যাপকভাবে ব্যবহৃত হয়েছে। চলো একটা paper থেকে কিছু ফল দেখি যা MNIST-এ এই ধারণার কয়েকটা রূপ প্রয়োগ করেছিল। তারা বিবেচিত neural network architecture-গুলোর একটা ছিল আমরা যা ব্যবহার করছি তার অনুরূপ — 800 hidden neuron-সহ একটা feedforward network এবং cross-entropy cost function ব্যবহারকারী। Standard MNIST training data দিয়ে network চালিয়ে তারা তাদের test set-এ 98.4 শতাংশ classification accuracy অর্জন করেছিল। কিন্তু তারপর তারা training data বিস্তার করেছিল, কেবল উপরে বর্ণিত ঘূর্ণন নয়, বরং ছবি স্থানান্তর ও skew করেও। বিস্তৃত data set-এ train করে তারা তাদের network-এর accuracy 98.9 শতাংশে বাড়িয়েছিল। তারা "elastic distortion" নামে কিছু নিয়েও পরীক্ষা করেছিল, এক বিশেষ ধরনের image distortion যা হাতের পেশিতে পাওয়া random oscillation অনুকরণের উদ্দেশ্যে। data বিস্তার করতে elastic distortion ব্যবহার করে তারা আরও উঁচু accuracy, 99.3 শতাংশ অর্জন করেছিল। কার্যকরভাবে, তারা তাদের network-কে বাস্তব হাতের লেখায় পাওয়া ধরনের বৈচিত্র্যের সম্মুখীন করে এর অভিজ্ঞতা প্রসারিত করছিল।
এই ধারণার রূপগুলো কেবল handwriting recognition নয়, আরও অনেক শেখার কাজে performance উন্নত করতে ব্যবহার করা যায়। সাধারণ নীতি হলো বাস্তব-জগতের বৈচিত্র্য প্রতিফলিত করে এমন operation প্রয়োগ করে training data বিস্তার করা। এটা করার উপায় ভাবা কঠিন নয়। ধরো উদাহরণস্বরূপ তুমি speech recognition করতে একটা neural network বানাচ্ছ। আমরা মানুষরা background noise-এর মতো distortion-এর উপস্থিতিতেও কথা চিনতে পারি। তাই তুমি background noise যোগ করে তোমার data বিস্তার করতে পারো। কথা দ্রুত বা ধীর করা হলেও আমরা চিনতে পারি। তাই training data বিস্তারের এটা আরেকটা উপায়। এই কৌশলগুলো সবসময় ব্যবহার করা হয় না — যেমন noise যোগ করে training data বিস্তারের বদলে আগে একটা noise reduction filter প্রয়োগ করে network-এর input পরিষ্কার করা হয়তো বেশি কার্যকর। তবু training data বিস্তারের ধারণা মনে রাখা ও এটা প্রয়োগের সুযোগ খোঁজা সার্থক।
big data ও classification accuracy তুলনা করার অর্থ কী, সে সম্পর্কে একটা প্রসঙ্গ: আমাদের neural network-এর accuracy training set-এর আকারের সাথে কীভাবে বদলায় তা আবার দেখি। ধরো neural network-এর বদলে আমরা সংখ্যা classify করতে অন্য কোনো machine learning কৌশল ব্যবহার করি। যেমন, চলো অধ্যায় ১-এ সংক্ষেপে দেখা support vector machine (SVM) ব্যবহার করি। অধ্যায় ১-এর মতোই, SVM-এর সাথে পরিচিত না হলে দুশ্চিন্তা করো না, আমাদের তাদের বিস্তারিত বোঝার দরকার নেই। তার বদলে আমরা scikit-learn library-র দেওয়া SVM ব্যবহার করব। এই হলো SVM-এর performance training set-এর আকারের function হিসেবে কীভাবে বদলায়। তুলনা সহজ করতে আমি neural net-এর ফলও plot করেছি:
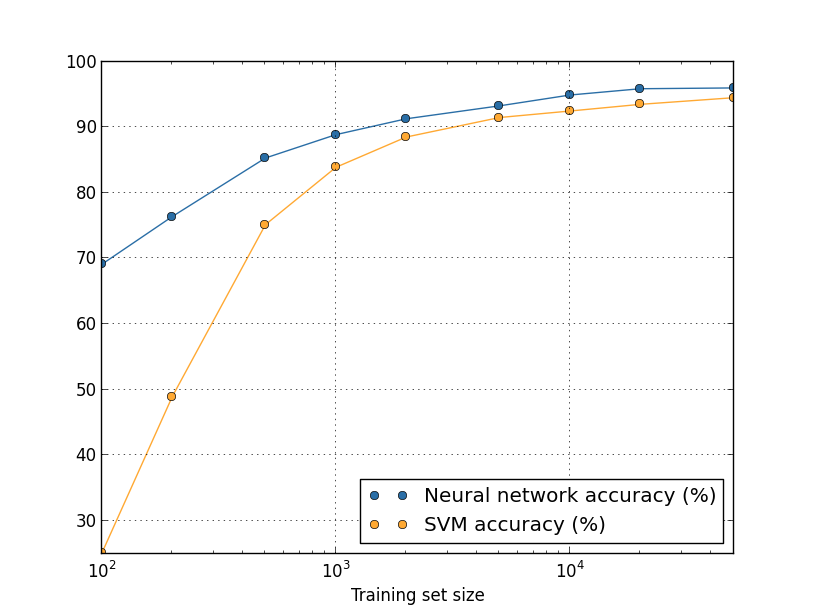
এই graph-এ সম্ভবত প্রথম যা তোমার চোখে পড়বে তা হলো প্রতিটি training set আকারের জন্য আমাদের neural network SVM-কে ছাড়িয়ে যায়। সেটা ভালো, যদিও এতে খুব বেশি অর্থ খোঁজা উচিত নয়, কারণ আমি কেবল scikit-learn-এর SVM-এর out-of-the-box setting ব্যবহার করেছি, যেখানে আমরা আমাদের neural network উন্নত করতে যথেষ্ট কাজ করেছি। graph সম্পর্কে আরও সূক্ষ্ম কিন্তু আরও আগ্রহজনক একটা তথ্য হলো আমরা যদি 50,000 ছবি দিয়ে আমাদের SVM train করি তবে এটা আসলে 5,000 ছবি দিয়ে train করা আমাদের neural network-এর (93.24 শতাংশ accuracy) চেয়ে ভালো performance (94.48 শতাংশ accuracy) দেয়। অন্যভাবে বললে, আরও training data কখনও কখনও ব্যবহৃত machine learning algorithm-এর পার্থক্য পুষিয়ে দিতে পারে।
আরও আগ্রহজনক কিছু ঘটতে পারে। ধরো আমরা দুটো machine learning algorithm — algorithm A ও algorithm B — দিয়ে একটা সমস্যা সমাধানের চেষ্টা করছি। কখনও কখনও এমন ঘটে যে একগুচ্ছ training data দিয়ে algorithm A, algorithm B-কে ছাড়িয়ে যায়, আবার একটা ভিন্ন training data দিয়ে algorithm B, algorithm A-কে ছাড়িয়ে যায়। উপরে আমরা তা দেখি না — তা হতে হলে দুটো graph-কে পরস্পরছেদী হতে হতো — কিন্তু এটা ঘটে। "algorithm A কি algorithm B-র চেয়ে ভালো?" প্রশ্নটির সঠিক জবাব আসলে: "তুমি কোন training data set ব্যবহার করছ?"
এই সবকিছু একটা সতর্কতা, যা development করার সময় এবং research paper পড়ার সময় — দুই ক্ষেত্রেই মনে রাখার মতো। অনেক paper standard benchmark data set-এ উন্নত performance বের করার নতুন কৌশল খোঁজায় মনোযোগ দেয়। "আমাদের চমৎকার কৌশল standard benchmark Y-তে আমাদের X শতাংশ উন্নতি দিয়েছে" — এটা গবেষণা দাবির একটা প্রামাণিক রূপ। এমন দাবি প্রায়ই সত্যিকার আগ্রহজনক, তবে সেগুলো ব্যবহৃত নির্দিষ্ট training data set-এর প্রেক্ষাপটেই কেবল প্রযোজ্য বলে বোঝা উচিত। কল্পনা করো একটা বিকল্প ইতিহাস যেখানে benchmark data set-এর মূল নির্মাতাদের আরও বড় research grant ছিল। তারা হয়তো বাড়তি টাকা দিয়ে আরও training data সংগ্রহ করত। এটা সম্পূর্ণ সম্ভব যে চমৎকার কৌশলের কারণে "উন্নতি"টা একটা বড় data set-এ অদৃশ্য হয়ে যেত। অন্যভাবে বললে, কথিত উন্নতিটা হয়তো নিছক ইতিহাসের একটা দৈব। যা মনে রাখার মতো বার্তা — বিশেষত ব্যবহারিক প্রয়োগে — তা হলো আমরা চাই ভালো algorithm ও ভালো training data দুটোই। ভালো algorithm খোঁজা ঠিক আছে, তবে নিশ্চিত করো যে তুমি আরও বা ভালো training data পাওয়ার সহজ জয় বাদ দিয়ে কেবল ভালো algorithm-এ মনোযোগ দিচ্ছ না।
সারসংক্ষেপ: আমরা এখন overfitting ও regularization-এ আমাদের ডুব দেওয়া শেষ করলাম। অবশ্যই আমরা এই বিষয়ে আবার ফিরব। যেমন কয়েকবার উল্লেখ করেছি, overfitting neural network-এ একটা বড় সমস্যা, বিশেষত যখন computer আরও শক্তিশালী হয় এবং আমরা বড় network train করার ক্ষমতা পাই। ফলে overfitting কমাতে শক্তিশালী regularization কৌশল গড়ে তোলার একটা চাপা প্রয়োজন আছে, এবং এটা বর্তমান কাজের একটা অত্যন্ত সক্রিয় ক্ষেত্র।
Weight initialization
আমরা যখন আমাদের neural network তৈরি করি তখন শুরুর weight ও bias-এর জন্য পছন্দ করতে হয়। এতক্ষণ আমরা সেগুলো এমন একটা নির্দেশ অনুযায়ী বেছে নিচ্ছিলাম যা অধ্যায় ১-এ সংক্ষেপে আলোচনা করেছিলাম। মনে করিয়ে দিই, ওই নির্দেশ ছিল weight ও bias দুটোই স্বাধীন Gaussian random variable দিয়ে বেছে নেওয়া, mean ও standard deviation -এ normalize করা। এই পন্থা ভালোই কাজ করলেও এটা বেশ ad hoc ছিল, এবং পুনর্বিবেচনা করা সার্থক — দেখতে যে আমরা শুরুর weight ও bias সেট করার একটা ভালো উপায় খুঁজে পাই কিনা, এবং হয়তো আমাদের neural network-কে দ্রুত শিখতে সাহায্য করি কিনা।
দেখা যায় normalized Gaussian দিয়ে initialize করার চেয়ে আমরা বেশ খানিকটা ভালো করতে পারি। কেন তা দেখতে ধরো আমরা প্রচুর — ধরো টি — input neuron সহ একটা network নিয়ে কাজ করছি। আর ধরো আমরা প্রথম hidden layer-এ সংযুক্ত weight-গুলো normalized Gaussian দিয়ে initialize করেছি। আপাতত আমি বিশেষভাবে input neuron থেকে hidden layer-এর প্রথম neuron-এ সংযুক্ত weight-গুলোতে মনোযোগ দেব, আর network-এর বাকি অংশ উপেক্ষা করব:
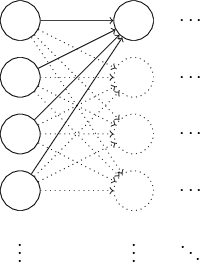
সরলতার জন্য ধরো আমরা এমন একটা training input দিয়ে train করার চেষ্টা করছি যেখানে অর্ধেক input neuron on, অর্থাৎ -এ সেট, আর অর্ধেক input neuron off, অর্থাৎ -এ সেট। নিচের যুক্তি আরও সাধারণভাবেও খাটে, তবে এই বিশেষ ক্ষেত্র থেকেই তুমি মূল ভাবটা পাবে। আমাদের hidden neuron-এ input-গুলোর weighted sum বিবেচনা করি। এই যোগফলে টি পদ লোপ পায়, কারণ সংশ্লিষ্ট input শূন্য। তাই হলো মোট টি normalized Gaussian random variable-এর উপর একটা যোগফল — টি weight পদ ও টি বাড়তি bias পদের হিসাব নিয়ে। তাই নিজে mean শূন্য ও standard deviation সহ একটা Gaussian হিসেবে বণ্টিত হয়। অর্থাৎ -এর একটা খুব প্রশস্ত Gaussian distribution আছে, মোটেও তীক্ষ্ণভাবে শীর্ষবিন্দুযুক্ত নয়:
বিশেষত, এই graph থেকে আমরা দেখি যে বেশ বড় হওয়ার সম্ভাবনা প্রবল, অর্থাৎ হয় না হয় । তেমন হলে hidden neuron থেকে output হয় না হয় -এর খুব কাছাকাছি হবে। অর্থাৎ আমাদের hidden neuron saturate হয়ে গেছে। আর তা ঘটলে, আমরা জানি, weight-এ ছোট পরিবর্তন আমাদের hidden neuron-এর activation-এ কেবল একেবারে নগণ্য পরিবর্তন ঘটাবে। hidden neuron-এর activation-এর ওই নগণ্য পরিবর্তন, পরিণামে, network-এর বাকি neuron-গুলোকে প্রায় প্রভাবিতই করবে না, এবং আমরা cost function-এ সংশ্লিষ্ট একটা নগণ্য পরিবর্তন দেখব। ফলে gradient descent algorithm ব্যবহার করলে ওই weight-গুলো কেবল খুব ধীরে শিখবে। এটা এই অধ্যায়ে আগে আলোচনা করা সমস্যার অনুরূপ, যেখানে ভুল মানে saturate হওয়া output neuron শেখাকে ধীর করে দিয়েছিল। আমরা ওই আগের সমস্যা cost function-এর একটা চতুর পছন্দ দিয়ে সামলেছিলাম। দুর্ভাগ্যবশত, সেটা saturate হওয়া output neuron-এ সাহায্য করলেও, saturate হওয়া hidden neuron-এর সমস্যায় তা কিছুই করে না।
আমি প্রথম hidden layer-এ input হওয়া weight নিয়ে কথা বলছিলাম। অবশ্যই একইরকম যুক্তি পরের hidden layer-গুলোতেও খাটে: পরের hidden layer-এর weight-গুলো normalized Gaussian দিয়ে initialize করা হলে activation প্রায়ই বা -এর খুব কাছাকাছি হবে, এবং শেখা খুব ধীরে চলবে।
weight ও bias-এর জন্য কোনো ভালো initialization বেছে নেওয়ার উপায় কি আছে, যাতে এই ধরনের saturation না ঘটে, এবং এভাবে শেখার মন্থরতা এড়ানো যায়? ধরো আমাদের একটা neuron আছে যার টি input weight। তখন আমরা ওই weight-গুলো mean ও standard deviation সহ Gaussian random variable হিসেবে initialize করব। অর্থাৎ আমরা Gaussian-গুলোকে চেপে দেব, যাতে আমাদের neuron-এর saturate হওয়ার সম্ভাবনা কম হয়। আমরা bias আগের মতোই mean ও standard deviation সহ একটা Gaussian হিসেবে বেছে নেব, যে কারণে তা একটু পরে ফিরব। এই পছন্দগুলো দিয়ে weighted sum আবারও mean সহ একটা Gaussian random variable হবে, তবে আগের চেয়ে অনেক বেশি তীক্ষ্ণভাবে শীর্ষবিন্দুযুক্ত হবে। ধরো, যেমন আগে করেছিলাম, টি input শূন্য আর টি । তখন সহজে দেখানো যায় (নিচের অনুশীলনী দেখো) যে -এর mean ও standard deviation সহ একটা Gaussian distribution আছে। এটা আগের চেয়ে অনেক বেশি তীক্ষ্ণভাবে শীর্ষবিন্দুযুক্ত, এতটাই যে নিচের graph-ও পরিস্থিতিটা কম করে দেখায়, কারণ আগের graph-এর তুলনায় আমাকে উল্লম্ব অক্ষটা পুনরায় স্কেল করতে হয়েছে:
এমন একটা neuron saturate হওয়ার সম্ভাবনা অনেক কম, এবং সেই অনুযায়ী শেখার মন্থরতার সমস্যা হওয়ার সম্ভাবনাও অনেক কম।
উপরে বলেছিলাম আমরা bias আগের মতোই initialize করতে থাকব, mean ও standard deviation সহ Gaussian random variable হিসেবে। এটা ঠিক আছে, কারণ এটা আমাদের neuron-গুলোর saturate হওয়ার সম্ভাবনা খুব বেশি বাড়ায় না। আসলে saturation-এর সমস্যা এড়ালে bias কীভাবে initialize করি তাতে বিশেষ কিছু আসে-যায় না। কেউ কেউ এতদূর যান যে সব bias -এ initialize করেন, এবং উপযুক্ত bias শিখতে gradient descent-এর উপর নির্ভর করেন। তবে যেহেতু এটা খুব একটা পার্থক্য আনার সম্ভাবনা কম, আমরা আগের মতোই একই initialization পদ্ধতিতে চলব।
MNIST সংখ্যা classification কাজ ব্যবহার করে weight initialization-এর আমাদের পুরনো ও নতুন দুই পন্থার ফল তুলনা করি। আগের মতোই আমরা টি hidden neuron, mini-batch size, regularization parameter ও cross-entropy cost function ব্যবহার করব। আমরা learning rate সামান্য কমিয়ে থেকে -এ আনব, কারণ এতে graph-এ ফল একটু বেশি সহজে দৃশ্যমান হয়। weight initialization-এর পুরনো পদ্ধতি দিয়ে train করতে পারি:
>>> import mnist_loader
>>> training_data, validation_data, test_data = \
... mnist_loader.load_data_wrapper()
>>> import network2
>>> net = network2.Network([784, 30, 10], cost=network2.CrossEntropyCost)
>>> net.large_weight_initializer()
>>> net.SGD(training_data, 30, 10, 0.1, lmbda = 5.0,
... evaluation_data=validation_data,
... monitor_evaluation_accuracy=True)weight initialization-এর নতুন পন্থা দিয়েও train করতে পারি। এটা আসলে আরও সহজ, কারণ network2-এর weight initialize করার default উপায় হলো এই নতুন পন্থা ব্যবহার করা। অর্থাৎ আমরা উপরের net.large_weight_initializer() call বাদ দিতে পারি:
>>> net = network2.Network([784, 30, 10], cost=network2.CrossEntropyCost)
>>> net.SGD(training_data, 30, 10, 0.1, lmbda = 5.0,
... evaluation_data=validation_data,
... monitor_evaluation_accuracy=True)ফল plot করে আমরা পাই:
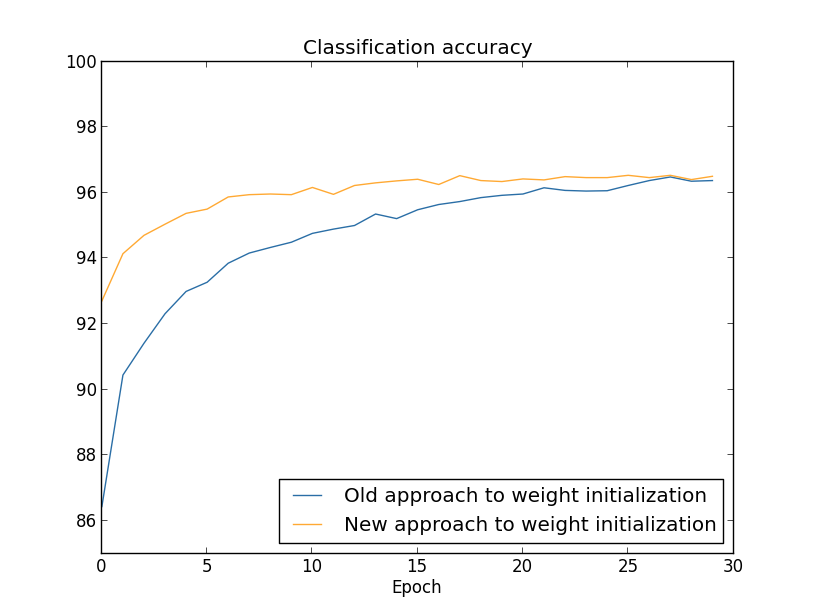
দুই ক্ষেত্রেই আমরা 96 শতাংশের কিছুটা বেশি একটা classification accuracy-তে শেষ করি। চূড়ান্ত classification accuracy দুই ক্ষেত্রে প্রায় হুবহু একই। কিন্তু নতুন initialization কৌশল আমাদের সেখানে অনেক, অনেক দ্রুত পৌঁছে দেয়। training-এর প্রথম epoch-এর শেষে weight initialization-এর পুরনো পন্থার classification accuracy 87 শতাংশের নিচে, যেখানে নতুন পন্থা ইতিমধ্যেই প্রায় 93 শতাংশ। মনে হচ্ছে যা ঘটছে তা হলো — আমাদের weight initialization-এর নতুন পন্থা আমাদের একটা অনেক ভালো অঞ্চলে শুরু করায়, যা আমাদের অনেক দ্রুত ভালো ফল পেতে দেয়। একই ঘটনা টি hidden neuron দিয়ে ফল plot করলেও দেখা যায়:
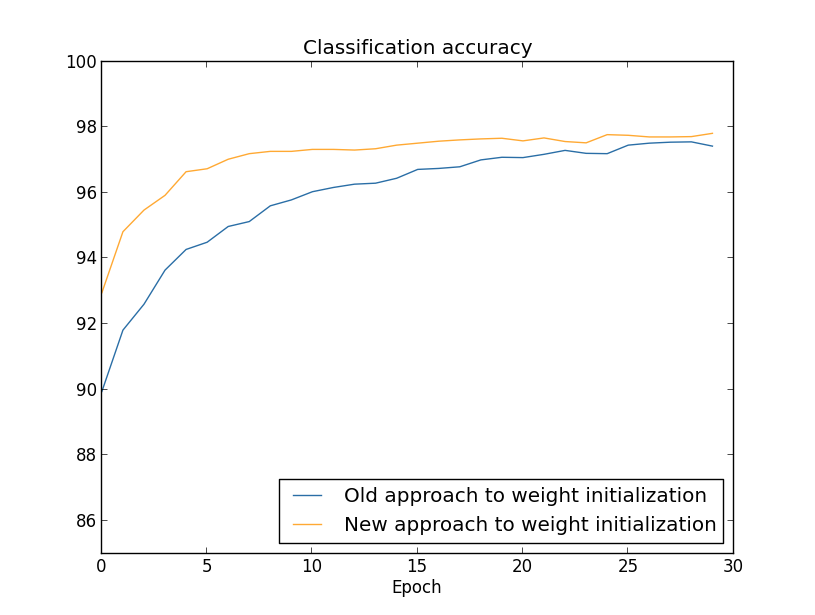
এই ক্ষেত্রে দুটো curve ঠিক মিলিত হয় না। তবে আমার পরীক্ষা ইঙ্গিত করে যে আর মাত্র কয়েকটা epoch training-এর পর (দেখানো হয়নি) accuracy প্রায় হুবহু একই হয়ে যায়। তাই এই পরীক্ষার ভিত্তিতে মনে হচ্ছে উন্নত weight initialization কেবল শেখার গতি বাড়ায়, এটা আমাদের network-এর চূড়ান্ত performance বদলায় না। তবে অধ্যায় ৪-এ আমরা এমন neural network-এর উদাহরণ দেখব যেখানে weight initialization দিয়ে দীর্ঘমেয়াদি আচরণ উল্লেখযোগ্যভাবে ভালো হয়। তাই কেবল শেখার গতিই উন্নত হয় না, কখনও কখনও চূড়ান্ত performance-ও উন্নত হয়।
weight initialization-এর পন্থা আমাদের neural net যেভাবে শেখে তা উন্নত করতে সাহায্য করে। weight initialization-এর আরও কৌশল প্রস্তাব করা হয়েছে, যার অনেকগুলো এই মৌলিক ধারণার উপর গড়ে ওঠা। আমি এখানে অন্য পন্থাগুলো পর্যালোচনা করব না, যেহেতু আমাদের উদ্দেশ্যে যথেষ্ট ভালো কাজ করে। আরও গভীরে যেতে আগ্রহী হলে আমি Yoshua Bengio-র একটা 2012 paper-এর 14 ও 15 পৃষ্ঠার আলোচনা এবং তাতে থাকা reference-গুলো দেখার সুপারিশ করি।
Handwriting recognition আবার: code
এই অধ্যায়ে আলোচনা করা ধারণাগুলো implement করি। আমরা একটা নতুন program network2.py গড়ব, যা অধ্যায় ১-এ গড়া program network.py-এর একটা উন্নত সংস্করণ। কিছুক্ষণ ধরে network.py না দেখে থাকলে তোমার আগের আলোচনাটা দ্রুত পড়ে নেওয়া সহায়ক হতে পারে। এটা মাত্র 74 লাইন code, এবং সহজেই বোধগম্য।
network.py-এর মতোই, network2.py-এর তারকা হলো Network class, যা দিয়ে আমরা আমাদের neural network উপস্থাপন করি। আমরা একটা Network instance-কে network-এর নিজ নিজ layer-এর sizes-এর একটা list, এবং ব্যবহার করার জন্য একটা cost-এর পছন্দ দিয়ে initialize করি — যা default-ভাবে cross-entropy:
class Network(object):
def __init__(self, sizes, cost=CrossEntropyCost):
self.num_layers = len(sizes)
self.sizes = sizes
self.default_weight_initializer()
self.cost=cost__init__ method-এর প্রথম কয়েকটা লাইন network.py-এর মতোই, এবং বেশ স্বপ্রকাশিত। কিন্তু পরের দুটো লাইন নতুন, এবং সেগুলো কী করছে তা বিস্তারিত বুঝতে হবে।
শুরু করি default_weight_initializer method পরীক্ষা করে। এটা weight initialization-এর আমাদের নতুন ও উন্নত পন্থা ব্যবহার করে। যেমন দেখেছি, ওই পন্থায় একটা neuron-এ input হওয়া weight-গুলো mean 0 ও standard deviation ভাগ neuron-এ input হওয়া connection সংখ্যার বর্গমূল সহ Gaussian random variable হিসেবে initialize করা হয়। এই method-এ আমরা bias-গুলোও mean ও standard deviation সহ Gaussian random variable দিয়ে initialize করব। এই হলো code:
def default_weight_initializer(self):
self.biases = [np.random.randn(y, 1) for y in self.sizes[1:]]
self.weights = [np.random.randn(y, x)/np.sqrt(x)
for x, y in zip(self.sizes[:-1], self.sizes[1:])]code বুঝতে মনে রাখা সাহায্য করতে পারে যে np হলো linear algebra করার জন্য Numpy library। আমরা আমাদের program-এর শুরুতে Numpy import করব। এছাড়াও খেয়াল করো আমরা neuron-এর প্রথম layer-এর জন্য কোনো bias initialize করি না। আমরা এটা করা এড়াই কারণ প্রথম layer একটা input layer, তাই কোনো bias ব্যবহৃত হবে না। আমরা network.py-এ ঠিক এটাই করেছিলাম।
default_weight_initializer-এর পরিপূরক হিসেবে আমরা একটা large_weight_initializer method-ও অন্তর্ভুক্ত করব। এই method weight ও bias-গুলো অধ্যায় ১-এর পুরনো পন্থা দিয়ে initialize করে, weight ও bias দুটোই mean ও standard deviation সহ Gaussian random variable হিসেবে। code অবশ্যই default_weight_initializer থেকে কেবল একটুখানি আলাদা:
def large_weight_initializer(self):
self.biases = [np.random.randn(y, 1) for y in self.sizes[1:]]
self.weights = [np.random.randn(y, x)
for x, y in zip(self.sizes[:-1], self.sizes[1:])]আমি large_weight_initializer method-টি বেশিরভাগ অন্তর্ভুক্ত করেছি একটা সুবিধা হিসেবে, যাতে এই অধ্যায়ের ফলগুলো অধ্যায় ১-এর ফলের সাথে তুলনা করা সহজ হয়। এটা ব্যবহারের সুপারিশ করব এমন বহু ব্যবহারিক পরিস্থিতি আমি ভাবতে পারি না!
Network-এর __init__ method-এ দ্বিতীয় নতুন জিনিস হলো আমরা এখন একটা cost attribute initialize করি। এটা কীভাবে কাজ করে তা বুঝতে চলো cross-entropy cost উপস্থাপন করতে ব্যবহৃত class-টা দেখি (Python-এর static method-এর সাথে পরিচিত না হলে তুমি @staticmethod decorator উপেক্ষা করতে পারো, এবং fn ও delta-কে সাধারণ method হিসেবে ধরতে পারো):
class CrossEntropyCost(object):
@staticmethod
def fn(a, y):
return np.sum(np.nan_to_num(-y*np.log(a)-(1-y)*np.log(1-a)))
@staticmethod
def delta(z, a, y):
return (a-y)এটা ভেঙে দেখি। প্রথম যা লক্ষ করার তা হলো cross-entropy গাণিতিকভাবে একটা function হলেও, আমরা একে একটা Python function হিসেবে নয়, একটা Python class হিসেবে implement করেছি। আমি এই পছন্দ কেন করলাম? কারণ cost আমাদের network-এ দুটো ভিন্ন ভূমিকা পালন করে। স্পষ্ট ভূমিকা হলো এটা একটা পরিমাপ যে একটা output activation a কাঙ্ক্ষিত output y-এর সাথে কতটা মেলে। এই ভূমিকা CrossEntropyCost.fn method ধরে। (প্রসঙ্গত খেয়াল করো, CrossEntropyCost.fn-এর ভেতরের np.nan_to_num call নিশ্চিত করে যে Numpy শূন্যের খুব কাছাকাছি সংখ্যার log সঠিকভাবে সামলায়।) কিন্তু cost function আমাদের network-এ প্রবেশ করার আরেকটা উপায়ও আছে। অধ্যায় ২ থেকে মনে করো backpropagation algorithm চালানোর সময় আমাদের network-এর output error হিসেব করতে হয়। output error-এর রূপ cost function-এর পছন্দের উপর নির্ভর করে: ভিন্ন cost function, output error-এর ভিন্ন রূপ। cross-entropy-র জন্য output error হলো, যেমন Equation (66)-এ দেখেছি,
এ কারণে আমরা একটা দ্বিতীয় method, CrossEntropyCost.delta সংজ্ঞায়িত করি, যার উদ্দেশ্য আমাদের network-কে বলা output error কীভাবে হিসেব করতে হয়। আর তারপর আমরা এই দুটো method-কে একটা একক class-এ বেঁধে ফেলি যাতে cost function সম্পর্কে আমাদের network-এর জানা দরকার এমন সবকিছু থাকে।
একইভাবে network2.py-এ quadratic cost function উপস্থাপন করতে একটা class-ও আছে। এটা অধ্যায় ১-এর ফলের সাথে তুলনার জন্য অন্তর্ভুক্ত করা হয়েছে, যেহেতু এগিয়ে আমরা বেশিরভাগ ক্ষেত্রে cross entropy ব্যবহার করব। code ঠিক নিচেই। QuadraticCost.fn method হলো প্রকৃত output a ও কাঙ্ক্ষিত output y-এর সাথে যুক্ত quadratic cost-এর একটা সরল হিসাব। QuadraticCost.delta কর্তৃক ফেরত মান অধ্যায় ২-এ উদ্ভব করা quadratic cost-এর output error-এর রাশি (30)-এর উপর ভিত্তি করে।
class QuadraticCost(object):
@staticmethod
def fn(a, y):
return 0.5*np.linalg.norm(a-y)**2
@staticmethod
def delta(z, a, y):
return (a-y) * sigmoid_prime(z)আমরা এখন network2.py ও network.py-এর মধ্যে মূল পার্থক্যগুলো বুঝেছি। সবই বেশ সরল ব্যাপার। আরও কিছু ছোট পরিবর্তন আছে, যেগুলো আমি নিচে আলোচনা করব, L2 regularization-এর implementation-সহ। সেখানে যাওয়ার আগে চলো network2.py-এর সম্পূর্ণ code দেখি। তোমাকে সব code বিস্তারিত পড়তে হবে না, তবে বিস্তৃত গঠন বোঝা সার্থক, এবং বিশেষত documentation string-গুলো পড়া সার্থক, যাতে তুমি বোঝো program-এর প্রতিটি অংশ কী করছে। অবশ্যই ইচ্ছেমতো গভীরে যেতেও তুমি স্বাগত! হারিয়ে গেলে নিচের প্রবন্ধ পড়া চালিয়ে যেতে পারো, এবং পরে code-এ ফিরতে পারো। যাই হোক, এই হলো code:
"""network2.py
~~~~~~~~~~~~~~
An improved version of network.py, implementing the stochastic
gradient descent learning algorithm for a feedforward neural network.
Improvements include the addition of the cross-entropy cost function,
regularization, and better initialization of network weights. Note
that I have focused on making the code simple, easily readable, and
easily modifiable. It is not optimized, and omits many desirable
features.
"""
#### Libraries
# Standard library
import json
import random
import sys
# Third-party libraries
import numpy as np
#### Define the quadratic and cross-entropy cost functions
class QuadraticCost(object):
@staticmethod
def fn(a, y):
"""Return the cost associated with an output ``a`` and desired output
``y``.
"""
return 0.5*np.linalg.norm(a-y)**2
@staticmethod
def delta(z, a, y):
"""Return the error delta from the output layer."""
return (a-y) * sigmoid_prime(z)
class CrossEntropyCost(object):
@staticmethod
def fn(a, y):
"""Return the cost associated with an output ``a`` and desired output
``y``. Note that np.nan_to_num is used to ensure numerical
stability. In particular, if both ``a`` and ``y`` have a 1.0
in the same slot, then the expression (1-y)*np.log(1-a)
returns nan. The np.nan_to_num ensures that that is converted
to the correct value (0.0).
"""
return np.sum(np.nan_to_num(-y*np.log(a)-(1-y)*np.log(1-a)))
@staticmethod
def delta(z, a, y):
"""Return the error delta from the output layer. Note that the
parameter ``z`` is not used by the method. It is included in
the method's parameters in order to make the interface
consistent with the delta method for other cost classes.
"""
return (a-y)
#### Main Network class
class Network(object):
def __init__(self, sizes, cost=CrossEntropyCost):
"""The list ``sizes`` contains the number of neurons in the respective
layers of the network. For example, if the list was [2, 3, 1]
then it would be a three-layer network, with the first layer
containing 2 neurons, the second layer 3 neurons, and the
third layer 1 neuron. The biases and weights for the network
are initialized randomly, using
``self.default_weight_initializer`` (see docstring for that
method).
"""
self.num_layers = len(sizes)
self.sizes = sizes
self.default_weight_initializer()
self.cost=cost
def default_weight_initializer(self):
"""Initialize each weight using a Gaussian distribution with mean 0
and standard deviation 1 over the square root of the number of
weights connecting to the same neuron. Initialize the biases
using a Gaussian distribution with mean 0 and standard
deviation 1.
Note that the first layer is assumed to be an input layer, and
by convention we won't set any biases for those neurons, since
biases are only ever used in computing the outputs from later
layers.
"""
self.biases = [np.random.randn(y, 1) for y in self.sizes[1:]]
self.weights = [np.random.randn(y, x)/np.sqrt(x)
for x, y in zip(self.sizes[:-1], self.sizes[1:])]
def large_weight_initializer(self):
"""Initialize the weights using a Gaussian distribution with mean 0
and standard deviation 1. Initialize the biases using a
Gaussian distribution with mean 0 and standard deviation 1.
Note that the first layer is assumed to be an input layer, and
by convention we won't set any biases for those neurons, since
biases are only ever used in computing the outputs from later
layers.
This weight and bias initializer uses the same approach as in
Chapter 1, and is included for purposes of comparison. It
will usually be better to use the default weight initializer
instead.
"""
self.biases = [np.random.randn(y, 1) for y in self.sizes[1:]]
self.weights = [np.random.randn(y, x)
for x, y in zip(self.sizes[:-1], self.sizes[1:])]
def feedforward(self, a):
"""Return the output of the network if ``a`` is input."""
for b, w in zip(self.biases, self.weights):
a = sigmoid(np.dot(w, a)+b)
return a
def SGD(self, training_data, epochs, mini_batch_size, eta,
lmbda = 0.0,
evaluation_data=None,
monitor_evaluation_cost=False,
monitor_evaluation_accuracy=False,
monitor_training_cost=False,
monitor_training_accuracy=False):
"""Train the neural network using mini-batch stochastic gradient
descent. The ``training_data`` is a list of tuples ``(x, y)``
representing the training inputs and the desired outputs. The
other non-optional parameters are self-explanatory, as is the
regularization parameter ``lmbda``. The method also accepts
``evaluation_data``, usually either the validation or test
data. We can monitor the cost and accuracy on either the
evaluation data or the training data, by setting the
appropriate flags. The method returns a tuple containing four
lists: the (per-epoch) costs on the evaluation data, the
accuracies on the evaluation data, the costs on the training
data, and the accuracies on the training data. All values are
evaluated at the end of each training epoch. So, for example,
if we train for 30 epochs, then the first element of the tuple
will be a 30-element list containing the cost on the
evaluation data at the end of each epoch. Note that the lists
are empty if the corresponding flag is not set.
"""
if evaluation_data: n_data = len(evaluation_data)
n = len(training_data)
evaluation_cost, evaluation_accuracy = [], []
training_cost, training_accuracy = [], []
for j in xrange(epochs):
random.shuffle(training_data)
mini_batches = [
training_data[k:k+mini_batch_size]
for k in xrange(0, n, mini_batch_size)]
for mini_batch in mini_batches:
self.update_mini_batch(
mini_batch, eta, lmbda, len(training_data))
print "Epoch %s training complete" % j
if monitor_training_cost:
cost = self.total_cost(training_data, lmbda)
training_cost.append(cost)
print "Cost on training data: {}".format(cost)
if monitor_training_accuracy:
accuracy = self.accuracy(training_data, convert=True)
training_accuracy.append(accuracy)
print "Accuracy on training data: {} / {}".format(
accuracy, n)
if monitor_evaluation_cost:
cost = self.total_cost(evaluation_data, lmbda, convert=True)
evaluation_cost.append(cost)
print "Cost on evaluation data: {}".format(cost)
if monitor_evaluation_accuracy:
accuracy = self.accuracy(evaluation_data)
evaluation_accuracy.append(accuracy)
print "Accuracy on evaluation data: {} / {}".format(
self.accuracy(evaluation_data), n_data)
print
return evaluation_cost, evaluation_accuracy, \
training_cost, training_accuracy
def update_mini_batch(self, mini_batch, eta, lmbda, n):
"""Update the network's weights and biases by applying gradient
descent using backpropagation to a single mini batch. The
``mini_batch`` is a list of tuples ``(x, y)``, ``eta`` is the
learning rate, ``lmbda`` is the regularization parameter, and
``n`` is the total size of the training data set.
"""
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights]
for x, y in mini_batch:
delta_nabla_b, delta_nabla_w = self.backprop(x, y)
nabla_b = [nb+dnb for nb, dnb in zip(nabla_b, delta_nabla_b)]
nabla_w = [nw+dnw for nw, dnw in zip(nabla_w, delta_nabla_w)]
self.weights = [(1-eta*(lmbda/n))*w-(eta/len(mini_batch))*nw
for w, nw in zip(self.weights, nabla_w)]
self.biases = [b-(eta/len(mini_batch))*nb
for b, nb in zip(self.biases, nabla_b)]
def backprop(self, x, y):
"""Return a tuple ``(nabla_b, nabla_w)`` representing the
gradient for the cost function C_x. ``nabla_b`` and
``nabla_w`` are layer-by-layer lists of numpy arrays, similar
to ``self.biases`` and ``self.weights``."""
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights]
# feedforward
activation = x
activations = [x] # list to store all the activations, layer by layer
zs = [] # list to store all the z vectors, layer by layer
for b, w in zip(self.biases, self.weights):
z = np.dot(w, activation)+b
zs.append(z)
activation = sigmoid(z)
activations.append(activation)
# backward pass
delta = (self.cost).delta(zs[-1], activations[-1], y)
nabla_b[-1] = delta
nabla_w[-1] = np.dot(delta, activations[-2].transpose())
# Note that the variable l in the loop below is used a little
# differently to the notation in Chapter 2 of the book. Here,
# l = 1 means the last layer of neurons, l = 2 is the
# second-last layer, and so on. It's a renumbering of the
# scheme in the book, used here to take advantage of the fact
# that Python can use negative indices in lists.
for l in xrange(2, self.num_layers):
z = zs[-l]
sp = sigmoid_prime(z)
delta = np.dot(self.weights[-l+1].transpose(), delta) * sp
nabla_b[-l] = delta
nabla_w[-l] = np.dot(delta, activations[-l-1].transpose())
return (nabla_b, nabla_w)
def accuracy(self, data, convert=False):
"""Return the number of inputs in ``data`` for which the neural
network outputs the correct result. The neural network's
output is assumed to be the index of whichever neuron in the
final layer has the highest activation.
The flag ``convert`` should be set to False if the data set is
validation or test data (the usual case), and to True if the
data set is the training data. The need for this flag arises
due to differences in the way the results ``y`` are
represented in the different data sets. In particular, it
flags whether we need to convert between the different
representations. It may seem strange to use different
representations for the different data sets. Why not use the
same representation for all three data sets? It's done for
efficiency reasons -- the program usually evaluates the cost
on the training data and the accuracy on other data sets.
These are different types of computations, and using different
representations speeds things up. More details on the
representations can be found in
mnist_loader.load_data_wrapper.
"""
if convert:
results = [(np.argmax(self.feedforward(x)), np.argmax(y))
for (x, y) in data]
else:
results = [(np.argmax(self.feedforward(x)), y)
for (x, y) in data]
return sum(int(x == y) for (x, y) in results)
def total_cost(self, data, lmbda, convert=False):
"""Return the total cost for the data set ``data``. The flag
``convert`` should be set to False if the data set is the
training data (the usual case), and to True if the data set is
the validation or test data. See comments on the similar (but
reversed) convention for the ``accuracy`` method, above.
"""
cost = 0.0
for x, y in data:
a = self.feedforward(x)
if convert: y = vectorized_result(y)
cost += self.cost.fn(a, y)/len(data)
cost += 0.5*(lmbda/len(data))*sum(
np.linalg.norm(w)**2 for w in self.weights)
return cost
def save(self, filename):
"""Save the neural network to the file ``filename``."""
data = {"sizes": self.sizes,
"weights": [w.tolist() for w in self.weights],
"biases": [b.tolist() for b in self.biases],
"cost": str(self.cost.__name__)}
f = open(filename, "w")
json.dump(data, f)
f.close()
#### Loading a Network
def load(filename):
"""Load a neural network from the file ``filename``. Returns an
instance of Network.
"""
f = open(filename, "r")
data = json.load(f)
f.close()
cost = getattr(sys.modules[__name__], data["cost"])
net = Network(data["sizes"], cost=cost)
net.weights = [np.array(w) for w in data["weights"]]
net.biases = [np.array(b) for b in data["biases"]]
return net
#### Miscellaneous functions
def vectorized_result(j):
"""Return a 10-dimensional unit vector with a 1.0 in the j'th position
and zeroes elsewhere. This is used to convert a digit (0...9)
into a corresponding desired output from the neural network.
"""
e = np.zeros((10, 1))
e[j] = 1.0
return e
def sigmoid(z):
"""The sigmoid function."""
return 1.0/(1.0+np.exp(-z))
def sigmoid_prime(z):
"""Derivative of the sigmoid function."""
return sigmoid(z)*(1-sigmoid(z))code-এর আরও আগ্রহজনক পরিবর্তনগুলোর একটা হলো L2 regularization অন্তর্ভুক্ত করা। যদিও এটা একটা বড় ধারণাগত পরিবর্তন, এটা implement করা এতটাই তুচ্ছ যে code-এ এটা মিস করা সহজ। বেশিরভাগ অংশে এতে কেবল Network.SGD method-সহ বিভিন্ন method-এ parameter lmbda পাস করা জড়িত। আসল কাজটা হয় program-এর একটা একক লাইনে, Network.update_mini_batch method-এর শেষ থেকে চতুর্থ লাইনে। সেখানেই আমরা weight decay অন্তর্ভুক্ত করতে gradient descent update rule পরিবর্তন করি। তবে পরিবর্তনটা ক্ষুদ্র হলেও এর ফলে বড় প্রভাব পড়ে!
প্রসঙ্গত, neural network-এ নতুন কৌশল implement করার সময় এটা সাধারণ। আমরা regularization আলোচনায় হাজার হাজার শব্দ ব্যয় করেছি। এটা ধারণাগতভাবে বেশ সূক্ষ্ম ও বুঝতে কঠিন। অথচ আমাদের program-এ যোগ করা ছিল তুচ্ছ! আশ্চর্যজনকভাবে প্রায়ই এমন ঘটে যে অত্যাধুনিক কৌশল code-এ ছোট পরিবর্তন দিয়ে implement করা যায়।
আমাদের code-এ আরেকটা ছোট কিন্তু গুরুত্বপূর্ণ পরিবর্তন হলো stochastic gradient descent method Network.SGD-এ কয়েকটা optional flag যোগ করা। এই flag-গুলো training_data-র উপর, বা Network.SGD-এ পাস করা যায় এমন একগুচ্ছ evaluation_data-র উপর cost ও accuracy monitor করা সম্ভব করে। আমরা এই অধ্যায়ে আগে এগুলো প্রায়ই ব্যবহার করেছি, তবে কীভাবে কাজ করে তার একটা উদাহরণ দিই, কেবল মনে করিয়ে দিতে:
>>> import mnist_loader
>>> training_data, validation_data, test_data = \
... mnist_loader.load_data_wrapper()
>>> import network2
>>> net = network2.Network([784, 30, 10], cost=network2.CrossEntropyCost)
>>> net.SGD(training_data, 30, 10, 0.5,
... lmbda = 5.0,
... evaluation_data=validation_data,
... monitor_evaluation_accuracy=True,
... monitor_evaluation_cost=True,
... monitor_training_accuracy=True,
... monitor_training_cost=True)এখানে আমরা evaluation_data-কে validation_data-তে সেট করছি। তবে আমরা test_data বা অন্য যেকোনো data set-এর performance-ও monitor করতে পারতাম। আমাদের চারটি flag-ও আছে যা আমাদের evaluation_data ও training_data দুটোর উপরই cost ও accuracy monitor করতে বলে। ওই flag-গুলো default-ভাবে False, কিন্তু এখানে আমাদের Network-এর performance monitor করতে সেগুলো চালু করা হয়েছে। তাছাড়া network2.py-এর Network.SGD method monitoring-এর ফল উপস্থাপন করে এমন একটা চার-উপাদানের tuple ফেরত দেয়। আমরা একে এভাবে ব্যবহার করতে পারি:
>>> evaluation_cost, evaluation_accuracy, \
... training_cost, training_accuracy = net.SGD(training_data, 30, 10, 0.5,
... lmbda = 5.0,
... evaluation_data=validation_data,
... monitor_evaluation_accuracy=True,
... monitor_evaluation_cost=True,
... monitor_training_accuracy=True,
... monitor_training_cost=True)তাই, যেমন, evaluation_cost হবে একটা 30-উপাদানের list যাতে প্রতিটি epoch-এর শেষে evaluation data-র cost থাকে। এই ধরনের তথ্য একটা network-এর আচরণ বুঝতে অত্যন্ত উপকারী। এটা, যেমন, network সময়ের সাথে কীভাবে শেখে তা দেখানো graph আঁকতে ব্যবহার করা যায়। আসলে এভাবেই আমি এই অধ্যায়ে আগের সব graph তৈরি করেছি। তবে খেয়াল করো, কোনো monitoring flag সেট না করা থাকলে tuple-এর সংশ্লিষ্ট উপাদানটা একটা খালি list হবে।
code-এ অন্যান্য সংযোজনের মধ্যে আছে একটা Network.save method, যা Network object-গুলো disk-এ সংরক্ষণ করে, এবং একটা function যা পরে সেগুলো আবার load করে। খেয়াল করো সংরক্ষণ ও load করা JSON ব্যবহার করে করা হয়, Python-এর pickle বা cPickle module ব্যবহার করে নয়, যেগুলো Python-এ object disk-এ ও disk থেকে সংরক্ষণ ও load করার চিরাচরিত উপায়। JSON ব্যবহার করতে pickle বা cPickle-এর চেয়ে বেশি code লাগে। আমি কেন JSON ব্যবহার করেছি তা বুঝতে কল্পনা করো ভবিষ্যতে কোনো সময়ে আমরা আমাদের Network class-কে sigmoid neuron ছাড়া অন্য neuron অনুমোদন করতে বদলানোর সিদ্ধান্ত নিলাম। ওই পরিবর্তন implement করতে আমরা সম্ভবত Network.__init__ method-এ সংজ্ঞায়িত attribute-গুলো বদলাব। আমরা যদি কেবল object-গুলো pickle করে থাকতাম তবে তা আমাদের load function-কে ব্যর্থ করত। serialization করতে JSON ব্যবহার স্পষ্টভাবে নিশ্চিত করা সহজ করে যে পুরনো Network-গুলো এখনও load হবে।
network2.py-এর code-এ আরও অনেক ছোট পরিবর্তন আছে, তবে সেগুলো সব network.py-এর সরল রূপভেদ। নিট ফল হলো আমাদের 74-লাইনের program-কে অনেক বেশি সক্ষম 152 লাইনে প্রসারিত করা।
Neural network-এর hyper-parameter কীভাবে বেছে নেব?
এখনও পর্যন্ত আমি ব্যাখ্যা করিনি learning rate , regularization parameter প্রভৃতি hyper-parameter-এর মান আমি কীভাবে বেছে নিচ্ছিলাম। আমি কেবল বেশ ভালো কাজ করে এমন মান সরবরাহ করছিলাম। বাস্তবে যখন তুমি একটা সমস্যায় neural net ব্যবহার করছ, তখন ভালো hyper-parameter খুঁজে পাওয়া কঠিন হতে পারে। কল্পনা করো, যেমন, আমাদের সবেমাত্র MNIST সমস্যার সাথে পরিচয় হয়েছে, এবং কোন hyper-parameter ব্যবহার করব সে সম্পর্কে কিছুই না জেনে কাজ শুরু করেছি। ধরো সৌভাগ্যবশত আমাদের প্রথম পরীক্ষায় আমরা এই অধ্যায়ের আগের মতোই অনেক hyper-parameter বেছে নিলাম: 30 hidden neuron, 10 mini-batch size, cross-entropy দিয়ে 30 epoch ধরে train। কিন্তু আমরা learning rate ও regularization parameter বেছে নিলাম। এমন একটা চালানোয় আমি যা দেখেছিলাম:
>>> import mnist_loader
>>> training_data, validation_data, test_data = \
... mnist_loader.load_data_wrapper()
>>> import network2
>>> net = network2.Network([784, 30, 10])
>>> net.SGD(training_data, 30, 10, 10.0, lmbda = 1000.0,
... evaluation_data=validation_data, monitor_evaluation_accuracy=True)
Epoch 0 training complete
Accuracy on evaluation data: 1030 / 10000
Epoch 1 training complete
Accuracy on evaluation data: 990 / 10000
Epoch 2 training complete
Accuracy on evaluation data: 1009 / 10000
...
Epoch 27 training complete
Accuracy on evaluation data: 1009 / 10000
Epoch 28 training complete
Accuracy on evaluation data: 983 / 10000
Epoch 29 training complete
Accuracy on evaluation data: 967 / 10000আমাদের classification accuracy দৈবের চেয়ে ভালো নয়! আমাদের network একটা random noise generator-এর মতো আচরণ করছে!
"ভালো, ওটা ঠিক করা সহজ," তুমি হয়তো বলবে, "শুধু learning rate ও regularization hyper-parameter কমিয়ে দাও"। দুর্ভাগ্যবশত, ওইগুলোই যে তোমার সমন্বয় করা দরকার এমন hyper-parameter তা তুমি a priori জানো না। হয়তো আসল সমস্যা এই যে আমাদের 30 hidden neuron-এর network কখনোই ভালো কাজ করবে না, অন্য hyper-parameter যেভাবেই বেছে নেওয়া হোক? হয়তো আমাদের সত্যিই অন্তত 100 hidden neuron দরকার? নাকি 300 hidden neuron? নাকি একাধিক hidden layer? নাকি output encode করার একটা ভিন্ন পন্থা? হয়তো আমাদের network শিখছে, কিন্তু আমাদের আরও epoch ধরে train করা দরকার? হয়তো mini-batch খুব ছোট? হয়তো quadratic cost function-এ ফিরে গেলে আমরা ভালো করতাম? হয়তো আমাদের weight initialization-এর একটা ভিন্ন পন্থা চেষ্টা করা দরকার? এভাবে চলতেই থাকে। hyper-parameter space-এ হারিয়ে যাওয়া সহজ। তোমার network খুব বড় হলে, বা প্রচুর training data ব্যবহার করলে এটা বিশেষভাবে হতাশাজনক হতে পারে, কারণ তুমি ঘণ্টা, দিন বা সপ্তাহ ধরে train করে কোনো ফল না পেতে পারো। পরিস্থিতি স্থায়ী হলে তা তোমার আত্মবিশ্বাস ক্ষতিগ্রস্ত করে। হয়তো neural network তোমার সমস্যার জন্য ভুল পন্থা? হয়তো তোমার চাকরি ছেড়ে মৌমাছি পালন শুরু করা উচিত?
এই section-এ আমি কিছু heuristic ব্যাখ্যা করব যা একটা neural network-এ hyper-parameter সেট করতে ব্যবহার করা যায়। লক্ষ্য হলো তোমাকে এমন একটা workflow গড়ে তুলতে সাহায্য করা যা তোমাকে hyper-parameter সেট করায় বেশ ভালো কাজ করতে দেয়। অবশ্যই আমি hyper-parameter optimization সম্পর্কে সবকিছু কভার করব না। এটা একটা বিশাল বিষয়, এবং যাই হোক এটা এমন একটা সমস্যা নয় যা কখনও সম্পূর্ণরূপে সমাধান হয়, কোন কৌশল ব্যবহার করা সঠিক তা নিয়ে practitioner-দের মধ্যে সর্বজনীন ঐকমত্যও নেই। তোমার network থেকে আরেকটু performance বের করতে সবসময় আরও একটা কৌশল চেষ্টা করা যায়। তবে এই section-এর heuristic-গুলো তোমাকে শুরু করিয়ে দেওয়ার কথা।
বিস্তৃত কৌশল: একটা নতুন সমস্যায় neural network ব্যবহারের সময় প্রথম চ্যালেঞ্জ হলো যেকোনো অ-তুচ্ছ শেখা পাওয়া, অর্থাৎ network-এর জন্য দৈবের চেয়ে ভালো ফল অর্জন করা। এটা আশ্চর্যজনকভাবে কঠিন হতে পারে, বিশেষত একটা নতুন শ্রেণির সমস্যার মুখোমুখি হলে। তুমি এই ধরনের সমস্যায় পড়লে কিছু কৌশল ব্যবহার করতে পারো তা দেখি।
ধরো, যেমন, তুমি প্রথমবারের মতো MNIST-এর মুখোমুখি হচ্ছ। তুমি উৎসাহের সাথে শুরু করো, কিন্তু উপরের উদাহরণের মতো তোমার প্রথম network পুরোপুরি ব্যর্থ হলে কিছুটা নিরুৎসাহ হও। এগোনোর উপায় হলো সমস্যাটা সরল করে ফেলা। 0 বা 1 ছাড়া সব training ও validation ছবি বাদ দাও। তারপর 0 থেকে 1 আলাদা করতে একটা network train করার চেষ্টা করো। এটা শুধু সব দশটা সংখ্যা আলাদা করার চেয়ে সহজাতভাবে সহজ সমস্যাই নয়, এটা training data-র পরিমাণও 80 শতাংশ কমায়, training-কে 5 গুণ দ্রুত করে। এতে অনেক বেশি দ্রুত পরীক্ষা-নিরীক্ষা করা যায়, ফলে একটা ভালো network কীভাবে গড়তে হয় সে সম্পর্কে আরও দ্রুত অন্তর্দৃষ্টি পাওয়া যায়।
তোমার network-কে অর্থপূর্ণ শেখা করতে সক্ষম সরলতম network-এ নামিয়ে এনে তুমি পরীক্ষা-নিরীক্ষায় আরও একটা গতি বৃদ্ধি পেতে পারো। তুমি যদি বিশ্বাস করো একটা [784, 10] network সম্ভবত MNIST সংখ্যার দৈব-চেয়ে-ভালো classification করতে পারে, তবে এমন একটা network দিয়ে তোমার পরীক্ষা শুরু করো। এটা একটা [784, 30, 10] network train করার চেয়ে অনেক দ্রুত হবে, এবং তুমি পরেরটায় ফিরে গড়ে তুলতে পারো।
monitoring-এর কম্পাঙ্ক বাড়িয়ে তুমি পরীক্ষা-নিরীক্ষায় আরেকটা গতি বৃদ্ধি পেতে পারো। network2.py-এ আমরা প্রতিটি training epoch-এর শেষে performance monitor করি। প্রতি epoch-এ 50,000 ছবি দিয়ে, তার মানে network কতটা ভালো শিখছে সে সম্পর্কে feedback পাওয়ার আগে কিছুক্ষণ অপেক্ষা করা — একটা [784, 30, 10] network train করার সময় আমার laptop-এ প্রতি epoch প্রায় দশ সেকেন্ড। অবশ্যই দশ সেকেন্ড খুব দীর্ঘ নয়, কিন্তু তুমি ডজনখানেক hyper-parameter পছন্দ পরখ করতে চাইলে এটা বিরক্তিকর, আর শত বা হাজার পছন্দ পরখ করতে চাইলে এটা দুর্বল করে দিতে শুরু করে। আমরা validation accuracy আরও ঘন ঘন monitor করে — ধরো প্রতি 1,000 training ছবির পর — আরও দ্রুত feedback পেতে পারি। তাছাড়া performance monitor করতে পুরো 10,000 ছবির validation set ব্যবহারের বদলে আমরা কেবল 100টি validation ছবি ব্যবহার করে অনেক দ্রুত একটা অনুমান পেতে পারি। যা গুরুত্বপূর্ণ তা হলো network যথেষ্ট ছবি দেখে যাতে প্রকৃত শেখা হয়, এবং performance-এর একটা বেশ ভালো মোটামুটি অনুমান পাওয়া যায়। অবশ্যই আমাদের program network2.py বর্তমানে এই ধরনের monitoring করে না। তবে দৃষ্টান্তের উদ্দেশ্যে একটা অনুরূপ প্রভাব অর্জনের kludge হিসেবে আমরা আমাদের training data কেবল প্রথম 1,000 MNIST training ছবিতে নামিয়ে আনব। চেষ্টা করে দেখি কী হয়। (নিচের code সরল রাখতে আমি কেবল 0 ও 1 ছবি ব্যবহারের ধারণা implement করিনি। অবশ্যই তা একটু বেশি কাজ দিয়ে করা যায়।)
>>> net = network2.Network([784, 10])
>>> net.SGD(training_data[:1000], 30, 10, 10.0, lmbda = 1000.0, \
... evaluation_data=validation_data[:100], \
... monitor_evaluation_accuracy=True)
Epoch 0 training complete
Accuracy on evaluation data: 10 / 100
Epoch 1 training complete
Accuracy on evaluation data: 10 / 100
Epoch 2 training complete
Accuracy on evaluation data: 10 / 100
...আমরা এখনও বিশুদ্ধ noise পাচ্ছি! কিন্তু একটা বড় লাভ হলো: আমরা এখন এক সেকেন্ডের ভগ্নাংশে feedback পাচ্ছি, প্রতি দশ সেকেন্ডে একবারের বদলে। তার মানে তুমি hyper-parameter-এর অন্য পছন্দ নিয়ে আরও দ্রুত পরীক্ষা করতে পারো, এমনকি প্রায় একসাথে অনেক ভিন্ন hyper-parameter পছন্দ পরখ করার পরীক্ষা চালাতে পারো।
উপরের উদাহরণে আমি -কে আগের মতোই রেখেছিলাম। কিন্তু যেহেতু আমরা training example-এর সংখ্যা বদলেছি, তাই weight decay একই রাখতে আমাদের সত্যিই বদলানো উচিত। তার মানে -কে -এ বদলানো। তা করলে এই হয়:
>>> net = network2.Network([784, 10])
>>> net.SGD(training_data[:1000], 30, 10, 10.0, lmbda = 20.0, \
... evaluation_data=validation_data[:100], \
... monitor_evaluation_accuracy=True)
Epoch 0 training complete
Accuracy on evaluation data: 12 / 100
Epoch 1 training complete
Accuracy on evaluation data: 14 / 100
Epoch 2 training complete
Accuracy on evaluation data: 25 / 100
Epoch 3 training complete
Accuracy on evaluation data: 18 / 100
...আহা! আমরা একটা signal পেয়েছি। ভয়ংকর ভালো signal নয়, তবু একটা signal। এটা এমন কিছু যার উপর আমরা গড়ে তুলতে পারি, আরও উন্নতি পেতে hyper-parameter পরিবর্তন করে। হয়তো আমরা অনুমান করি যে আমাদের learning rate আরও উঁচু হওয়া দরকার। (তুমি হয়তো বুঝতে পারছ এটা একটা বোকা অনুমান, যে কারণ আমরা শীঘ্রই আলোচনা করব, তবু একটু সহ্য করো।) তাই আমাদের অনুমান পরীক্ষা করতে আমরা -কে -তে বাড়িয়ে দেখি:
>>> net = network2.Network([784, 10])
>>> net.SGD(training_data[:1000], 30, 10, 100.0, lmbda = 20.0, \
... evaluation_data=validation_data[:100], \
... monitor_evaluation_accuracy=True)
Epoch 0 training complete
Accuracy on evaluation data: 10 / 100
Epoch 1 training complete
Accuracy on evaluation data: 10 / 100
Epoch 2 training complete
Accuracy on evaluation data: 10 / 100
Epoch 3 training complete
Accuracy on evaluation data: 10 / 100
...ওটা ভালো না! এটা ইঙ্গিত করে যে আমাদের অনুমান ভুল ছিল, এবং সমস্যা এই ছিল না যে learning rate খুব কম। তাই তার বদলে আমরা -কে -এ কমিয়ে দেখি:
>>> net = network2.Network([784, 10])
>>> net.SGD(training_data[:1000], 30, 10, 1.0, lmbda = 20.0, \
... evaluation_data=validation_data[:100], \
... monitor_evaluation_accuracy=True)
Epoch 0 training complete
Accuracy on evaluation data: 62 / 100
Epoch 1 training complete
Accuracy on evaluation data: 42 / 100
Epoch 2 training complete
Accuracy on evaluation data: 43 / 100
Epoch 3 training complete
Accuracy on evaluation data: 61 / 100
...ওটা ভালো! আর এভাবে আমরা চালিয়ে যেতে পারি, প্রতিটি hyper-parameter আলাদাভাবে সমন্বয় করে, ক্রমশ performance উন্নত করে। একবার -এর একটা উন্নত মান খুঁজে অন্বেষণ করার পর আমরা -এর একটা ভালো মান খুঁজতে এগোই। তারপর একটা আরও জটিল architecture নিয়ে পরীক্ষা করি, ধরো 10 hidden neuron-এর একটা network। তারপর ও -এর মান আবার সমন্বয় করি। তারপর 20 hidden neuron-এ বাড়াই। আর তারপর অন্য hyper-parameter আরও কিছু সমন্বয় করি। এভাবে চলতে থাকে, প্রতিটি ধাপে আমাদের hold-out করা validation data ব্যবহার করে performance মূল্যায়ন করে, এবং সেই মূল্যায়ন ব্যবহার করে ক্রমশ ভালো ও ভালো hyper-parameter খুঁজে। আমরা যত এগোই, hyper-parameter পরিবর্তনের প্রভাব দেখতে সাধারণত তত বেশি সময় লাগে, তাই আমরা ক্রমশ monitoring-এর কম্পাঙ্ক কমাতে পারি।
একটা বিস্তৃত কৌশল হিসেবে এই সবই খুব আশাব্যঞ্জক দেখায়। তবে আমি network-কে আদৌ কিছু শিখতে সক্ষম করে এমন hyper-parameter খোঁজার ওই প্রাথমিক ধাপে ফিরতে চাই। আসলে উপরের আলোচনাও খুব বেশি ইতিবাচক একটা দৃষ্টিভঙ্গি প্রকাশ করে। কিছুই না শিখছে এমন একটা network নিয়ে কাজ করা অসম্ভব হতাশাজনক হতে পারে। তুমি দিনের পর দিন hyper-parameter tweak করতে পারো, তবু কোনো অর্থপূর্ণ সাড়া পাবে না। তাই আমি আবার জোর দিতে চাই যে প্রাথমিক ধাপে তোমার নিশ্চিত করা উচিত যে তুমি পরীক্ষা থেকে দ্রুত feedback পেতে পারো। স্বজ্ঞাতভাবে মনে হতে পারে সমস্যা ও architecture সরল করা কেবল তোমাকে ধীর করবে। আসলে এটা জিনিসগুলো দ্রুত করে, কারণ তুমি একটা অর্থপূর্ণ signal-যুক্ত network অনেক দ্রুত খুঁজে পাও। একবার এমন একটা signal পেয়ে গেলে তুমি প্রায়ই hyper-parameter tweak করে দ্রুত উন্নতি পেতে পারো। জীবনের অনেক কিছুর মতোই, শুরু করাই সবচেয়ে কঠিন কাজ হতে পারে।
ঠিক আছে, এই হলো বিস্তৃত কৌশল। চলো এখন hyper-parameter সেট করার কিছু সুনির্দিষ্ট সুপারিশ দেখি। আমি learning rate , L2 regularization parameter ও mini-batch size-এ মনোযোগ দেব। তবে অনেক মন্তব্য অন্যান্য hyper-parameter-এও খাটে, network architecture-এর সাথে সংশ্লিষ্টগুলো, regularization-এর অন্য রূপ, এবং বইয়ের পরে দেখা কিছু hyper-parameter — যেমন momentum co-efficient — সহ।
Learning rate: ধরো আমরা তিনটি ভিন্ন learning rate , ও দিয়ে তিনটি MNIST network চালাই। আমরা বাকি hyper-parameter আগের section-এর পরীক্ষার মতোই সেট করব, 30 epoch ধরে চালিয়ে, 10 mini-batch size ও দিয়ে। আমরা পুরো 50,000 training ছবি ব্যবহারেও ফিরব। train করার সাথে সাথে training cost-এর আচরণ দেখানো একটা graph:
-এ cost শেষ epoch পর্যন্ত মসৃণভাবে কমে। -এ cost শুরুতে কমে, কিন্তু প্রায় 20 epoch-এর পর এটা saturation-এর কাছাকাছি, এবং এরপর বেশিরভাগ পরিবর্তন কেবল ছোট ও আপাত-random oscillation। অবশেষে -এ cost একেবারে শুরু থেকেই বড় oscillation করে। oscillation-এর কারণ বুঝতে মনে করো stochastic gradient descent-এর কথা যা আমাদের ক্রমশ cost function-এর একটা উপত্যকায় নামিয়ে দেওয়ার কথা,
তবে খুব বড় হলে পদক্ষেপগুলো এত বড় হবে যে সেগুলো আসলে minimum-কে overshoot করতে পারে, ফলে algorithm উপত্যকা থেকে আবার উপরে উঠতে শুরু করে। হলে cost-কে oscillate করানোর কারণ সম্ভবত এটাই। আমরা যখন বেছে নিই তখন শুরুর পদক্ষেপগুলো আমাদের cost function-এর একটা minimum-এর দিকে নিয়ে যায়, এবং কেবল ওই minimum-এর কাছে গেলেই আমরা overshooting সমস্যায় ভুগতে শুরু করি। আর বেছে নিলে আমরা প্রথম 30 epoch-এ এই সমস্যায় আদৌ ভুগি না। অবশ্যই এত ছোট বেছে নেওয়া আরেকটা সমস্যা তৈরি করে, যথা এটা stochastic gradient descent ধীর করে। একটা আরও ভালো পন্থা হতো দিয়ে শুরু করা, 20 epoch ধরে train করা, তারপর -এ বদলানো। এমন পরিবর্তনশীল learning rate schedule আমরা পরে আলোচনা করব। তবে আপাতত একটা একক ভালো learning rate খোঁজা বের করায় লেগে থাকি।
এই ছবি মাথায় রেখে আমরা এভাবে সেট করতে পারি। প্রথমে আমরা -এর সেই threshold মান অনুমান করি যেখানে training data-র cost oscillate বা বৃদ্ধির বদলে সাথে সাথে কমতে শুরু করে। এই অনুমান খুব নিখুঁত হওয়ার দরকার নেই। তুমি দিয়ে শুরু করে মাত্রার ক্রম অনুমান করতে পারো। প্রথম কয়েক epoch-এ cost কমলে তোমার ক্রমান্বয়ে চেষ্টা করা উচিত যতক্ষণ না এমন একটা মান পাও যেখানে cost প্রথম কয়েক epoch-এ oscillate বা বৃদ্ধি করে। বিকল্পভাবে, হলে cost প্রথম কয়েক epoch-এ oscillate বা বৃদ্ধি করলে চেষ্টা করো যতক্ষণ না এমন মান পাও যেখানে cost প্রথম কয়েক epoch-এ কমে। এই পদ্ধতি অনুসরণ করলে -এর threshold মানের একটা মাত্রার-ক্রম অনুমান পাবে। তুমি ইচ্ছে করলে তোমার অনুমান পরিমার্জন করতে পারো, সেই সর্বোচ্চ বেছে নিতে যেখানে cost প্রথম কয়েক epoch-এ কমে, ধরো বা ।
স্পষ্টতই তুমি যে ব্যবহার করো তা threshold মানের চেয়ে বড় হওয়া উচিত নয়। আসলে -এর মান অনেক epoch-এ ব্যবহারযোগ্য থাকতে হলে তুমি সম্ভবত threshold-এর চেয়ে ছোট একটা মান, ধরো দুই গুণ কম, ব্যবহার করতে চাইবে। এমন পছন্দ সাধারণত তোমাকে শেখায় খুব বেশি মন্থরতা না ঘটিয়ে অনেক epoch ধরে train করতে দেবে।
MNIST data-র ক্ষেত্রে এই কৌশল অনুসরণ করলে -এর threshold মানের মাত্রার ক্রমের জন্য -এর একটা অনুমানে পৌঁছায়। আরও কিছু পরিমার্জনের পর আমরা একটা threshold মান পাই। উপরের নির্দেশ অনুসরণ করে এটা learning rate হিসেবে ব্যবহারের ইঙ্গিত দেয়। আসলে আমি দেখেছি 30 epoch-এ যথেষ্ট ভালো কাজ করেছে যে বেশিরভাগ ক্ষেত্রে আমি -এর একটা কম মান ব্যবহার নিয়ে দুশ্চিন্তা করিনি।
এই সবই বেশ সরল মনে হয়। তবে বাছতে training cost ব্যবহার করা এই section-এ আগে যা বলেছিলাম তার সাথে সাংঘর্ষিক মনে হয়, যথা আমরা hold-out করা validation data ব্যবহার করে performance মূল্যায়নের মাধ্যমে hyper-parameter বাছব। আসলে আমরা regularization hyper-parameter, mini-batch size, এবং layer ও hidden neuron সংখ্যার মতো network parameter বাছতে validation accuracy ব্যবহার করব। তাহলে learning rate-এর জন্য ভিন্নভাবে করি কেন? সত্যি বলতে এই পছন্দ আমার ব্যক্তিগত নান্দনিক পছন্দ, এবং হয়তো কিছুটা খামখেয়ালি। যুক্তি হলো অন্য hyper-parameter-গুলো test set-এ চূড়ান্ত classification accuracy উন্নত করার উদ্দেশ্যে, তাই validation accuracy-র ভিত্তিতে সেগুলো নির্বাচন করা যুক্তিসঙ্গত। তবে learning rate কেবল আনুষঙ্গিকভাবে চূড়ান্ত classification accuracy প্রভাবিত করার উদ্দেশ্যে। এর মূল উদ্দেশ্য আসলে gradient descent-এ পদক্ষেপের আকার নিয়ন্ত্রণ করা, এবং পদক্ষেপের আকার খুব বড় কিনা তা সনাক্ত করার সেরা উপায় training cost monitor করা। তা সত্ত্বেও, এটা একটা ব্যক্তিগত নান্দনিক পছন্দ। শেখার শুরুর দিকে training cost সাধারণত কেবল তখনই কমে যখন validation accuracy উন্নত হয়, তাই বাস্তবে তুমি কোন মাপকাঠি ব্যবহার করো তাতে খুব বেশি পার্থক্য হওয়ার সম্ভাবনা কম।
Training epoch-এর সংখ্যা নির্ধারণে early stopping ব্যবহার করো: যেমন এই অধ্যায়ে আগে আলোচনা করেছি, early stopping মানে প্রতিটি epoch-এর শেষে আমরা validation data-র উপর classification accuracy হিসেব করব। তা উন্নত হওয়া থামালে terminate করো। এটা epoch-এর সংখ্যা সেট করা খুব সরল করে দেয়। বিশেষত এর মানে আমাদের epoch-এর সংখ্যা অন্য hyper-parameter-এর উপর কীভাবে নির্ভর করে তা স্পষ্টভাবে বের করা নিয়ে দুশ্চিন্তা করতে হয় না। তার বদলে তা স্বয়ংক্রিয়ভাবে সামলানো হয়। তাছাড়া early stopping আমাদের স্বয়ংক্রিয়ভাবে overfitting থেকেও বাঁচায়। এটা অবশ্যই একটা ভালো ব্যাপার, যদিও পরীক্ষা-নিরীক্ষার শুরুর ধাপে early stopping বন্ধ রাখা সহায়ক হতে পারে, যাতে তুমি overfitting-এর যেকোনো লক্ষণ দেখতে পারো, এবং তা regularization-এ তোমার পন্থা ঠিক করতে ব্যবহার করতে পারো।
early stopping implement করতে আমাদের আরও সুনির্দিষ্টভাবে বলতে হবে classification accuracy উন্নত হওয়া থেমেছে বলতে কী বোঝায়। যেমন দেখেছি, সামগ্রিক ঝোঁক উন্নতির দিকে হলেও accuracy বেশ খানিকটা লাফালাফি করতে পারে। accuracy প্রথমবার কমলেই আমরা থেমে গেলে আমরা প্রায় নিশ্চিতভাবে এমন সময়ে থামব যখন আরও উন্নতি পাওয়ার ছিল। একটা ভালো নিয়ম হলো terminate করা যদি সেরা classification accuracy বেশ কিছু সময় ধরে উন্নত না হয়। ধরো, যেমন, আমরা MNIST করছি। তখন আমরা terminate করতে পারি যদি গত দশ epoch-এ classification accuracy উন্নত না হয়। এটা নিশ্চিত করে আমরা training-এ দুর্ভাগ্যের সাড়া দিয়ে খুব তাড়াতাড়ি থামি না, কিন্তু কখনও না আসা একটা উন্নতির জন্য চিরকাল অপেক্ষাও করি না।
এই দশ-epoch-এ-কোনো-উন্নতি-নেই নিয়মটা MNIST-এর প্রাথমিক অন্বেষণের জন্য ভালো। তবে network কখনও কখনও বেশ কিছু সময় ধরে একটা নির্দিষ্ট classification accuracy-র কাছে মালভূমিতে থাকতে পারে, কেবল তারপর আবার উন্নত হতে শুরু করে। তুমি সত্যিই ভালো performance পেতে চাইলে দশ-এ-কোনো-উন্নতি-নেই নিয়ম থামানোর ব্যাপারে খুব আক্রমণাত্মক হতে পারে। সেক্ষেত্রে আমি প্রাথমিক পরীক্ষা-নিরীক্ষার জন্য দশ-এ-কোনো-উন্নতি-নেই নিয়ম ব্যবহার করার এবং তোমার network কীভাবে train হয় তা ভালো বোঝার সাথে সাথে ক্রমশ আরও নমনীয় নিয়ম গ্রহণ করার সুপারিশ করি: বিশ-এ-কোনো-উন্নতি-নেই, পঞ্চাশ-এ-কোনো-উন্নতি-নেই, এভাবে। অবশ্যই এটা optimize করার একটা নতুন hyper-parameter চালু করে! তবে বাস্তবে বেশ ভালো ফল পেতে এই hyper-parameter সেট করা সাধারণত সহজ।
আমরা এখনও পর্যন্ত আমাদের MNIST পরীক্ষায় early stopping ব্যবহার করিনি। কারণ আমরা শেখার বিভিন্ন পন্থার মধ্যে অনেক তুলনা করছিলাম। এমন তুলনার জন্য প্রতিটি ক্ষেত্রে একই সংখ্যক epoch ব্যবহার করা সহায়ক। তবে early stopping implement করতে network2.py পরিবর্তন করা খুবই সার্থক:
Learning rate schedule: আমরা learning rate ধ্রুব রাখছিলাম। তবে learning rate পরিবর্তন করা প্রায়ই সুবিধাজনক। শেখার প্রক্রিয়ার শুরুর দিকে weight-গুলো বাজেভাবে ভুল হওয়ার সম্ভাবনা থাকে। তাই একটা বড় learning rate ব্যবহার করা ভালো যা weight দ্রুত বদলায়। পরে আমরা যখন আমাদের weight-এ আরও সূক্ষ্ম সমন্বয় করি তখন learning rate কমাতে পারি।
আমাদের learning rate schedule কীভাবে সেট করা উচিত? অনেক পন্থা সম্ভব। একটা স্বাভাবিক পন্থা হলো early stopping-এর মতো একই মৌলিক ধারণা ব্যবহার করা। ধারণাটা হলো validation accuracy খারাপ হতে শুরু করা পর্যন্ত learning rate ধ্রুব রাখা। তারপর learning rate কিছু পরিমাণে, ধরো দুই বা দশ গুণ কমানো। আমরা এটা বহুবার পুনরাবৃত্তি করি, যতক্ষণ না, ধরো, learning rate শুরুর মানের 1,024 (বা 1,000) গুণ কম হয়। তারপর আমরা terminate করি।
একটা পরিবর্তনশীল learning schedule performance উন্নত করতে পারে, তবে এটা learning schedule-এর সম্ভাব্য পছন্দের একটা জগৎও খুলে দেয়। ওই পছন্দগুলো একটা মাথাব্যথা হতে পারে — তুমি তোমার learning schedule optimize করার চেষ্টায় চিরকাল কাটিয়ে দিতে পারো। প্রথম পরীক্ষার জন্য আমার সুপারিশ হলো learning rate-এর জন্য একটা একক, ধ্রুব মান ব্যবহার করা। সেটা তোমাকে একটা ভালো প্রথম আনুমানিক দেবে। পরে, তোমার network থেকে সেরা performance পেতে চাইলে, আমি বর্ণিত ধাঁচে একটা learning schedule নিয়ে পরীক্ষা করা সার্থক।
Regularization parameter : আমি শুরুতে কোনো regularization ছাড়া () শুরু করার এবং উপরের মতো -এর একটা মান নির্ধারণের সুপারিশ করি। -এর ওই পছন্দ ব্যবহার করে আমরা তারপর -এর একটা ভালো মান নির্বাচন করতে validation data ব্যবহার করতে পারি। পরখ করে শুরু করো, এবং তারপর validation data-র উপর performance উন্নত করতে যেমন প্রয়োজন -এর গুণিতকে বাড়াও বা কমাও। একবার একটা ভালো মাত্রার ক্রম খুঁজে পেলে তুমি তোমার -এর মান সূক্ষ্মভাবে tune করতে পারো। তা হয়ে গেলে তোমার ফিরে আবার পুনরায় optimize করা উচিত।
এই বইয়ে আগে আমি কীভাবে hyper-parameter নির্বাচন করেছিলাম: তুমি এই section-এর সুপারিশ ব্যবহার করলে দেখবে যে ও -এর জন্য পাওয়া মান বইয়ে আগে আমি ব্যবহার করা মানের সাথে সবসময় হুবহু মেলে না। কারণ বইয়ের কিছু আখ্যানগত সীমাবদ্ধতা আছে যা কখনও কখনও hyper-parameter optimize করা অবাস্তব করে তুলেছে। শেখার বিভিন্ন পন্থার আমরা যত তুলনা করেছি তা ভাবো, যেমন quadratic ও cross-entropy cost function তুলনা করা, weight initialization-এর পুরনো ও নতুন পদ্ধতি তুলনা করা, regularization সহ ও ছাড়া চালানো, ইত্যাদি। এমন তুলনা অর্থপূর্ণ করতে আমি সাধারণত তুলনা করা পন্থাগুলো জুড়ে hyper-parameter ধ্রুব রাখার (বা উপযুক্তভাবে স্কেল করার) চেষ্টা করেছি। অবশ্যই শেখার সব ভিন্ন পন্থার জন্য একই hyper-parameter optimal হওয়ার কোনো কারণ নেই, তাই আমি যে hyper-parameter ব্যবহার করেছি তা একরকম আপস।
এই আপসের বিকল্প হিসেবে আমি শেখার প্রতিটি একক পন্থার জন্য hyper-parameter সর্বোচ্চ মাত্রায় optimize করার চেষ্টা করতে পারতাম। নীতিগতভাবে সেটা একটা ভালো, ন্যায্য পন্থা হতো, কারণ তখন আমরা শেখার প্রতিটি পন্থার সেরাটা দেখতাম। তবে আমরা এই ধাঁচে ডজনখানেক তুলনা করেছি, এবং বাস্তবে আমি তা computationally খুব ব্যয়বহুল পেয়েছি। সে কারণেই আমি hyper-parameter-এর জন্য বেশ ভালো (কিন্তু অগত্যা optimal নয়) পছন্দ ব্যবহারের আপস গ্রহণ করেছি।
Mini-batch size: mini-batch size কীভাবে সেট করা উচিত? এই প্রশ্নের উত্তর দিতে প্রথমে ধরি আমরা online learning করছি, অর্থাৎ একটা mini-batch size ব্যবহার করছি।
online learning সম্পর্কে স্পষ্ট দুশ্চিন্তা হলো কেবল একটা মাত্র training example ধারণকারী mini-batch ব্যবহার করলে gradient-এর আমাদের অনুমানে উল্লেখযোগ্য error হবে। তবে আসলে দেখা যায় error তেমন সমস্যা নয়। কারণ পৃথক gradient অনুমানগুলোকে অতি-নিখুঁত হতে হবে না। আমাদের যা দরকার তা হলো একটা অনুমান যা যথেষ্ট নিখুঁত যাতে আমাদের cost function কমতে থাকার প্রবণতা রাখে। এ যেন তুমি North Magnetic Pole-এ পৌঁছানোর চেষ্টা করছ, কিন্তু তোমার একটা গোলমেলে compass আছে যা প্রতিবার তাকালে 10-20 ডিগ্রি বিচ্যুত। তুমি যদি ঘন ঘন compass পরীক্ষা করতে থামো, এবং compass গড়ে দিকটা ঠিক দেয়, তবে তুমি ঠিকঠাকই North Magnetic Pole-এ পৌঁছে যাবে।
এই যুক্তির ভিত্তিতে মনে হয় আমাদের online learning ব্যবহার করা উচিত। আসলে পরিস্থিতি এর চেয়ে জটিল বলে দেখা যায়। গত অধ্যায়ের একটা সমস্যায় আমি উল্লেখ করেছিলাম যে একটা mini-batch-এর সব example-এর জন্য gradient update একসাথে হিসেব করতে matrix কৌশল ব্যবহার করা সম্ভব, তাদের উপর loop করার বদলে। তোমার hardware ও linear algebra library-র বিস্তারিতের উপর নির্ভর করে এতে (যেমন) 100 আকারের একটা mini-batch-এর জন্য gradient অনুমান হিসেব করা — 100টি training example-এর উপর আলাদাভাবে loop করে mini-batch gradient অনুমান হিসেব করার চেয়ে — বেশ খানিকটা দ্রুত হতে পারে। এতে হয়তো (ধরো) 100 গুণ সময়ের বদলে কেবল 50 গুণ সময় লাগবে।
এখন প্রথমে মনে হয় এটা আমাদের তেমন সাহায্য করে না। আমাদের 100 আকারের mini-batch-এর সাথে weight-এর learning rule দেখায়:
যেখানে যোগফল mini-batch-এর training example-গুলোর উপর। এর বিপরীতে online learning-এর জন্য:
mini-batch update করতে 50 গুণ সময় লাগলেও মনে হয় online learning করা ভালো হওয়ার সম্ভাবনা বেশি, কারণ আমরা অনেক বেশি ঘন ঘন update করছি। তবে ধরো mini-batch-এর ক্ষেত্রে আমরা learning rate একটা factor-এ বাড়াই, যাতে update rule দাঁড়ায়:
এটা learning rate দিয়ে online learning-এর 100টি আলাদা instance করার অনেকটা মতো। কিন্তু এতে online learning-এর একটা একক instance করার চেয়ে কেবল 50 গুণ সময় লাগে। অবশ্যই এটা সত্যিকার অর্থে online learning-এর 100টি instance-এর সমান নয়, কারণ mini-batch-এ -গুলো সবই একই সেট weight-এর জন্য মূল্যায়িত হয়, online ক্ষেত্রে ঘটা ক্রমবর্ধমান শেখার বিপরীতে। তবু এটা স্পষ্টভাবে সম্ভব মনে হয় যে বড় mini-batch ব্যবহার জিনিসগুলো দ্রুত করবে।
এই বিষয়গুলো মাথায় রেখে, সেরা mini-batch size বাছাই একটা আপস। খুব ছোট হলে তুমি দ্রুত hardware-এর জন্য optimize করা ভালো matrix library-র সুবিধার পূর্ণ ফায়দা নিতে পারো না। খুব বড় হলে তুমি কেবল তোমার weight যথেষ্ট ঘন ঘন update করছ না। তোমার যা দরকার তা হলো এমন একটা আপস মান বাছা যা শেখার গতি সর্বাধিক করে। সৌভাগ্যবশত যে mini-batch size-এ গতি সর্বাধিক হয় তা অন্য hyper-parameter (সামগ্রিক architecture বাদে) থেকে অপেক্ষাকৃত স্বাধীন, তাই একটা ভালো mini-batch size খুঁজতে তোমার ওই hyper-parameter optimize করা থাকার দরকার নেই। তাই এগোনোর উপায় হলো অন্য hyper-parameter-এর জন্য কিছু গ্রহণযোগ্য (কিন্তু অগত্যা optimal নয়) মান ব্যবহার করা, এবং তারপর উপরের মতো স্কেল করে কয়েকটা ভিন্ন mini-batch size পরখ করা। validation accuracy বনাম সময় (অর্থাৎ প্রকৃত অতিবাহিত সময়, epoch নয়!) plot করো, এবং যে mini-batch size তোমাকে performance-এ দ্রুততম উন্নতি দেয় তা বেছে নাও। mini-batch size বেছে নিয়ে তুমি তারপর অন্য hyper-parameter optimize করায় এগোতে পারো।
অবশ্যই, তুমি নিশ্চয়ই বুঝে গেছ, আমি আমাদের কাজে এই optimization করিনি। আসলে আমাদের implementation mini-batch update-এর দ্রুততর পন্থা আদৌ ব্যবহার করে না। আমি প্রায় সব উদাহরণে কোনো মন্তব্য বা ব্যাখ্যা ছাড়াই কেবল mini-batch size ব্যবহার করেছি। এ কারণে আমরা mini-batch size কমিয়ে শেখা দ্রুত করতে পারতাম। আমি এটা করিনি, আংশিক কারণ আমি -এর বেশি আকারের mini-batch-এর ব্যবহার দেখাতে চেয়েছিলাম, এবং আংশিক কারণ আমার প্রাথমিক পরীক্ষা ইঙ্গিত করেছিল গতি বৃদ্ধি বেশ সামান্য হবে। তবে ব্যবহারিক implementation-এ আমরা প্রায় নিশ্চিতভাবে mini-batch update-এর দ্রুততর পন্থা implement করব, এবং তারপর আমাদের সামগ্রিক গতি সর্বাধিক করতে mini-batch size optimize করার চেষ্টা করব।
স্বয়ংক্রিয় কৌশল: আমি এই heuristic-গুলো এমনভাবে বর্ণনা করছিলাম যেন তুমি তোমার hyper-parameter হাতে-কলমে optimize করছ। হাতে-optimization neural network কীভাবে আচরণ করে সে সম্পর্কে অনুভূতি গড়ে তোলার একটা ভালো উপায়। তবে, অবাক করার মতো কিছু নয়, প্রক্রিয়াটা স্বয়ংক্রিয় করায় প্রচুর কাজ হয়েছে। একটা সাধারণ কৌশল হলো grid search, যা পদ্ধতিগতভাবে hyper-parameter space-এ একটা grid-এর মধ্য দিয়ে খোঁজে। grid search-এর অর্জন ও সীমাবদ্ধতা উভয়ের একটা পর্যালোচনা (সহজে-implement করা যায় এমন বিকল্পের সুপারিশসহ) James Bergstra ও Yoshua Bengio-র একটা 2012 paper-এ পাওয়া যায়। আরও অনেক অত্যাধুনিক পন্থাও প্রস্তাব করা হয়েছে। আমি এখানে সেই সব কাজ পর্যালোচনা করব না, তবে একটা বিশেষভাবে আশাব্যঞ্জক 2012 paper উল্লেখ করতে চাই যা hyper-parameter স্বয়ংক্রিয়ভাবে optimize করতে একটা Bayesian পন্থা ব্যবহার করেছিল। paper-এর code সর্বজনীনভাবে উপলব্ধ, এবং অন্য গবেষকরা কিছু সাফল্যের সাথে এটা ব্যবহার করেছেন।
সারসংক্ষেপ: আমি বর্ণিত বুড়ো-আঙুলের নিয়মগুলো অনুসরণ করলে তোমার neural network থেকে একেবারে সেরা সম্ভাব্য ফল পাবে না। তবে এটা সম্ভবত তোমাকে একটা ভালো শুরু এবং আরও উন্নতির ভিত্তি দেবে। বিশেষত আমি hyper-parameter-গুলো বেশিরভাগ স্বাধীনভাবে আলোচনা করেছি। বাস্তবে hyper-parameter-গুলোর মধ্যে সম্পর্ক আছে। তুমি নিয়ে পরীক্ষা করতে পারো, মনে করতে পারো তুমি ঠিকঠাক পেয়েছ, তারপর -এর জন্য optimize করা শুরু করতে পারো, কেবল দেখতে যে এটা তোমার -এর optimization গোলমাল করে দিচ্ছে। বাস্তবে সামনে-পেছনে দোল খাওয়া সাহায্য করে, ক্রমশ ভালো মানের দিকে এগোয়। সর্বোপরি মনে রেখো আমি বর্ণিত heuristic-গুলো বুড়ো আঙুলের নিয়ম, পাথরে খোদাই করা নিয়ম নয়। জিনিসগুলো কাজ না করার লক্ষণের প্রতি তোমার সজাগ থাকা উচিত, এবং পরীক্ষা করতে ইচ্ছুক হওয়া উচিত। বিশেষত এর মানে তোমার network-এর আচরণ, বিশেষত validation accuracy, সতর্কভাবে monitor করা।
hyper-parameter বাছার এই কঠিনতা আরও বেড়ে যায় এই কারণে যে hyper-parameter কীভাবে বাছতে হয় সে সম্পর্কে জ্ঞান অনেক research paper ও software program জুড়ে ছড়িয়ে আছে, এবং প্রায়ই কেবল পৃথক practitioner-দের মাথার ভেতরেই পাওয়া যায়। কীভাবে এগোতে হয় সে সম্পর্কে (কখনও কখনও পরস্পরবিরোধী) সুপারিশ দেওয়া অনেক, অনেক paper আছে। তবে কয়েকটা বিশেষভাবে উপকারী paper আছে যেগুলো এই জ্ঞানের অনেকটা সংশ্লেষণ ও পাতন করে। Yoshua Bengio-র একটা 2012 paper আছে যা neural network — deep neural net-সহ — train করতে backpropagation ও gradient descent ব্যবহারের কিছু ব্যবহারিক সুপারিশ দেয়। আরেকটা ভালো paper হলো Yann LeCun, Léon Bottou, Genevieve Orr ও Klaus-Robert Müller-এর একটা 1998 paper। এই দুটো paper-ই একটা অত্যন্ত উপকারী 2012 বইয়ে আছে যা neural net-এ সাধারণভাবে ব্যবহৃত অনেক কৌশল সংগ্রহ করে।
এই নিবন্ধগুলো পড়লে এবং বিশেষত নিজের পরীক্ষায় জড়িত হলে যা স্পষ্ট হয়ে ওঠে তা হলো hyper-parameter optimization এমন একটা সমস্যা নয় যা কখনও সম্পূর্ণরূপে সমাধান হয়। performance উন্নত করতে সবসময় আরেকটা কৌশল চেষ্টা করার থাকে। লেখকদের মধ্যে একটা প্রচলিত কথা আছে যে বই কখনও শেষ হয় না, কেবল পরিত্যাগ করা হয়। neural network optimization-এর ক্ষেত্রেও তা সত্যি: hyper-parameter-এর space এত বড় যে কেউ আসলে কখনও optimize করা শেষ করে না, কেবল network-কে পরবর্তী প্রজন্মের জন্য পরিত্যাগ করে। তাই তোমার লক্ষ্য হওয়া উচিত এমন একটা workflow গড়ে তোলা যা তোমাকে optimization-এ দ্রুত একটা বেশ ভালো কাজ করতে দেয়, এবং তা গুরুত্বপূর্ণ হলে আরও বিস্তারিত optimization চেষ্টা করার নমনীয়তা রেখে দেয়।
hyper-parameter সেট করার চ্যালেঞ্জ কিছু মানুষকে অভিযোগ করতে বাধ্য করেছে যে অন্যান্য machine learning কৌশলের তুলনায় neural network-এ অনেক কাজ লাগে। আমি নিচের অভিযোগের অনেক রূপ শুনেছি: "হ্যাঁ, একটা ভালোভাবে-tune করা neural network হয়তো সমস্যায় সেরা performance পাবে। অন্যদিকে আমি একটা random forest [বা SVM বা... তোমার নিজের প্রিয় কৌশল বসাও] চেষ্টা করতে পারি আর এটা কেবল কাজ করে। সঠিক neural network বের করার সময় আমার নেই।" অবশ্যই ব্যবহারিক দৃষ্টিকোণ থেকে সহজে-প্রয়োগ করা যায় এমন কৌশল থাকা ভালো। এটা বিশেষভাবে সত্যি যখন তুমি সবেমাত্র একটা সমস্যায় শুরু করছ, এবং machine learning সমস্যাটা আদৌ সমাধানে সাহায্য করতে পারে কিনা তা স্পষ্ট না-ও হতে পারে। অন্যদিকে optimal performance পাওয়া গুরুত্বপূর্ণ হলে তোমার এমন পন্থা চেষ্টা করতে হতে পারে যাতে আরও বিশেষজ্ঞ জ্ঞান লাগে। machine learning সবসময় সহজ হলে ভালো হতো, তবে এটা তুচ্ছভাবে সরল হওয়ার কোনো a priori কারণ নেই।
অন্যান্য কৌশল
এই অধ্যায়ে গড়ে তোলা প্রতিটি কৌশল নিজে থেকেই জানা মূল্যবান, তবে সেগুলো ব্যাখ্যা করার এটাই একমাত্র কারণ নয়। বড় উদ্দেশ্য হলো তোমাকে neural network-এ ঘটতে পারে এমন কিছু সমস্যার সাথে, এবং সেই সমস্যা কাটিয়ে উঠতে সাহায্যকারী একটা বিশ্লেষণ-ধাঁচের সাথে পরিচিত করানো। একরকম অর্থে আমরা neural net সম্পর্কে কীভাবে ভাবতে হয় তা শিখছিলাম। এই অধ্যায়ের বাকি অংশে আমি আরও কয়েকটা কৌশলের সংক্ষিপ্ত রূপরেখা দেব। এই রূপরেখাগুলো আগের আলোচনার চেয়ে কম গভীর, তবে neural network-এ ব্যবহারের জন্য উপলব্ধ কৌশলের বৈচিত্র্যের কিছুটা অনুভূতি দেওয়ার কথা।
Stochastic gradient descent-এর রূপভেদ
backpropagation দিয়ে stochastic gradient descent MNIST সংখ্যা classification সমস্যা সামলায় আমাদের ভালোই কাজ দিয়েছে। তবে cost function optimize করার আরও অনেক পন্থা আছে, এবং কখনও কখনও সেই পন্থাগুলো mini-batch stochastic gradient descent-এর চেয়ে শ্রেষ্ঠ performance দেয়। এই section-এ আমি এমন দুটো পন্থার রূপরেখা দেব, Hessian ও momentum কৌশল।
Hessian কৌশল: আমাদের আলোচনা শুরু করতে কিছুক্ষণের জন্য neural network একপাশে রাখা সাহায্য করে। তার বদলে আমরা কেবল একটা cost function minimize করার বিমূর্ত সমস্যা বিবেচনা করব, যা অনেক variable -এর একটা function, তাই । Taylor-এর উপপাদ্য অনুসারে cost function-কে একটা বিন্দু -এর কাছে আনুমানিক করা যায়:
একে আরও সংক্ষিপ্তভাবে আবার লিখতে পারি:
যেখানে হলো চিরাচরিত gradient vector, আর হলো একটা matrix যা Hessian matrix নামে পরিচিত, যার -তম entry হলো । ধরো আমরা উপরের দ্বারা উপস্থাপিত উচ্চতর-ক্রমের পদ বাদ দিয়ে -কে আনুমানিক করি:
calculus ব্যবহার করে আমরা দেখাতে পারি যে ডান দিকের রাশিটি minimize করা যায় (কঠোরভাবে বললে, এটা একটা minimum, নিছক একটা extremum নয়, হওয়ার জন্য আমাদের ধরে নিতে হবে যে Hessian matrix positive definite — স্বজ্ঞাতভাবে এর মানে function স্থানীয়ভাবে একটা উপত্যকার মতো দেখায়, পাহাড় বা saddle-এর মতো নয়) এই বেছে নিয়ে:
(105) cost function-এর জন্য একটা ভালো আনুমানিক রাশি হলে আমরা প্রত্যাশা করব যে বিন্দু থেকে -এ সরলে cost function উল্লেখযোগ্যভাবে কমবে। এটা cost minimize করার একটা সম্ভাব্য algorithm-এর ইঙ্গিত দেয়:
- একটা শুরুর বিন্দু বেছে নাও।
- -কে একটা নতুন বিন্দু -এ update করো, যেখানে Hessian ও -এ হিসেব করা।
- -কে একটা নতুন বিন্দু -এ update করো, যেখানে Hessian ও -এ হিসেব করা।
বাস্তবে (105) কেবল একটা আনুমানিক, আর ছোট পদক্ষেপ নেওয়া ভালো। আমরা এটা করি বারবার -কে একটা পরিমাণ দিয়ে বদলে, যেখানে learning rate নামে পরিচিত।
cost function minimize করার এই পন্থা Hessian কৌশল বা Hessian optimization নামে পরিচিত। তত্ত্বীয় ও অভিজ্ঞতাগত ফল আছে যা দেখায় Hessian পদ্ধতি standard gradient descent-এর চেয়ে কম পদক্ষেপে একটা minimum-এ converge করে। বিশেষত cost function-এর দ্বিতীয়-ক্রমের পরিবর্তন সম্পর্কে তথ্য অন্তর্ভুক্ত করে Hessian পন্থার পক্ষে gradient descent-এ ঘটতে পারে এমন অনেক রোগ এড়ানো সম্ভব। তাছাড়া backpropagation algorithm-এর এমন সংস্করণ আছে যা Hessian হিসেব করতে ব্যবহার করা যায়।
Hessian optimization এত চমৎকার হলে আমরা আমাদের neural network-এ এটা ব্যবহার করছি না কেন? দুর্ভাগ্যবশত এর অনেক কাঙ্ক্ষিত ধর্ম থাকলেও এর একটা খুব অবাঞ্ছিত ধর্ম আছে: বাস্তবে এটা প্রয়োগ করা খুব কঠিন। সমস্যার একটা অংশ হলো Hessian matrix-এর নিছক আকার। ধরো তোমার একটা neural network আছে যার টি weight ও bias। তখন সংশ্লিষ্ট Hessian matrix-এ টি entry থাকবে। অনেক entry! আর তা হিসেব করা বাস্তবে অত্যন্ত কঠিন করে তোলে। তবে এর মানে এই নয় যে এটা বোঝা উপকারী নয়। আসলে gradient descent-এর অনেক রূপভেদ আছে যেগুলো Hessian optimization দ্বারা অনুপ্রাণিত, কিন্তু অতি-বড় matrix-এর সমস্যা এড়ায়। এমন একটা কৌশল দেখি, momentum-based gradient descent।
Momentum-based gradient descent: স্বজ্ঞাতভাবে, Hessian optimization-এর সুবিধা হলো এটা কেবল gradient সম্পর্কে নয়, gradient কীভাবে বদলাচ্ছে সে সম্পর্কেও তথ্য অন্তর্ভুক্ত করে। Momentum-based gradient descent একটা অনুরূপ স্বজ্ঞার উপর ভিত্তি করে, তবে দ্বিতীয় derivative-এর বড় matrix এড়ায়। momentum কৌশল বুঝতে gradient descent-এর আমাদের মূল ছবিতে ফিরে ভাবো, যেখানে আমরা একটা উপত্যকায় গড়িয়ে নামা একটা বল বিবেচনা করেছিলাম। তখন আমরা লক্ষ করেছিলাম যে gradient descent, নাম যাই হোক, একটা উপত্যকার তলায় পড়া বলের সাথে কেবল ঢিলেঢালাভাবে সদৃশ। momentum কৌশল gradient descent-কে দুটো উপায়ে পরিবর্তন করে যা একে ভৌত ছবির সাথে আরও সদৃশ করে। প্রথমত, এটা আমরা যে parameter optimize করার চেষ্টা করছি তার জন্য একটা "velocity"-র ধারণা চালু করে। gradient (সরাসরি) "অবস্থান" নয়, velocity বদলায়, অনেকটা যেমন ভৌত বল velocity বদলায়, এবং অবস্থানকে কেবল পরোক্ষভাবে প্রভাবিত করে। দ্বিতীয়ত, momentum পদ্ধতি এক ধরনের ঘর্ষণ পদ চালু করে, যা velocity ক্রমশ কমানোর প্রবণতা রাখে।
একটা আরও সুনির্দিষ্ট গাণিতিক বর্ণনা দিই। আমরা velocity variable চালু করি, প্রতিটি সংশ্লিষ্ট variable-এর জন্য একটা করে। তারপর আমরা gradient descent update rule -কে এর দ্বারা প্রতিস্থাপন করি:
এই সমীকরণগুলোতে একটা hyper-parameter যা system-এ damping বা ঘর্ষণের পরিমাণ নিয়ন্ত্রণ করে। সমীকরণের অর্থ বুঝতে প্রথমে ক্ষেত্র বিবেচনা করা সাহায্য করে, যা কোনো ঘর্ষণ নেই-এর সাথে মেলে। তেমন হলে সমীকরণ পরীক্ষা করলে দেখা যায় "বল" এখন velocity বদলাচ্ছে, আর velocity -এর পরিবর্তনের হার নিয়ন্ত্রণ করছে। স্বজ্ঞাতভাবে, আমরা বারবার তাতে gradient পদ যোগ করে velocity গড়ে তুলি। তার মানে gradient কয়েক রাউন্ড শেখা জুড়ে (মোটামুটি) একই দিকে থাকলে আমরা ওই দিকে যথেষ্ট গতি গড়ে তুলতে পারি। ভাবো, যেমন, একটা ঢাল বরাবর সোজা নামলে কী হয়:
প্রতিটি পদক্ষেপে ঢাল বরাবর velocity বড় হয়, তাই আমরা ক্রমশ দ্রুত উপত্যকার তলায় সরি। এটা momentum কৌশলকে standard gradient descent-এর চেয়ে অনেক দ্রুত কাজ করতে সক্ষম করতে পারে। অবশ্যই একটা সমস্যা হলো একবার আমরা উপত্যকার তলায় পৌঁছালে আমরা overshoot করব। কিংবা gradient দ্রুত বদলালে আমরা ভুল দিকে সরতে দেখতে পারি। সেটাই (107)-এ hyper-parameter-এর কারণ। আমি আগে বলেছিলাম system-এ ঘর্ষণের পরিমাণ নিয়ন্ত্রণ করে; একটু বেশি সুনির্দিষ্ট হতে, তোমার -কে system-এ ঘর্ষণের পরিমাণ ভাবা উচিত। হলে, যেমন দেখেছি, কোনো ঘর্ষণ নেই, এবং velocity সম্পূর্ণভাবে gradient দ্বারা চালিত। তুলনায়, হলে প্রচুর ঘর্ষণ, velocity গড়ে উঠতে পারে না, এবং সমীকরণ (107) ও (108) gradient descent-এর চিরাচরিত সমীকরণ -এ নেমে আসে। বাস্তবে ও -এর মধ্যবর্তী একটা মান ব্যবহার করলে গতি গড়ে তোলার সুবিধার অনেকটা পাওয়া যায়, কিন্তু overshooting না ঘটিয়ে। আমরা ও নির্বাচনের অনেকটা একই উপায়ে hold-out করা validation data ব্যবহার করে -এর এমন একটা মান বেছে নিতে পারি।
আমি এতক্ষণ hyper-parameter-এর নামকরণ এড়িয়ে গেছি। কারণ -এর standard নামটা বাজেভাবে বেছে নেওয়া: একে momentum co-efficient বলা হয়। এটা সম্ভাব্যভাবে বিভ্রান্তিকর, যেহেতু পদার্থবিজ্ঞানের momentum ধারণার সাথে আদৌ একই নয়। বরং এটা ঘর্ষণের সাথে অনেক বেশি ঘনিষ্ঠভাবে সম্পর্কিত। তবে momentum co-efficient শব্দটা ব্যাপকভাবে ব্যবহৃত, তাই আমরা এটা ব্যবহার করতে থাকব।
momentum কৌশলের একটা সুন্দর দিক হলো momentum অন্তর্ভুক্ত করতে gradient descent-এর একটা implementation পরিবর্তন করতে প্রায় কোনো কাজ লাগে না। আমরা এখনও gradient হিসেব করতে backpropagation ব্যবহার করতে পারি, আগের মতোই, এবং stochastically বেছে নেওয়া mini-batch-এর মতো ধারণা ব্যবহার করতে পারি। এভাবে আমরা Hessian কৌশলের কিছু সুবিধা পেতে পারি, gradient কীভাবে বদলাচ্ছে সে সম্পর্কে তথ্য ব্যবহার করে। কিন্তু এটা করা হয় অসুবিধাগুলো ছাড়া, এবং আমাদের code-এ কেবল ছোট পরিবর্তন দিয়ে। বাস্তবে momentum কৌশল সাধারণভাবে ব্যবহৃত হয়, এবং প্রায়ই শেখা দ্রুত করে।
cost function minimize করার অন্যান্য পন্থা: cost function minimize করার আরও অনেক পন্থা গড়ে তোলা হয়েছে, এবং কোন পন্থা সেরা তা নিয়ে সর্বজনীন ঐকমত্য নেই। তুমি neural network-এ যত গভীরে যাও, অন্য কৌশলগুলো খনন করা — সেগুলো কীভাবে কাজ করে, তাদের শক্তি ও দুর্বলতা, এবং বাস্তবে কীভাবে প্রয়োগ করতে হয় তা বোঝা — সার্থক। আমি আগে উল্লেখ করা একটা paper (Efficient BackProp, Yann LeCun প্রমুখ, 1998) এই কৌশলগুলোর কয়েকটা চালু ও তুলনা করে, conjugate gradient descent ও BFGS method-সহ (ঘনিষ্ঠভাবে সম্পর্কিত limited-memory BFGS method, যা L-BFGS নামে পরিচিত, তা-ও দেখো)। সম্প্রতি আশাব্যঞ্জক ফল দেখানো আরেকটা কৌশল হলো Nesterov-এর accelerated gradient কৌশল, যা momentum কৌশলের উপর উন্নতি করে। তবে অনেক সমস্যার জন্য সাধারণ stochastic gradient descent ভালো কাজ করে, বিশেষত momentum ব্যবহার করলে, তাই বইয়ের বাকি অংশে আমরা stochastic gradient descent-এই লেগে থাকব।
Artificial neuron-এর অন্যান্য model
এতক্ষণ আমরা sigmoid neuron ব্যবহার করে আমাদের neural network গড়েছি। নীতিগতভাবে, sigmoid neuron দিয়ে গড়া একটা network যেকোনো function compute করতে পারে। তবে বাস্তবে অন্য model neuron ব্যবহার করে গড়া network কখনও কখনও sigmoid network-কে ছাড়িয়ে যায়। application-এর উপর নির্ভর করে এমন বিকল্প model-ভিত্তিক network দ্রুত শিখতে পারে, test data-তে আরও ভালো generalize করতে পারে, বা হয়তো দুটোই করতে পারে। সাধারণভাবে ব্যবহৃত কিছু রূপভেদের স্বাদ দিতে আমি কয়েকটা বিকল্প model neuron উল্লেখ করি।
সম্ভবত সরলতম রূপভেদ হলো tanh ("tanch" উচ্চারণ) neuron, যা sigmoid function-কে hyperbolic tangent function দিয়ে প্রতিস্থাপন করে। input , weight vector ও bias সহ একটা tanh neuron-এর output দেওয়া হয়:
যেখানে অবশ্যই hyperbolic tangent function। দেখা যায় এটা sigmoid neuron-এর সাথে খুব ঘনিষ্ঠভাবে সম্পর্কিত। তা দেখতে মনে করো function সংজ্ঞায়িত হয়:
সামান্য algebra দিয়ে সহজে যাচাই করা যায় যে:
অর্থাৎ কেবল sigmoid function-এর একটা পুনঃস্কেল করা সংস্করণ। আমরা graphically-ও দেখতে পারি যে function-এর আকৃতি sigmoid function-এর মতোই।
tanh neuron ও sigmoid neuron-এর মধ্যে একটা পার্থক্য হলো tanh neuron থেকে output -1 থেকে 1 পর্যন্ত বিস্তৃত, 0 থেকে 1 নয়। তার মানে তুমি tanh neuron-ভিত্তিক একটা network গড়লে তোমাকে sigmoid network-এর চেয়ে একটু ভিন্নভাবে তোমার output (এবং, application-এর বিস্তারিতের উপর নির্ভর করে, সম্ভবত তোমার input) normalize করতে হতে পারে।
sigmoid neuron-এর মতোই, tanh neuron-এর একটা network নীতিগতভাবে input-গুলোকে -1 থেকে 1 পরিসরে map করে যেকোনো function compute করতে পারে। তাছাড়া backpropagation ও stochastic gradient descent-এর মতো ধারণা tanh neuron-এর network-এ ঠিক sigmoid neuron-এর network-এর মতোই সহজে প্রয়োগ করা যায়।
তোমার network-এ কোন ধরনের neuron ব্যবহার করা উচিত, tanh নাকি sigmoid? A priori উত্তর মোটেও স্পষ্ট নয়! তবে কিছু তত্ত্বীয় যুক্তি ও কিছু অভিজ্ঞতাগত প্রমাণ আছে যা ইঙ্গিত করে tanh কখনও কখনও ভালো performance করে। tanh neuron-এর পক্ষে একটা তত্ত্বীয় যুক্তির স্বাদ সংক্ষেপে দিই। ধরো আমরা sigmoid neuron ব্যবহার করছি, তাই আমাদের network-এর সব activation ধনাত্মক। চলো -তম layer-এর -তম neuron-এ input হওয়া weight বিবেচনা করি। backpropagation-এর নিয়ম আমাদের বলে যে সংশ্লিষ্ট gradient হবে । যেহেতু activation ধনাত্মক, এই gradient-এর চিহ্ন -এর চিহ্নের সমান হবে। এর মানে হলো ধনাত্মক হলে gradient descent-এর সময় সব weight কমবে, আর ঋণাত্মক হলে gradient descent-এর সময় সব weight বাড়বে। অন্যভাবে বললে, একই neuron-এ যাওয়া সব weight হয় একসাথে বাড়তে হবে নয় একসাথে কমতে হবে। এটা একটা সমস্যা, কারণ কিছু weight বাড়ানো দরকার হতে পারে যখন অন্যগুলো কমানো দরকার। সেটা কেবল তখনই ঘটতে পারে যখন কিছু input activation-এর ভিন্ন চিহ্ন থাকে। এটা ইঙ্গিত দেয় যে sigmoid-কে এমন একটা activation function — যেমন — দিয়ে প্রতিস্থাপন করা উচিত যা ধনাত্মক ও ঋণাত্মক দুই ধরনের activation অনুমোদন করে। আসলে যেহেতু শূন্যের সাপেক্ষে প্রতিসম, , আমরা এমনকি প্রত্যাশা করতে পারি যে, মোটামুটিভাবে, hidden layer-এর activation ধনাত্মক ও ঋণাত্মকের মধ্যে সমানভাবে ভারসাম্যপূর্ণ হবে। তা নিশ্চিত করতে সাহায্য করবে যে weight update এক দিকে বা অন্য দিকে হওয়ার কোনো পদ্ধতিগত পক্ষপাত নেই।
এই যুক্তি আমাদের কতটা গুরুত্বের সাথে নেওয়া উচিত? যুক্তিটি ইঙ্গিতবাহী হলেও এটা একটা heuristic, tanh neuron যে sigmoid neuron-কে ছাড়িয়ে যায় তার কঠোর প্রমাণ নয়। হয়তো sigmoid neuron-এর এমন অন্য ধর্ম আছে যা এই সমস্যা পুষিয়ে দেয়? আসলে অনেক কাজের জন্য অভিজ্ঞতাগতভাবে দেখা যায় tanh, sigmoid neuron-এর চেয়ে কেবল সামান্য বা কোনো উন্নতি দেয় না। দুর্ভাগ্যবশত কোন neuron type কোনো নির্দিষ্ট application-এর জন্য দ্রুততম শিখবে, বা সেরা generalization performance দেবে, তা জানতে আমাদের এখনও কঠিন-ও-দ্রুত নিয়ম নেই।
sigmoid neuron-এর আরেকটা রূপভেদ হলো rectified linear neuron বা rectified linear unit। input , weight vector ও bias সহ একটা rectified linear unit-এর output দেওয়া হয়:
Graphically, rectifying function এমন দেখায়: শূন্য পর্যন্ত সমতল, তারপর -এর জন্য রৈখিকভাবে বাড়ে।
স্পষ্টতই এমন neuron sigmoid ও tanh দুই neuron থেকেই বেশ আলাদা। তবে sigmoid ও tanh neuron-এর মতোই, rectified linear unit যেকোনো function compute করতে ব্যবহার করা যায়, এবং backpropagation ও stochastic gradient descent-এর মতো ধারণা দিয়ে এগুলো train করা যায়।
কখন sigmoid বা tanh neuron-এর বদলে rectified linear unit ব্যবহার করা উচিত? image recognition-এর কিছু সাম্প্রতিক কাজে network-এর অনেকটা জুড়ে rectified linear unit ব্যবহারে যথেষ্ট সুবিধা পাওয়া গেছে। তবে tanh neuron-এর মতোই, ঠিক কখন rectified linear unit-গুলো শ্রেয়, বা কেন, সে সম্পর্কে আমাদের এখনও সত্যিকার গভীর বোঝাপড়া নেই। কিছু বিষয়ের স্বাদ দিতে মনে করো sigmoid neuron saturate হলে শেখা থামায়, অর্থাৎ যখন তাদের output বা -এর কাছাকাছি। যেমন এই অধ্যায়ে বারবার দেখেছি, সমস্যা হলো পদ gradient কমায়, এবং তা শেখা ধীর করে। tanh neuron saturate হলে একইরকম সমস্যায় ভোগে। তুলনায়, একটা rectified linear unit-এ weighted input বাড়ালে কখনোই তা saturate হবে না, তাই সংশ্লিষ্ট কোনো শেখার মন্থরতা নেই। অন্যদিকে, একটা rectified linear unit-এ weighted input ঋণাত্মক হলে gradient লোপ পায়, এবং তাই neuron পুরোপুরি শেখা থামায়। rectified linear unit কখন ও কেন sigmoid বা tanh neuron-এর চেয়ে ভালো performance করে তা বোঝা অ-তুচ্ছ করে এমন অনেক বিষয়ের এ কেবল দুটো।
আমি এখানে একটা অনিশ্চয়তার ছবি এঁকেছি, জোর দিয়েছি যে activation function কীভাবে বাছা উচিত সে সম্পর্কে আমাদের এখনও একটা শক্ত তত্ত্ব নেই। আসলে সমস্যাটা আমি যা বর্ণনা করেছি তার চেয়েও কঠিন, কারণ অসীম সংখ্যক সম্ভাব্য activation function আছে। কোনো দেওয়া সমস্যার জন্য কোনটা সেরা? কোনটা এমন একটা network-এ পরিণত হবে যা দ্রুততম শেখে? কোনটা সর্বোচ্চ test accuracy দেবে? আমি অবাক হই এই প্রশ্নগুলোর কত কম সত্যিকার গভীর ও পদ্ধতিগত অনুসন্ধান করা হয়েছে। আদর্শভাবে আমাদের এমন একটা তত্ত্ব থাকত যা আমাদের বিস্তারিতভাবে বলত কীভাবে আমাদের activation function বাছতে (এবং হয়তো চলতে-চলতে পরিবর্তন করতে) হবে। অন্যদিকে, একটা পূর্ণ তত্ত্বের অভাব আমাদের থামাতে দেওয়া উচিত নয়! আমাদের হাতে ইতিমধ্যেই শক্তিশালী হাতিয়ার আছে, এবং সেগুলো দিয়ে আমরা অনেক অগ্রগতি করতে পারি। বইয়ের বাকি অংশে আমি sigmoid neuron-কে আমাদের go-to neuron হিসেবে ব্যবহার করতে থাকব, যেহেতু সেগুলো শক্তিশালী এবং neural net সম্পর্কে মূল ধারণাগুলোর সুনির্দিষ্ট দৃষ্টান্ত দেয়। তবে মাথার পেছনে রেখো যে এই একই ধারণা অন্য ধরনের neuron-এও প্রয়োগ করা যায়, এবং তা করায় কখনও কখনও সুবিধা থাকে।
Neural network নিয়ে গল্প প্রসঙ্গে
একবার quantum mechanics-এর ভিত্তি নিয়ে একটা সম্মেলনে গিয়ে আমি একটা খুব কৌতূহলোদ্দীপক মৌখিক অভ্যাস লক্ষ করলাম: talk শেষ হলে শ্রোতাদের প্রশ্ন প্রায়ই শুরু হতো "আমি আপনার দৃষ্টিভঙ্গির প্রতি খুবই সহানুভূতিশীল, কিন্তু [...]" দিয়ে। quantum foundations আমার চিরাচরিত ক্ষেত্র ছিল না, এবং আমি এই ধরনের প্রশ্ন করার ধরন লক্ষ করেছিলাম কারণ অন্য বৈজ্ঞানিক সম্মেলনে কোনো প্রশ্নকর্তাকে বক্তার দৃষ্টিভঙ্গির প্রতি তার সহানুভূতি প্রকাশ করতে আমি কদাচিৎ বা কখনও শুনিনি। তখন আমি ভেবেছিলাম প্রশ্নটির প্রচলন ইঙ্গিত করে যে quantum foundations-এ সামান্যই প্রকৃত অগ্রগতি হচ্ছিল, এবং মানুষ কেবল চাকা ঘোরাচ্ছিল। পরে আমি বুঝলাম ওই মূল্যায়ন খুব কঠোর ছিল। বক্তারা মানুষের মন যেসব কঠিনতম সমস্যার মুখোমুখি হয়েছে তার কয়েকটার সাথে লড়ছিলেন। অবশ্যই অগ্রগতি ধীর ছিল! তবে রিপোর্ট করার মতো নিশ্চিত নতুন অগ্রগতি সবসময় না থাকলেও মানুষ কীভাবে ভাবছিল তার update শোনায় তখনও মূল্য ছিল।
তুমি হয়তো এই বইয়েও "আমি খুবই সহানুভূতিশীল [...]"-এর অনুরূপ একটা মৌখিক অভ্যাস লক্ষ করেছ। আমরা কী দেখছি তা ব্যাখ্যা করতে আমি প্রায়ই "Heuristic-ভাবে, [...]", বা "মোটামুটিভাবে, [...]" বলায় ফিরে গেছি, কোনো না কোনো ঘটনা ব্যাখ্যা করতে একটা গল্প দিয়ে অনুসরণ করেছি। এই গল্পগুলো বিশ্বাসযোগ্য, তবে আমি যে অভিজ্ঞতাগত প্রমাণ উপস্থাপন করেছি তা প্রায়ই বেশ পাতলা ছিল। গবেষণা সাহিত্যে তাকালে দেখবে একইরকম ধাঁচের গল্প neural net নিয়ে অনেক গবেষণা paper-এ দেখা যায়, প্রায়ই পাতলা সমর্থক প্রমাণ সহ। এমন গল্প নিয়ে আমাদের কী ভাবা উচিত?
বিজ্ঞানের অনেক অংশে — বিশেষত যেসব অংশ সরল ঘটনা নিয়ে কাজ করে — বেশ সাধারণ hypothesis-এর জন্য খুব শক্ত, খুব নির্ভরযোগ্য প্রমাণ পাওয়া সম্ভব। কিন্তু neural network-এ প্রচুর সংখ্যক parameter ও hyper-parameter, এবং তাদের মধ্যে অত্যন্ত জটিল মিথস্ক্রিয়া আছে। এমন অসাধারণভাবে জটিল system-এ নির্ভরযোগ্য সাধারণ বিবৃতি প্রতিষ্ঠা করা অত্যন্ত কঠিন। neural network-কে তাদের পূর্ণ সাধারণত্বে বোঝা এমন একটা সমস্যা যা, quantum foundations-এর মতোই, মানুষের মনের সীমা পরীক্ষা করে। তার বদলে আমরা প্রায়ই একটা সাধারণ বিবৃতির কয়েকটা সুনির্দিষ্ট instance-এর পক্ষে বা বিপক্ষে প্রমাণ নিয়ে সন্তুষ্ট থাকি। ফলে নতুন প্রমাণ আলোতে এলে ওই বিবৃতিগুলো কখনও কখনও পরে পরিবর্তন বা পরিত্যাগ করতে হয়।
এই পরিস্থিতি দেখার একটা উপায় হলো — neural network নিয়ে যেকোনো heuristic গল্প তার সাথে একটা অন্তর্নিহিত চ্যালেঞ্জ বহন করে। যেমন, dropout কেন কাজ করে তা ব্যাখ্যা করে আমি আগে উদ্ধৃত বিবৃতিটি বিবেচনা করো: "এই কৌশল neuron-এর জটিল co-adaptation কমায়, যেহেতু একটা neuron নির্দিষ্ট অন্য neuron-এর উপস্থিতির উপর নির্ভর করতে পারে না। তাই এটা আরও শক্তিশালী feature শিখতে বাধ্য হয় যা অন্য neuron-এর অনেক ভিন্ন random subset-এর সাথে মিলে উপকারী।" এটা একটা সমৃদ্ধ, উসকানিদায়ক বিবৃতি, এবং কেউ এই বিবৃতিটি খুলে দেখা, এতে কী সত্য, কী মিথ্যা, কী রূপভেদ ও পরিমার্জন দরকার তা বের করার চারপাশেই একটা ফলপ্রসূ গবেষণা কর্মসূচি গড়ে তুলতে পারে। আসলে এখন একদল গবেষক আছেন যাঁরা dropout (ও তার অনেক রূপভেদ) তদন্ত করছেন, এটা কীভাবে কাজ করে ও এর সীমা কী তা বোঝার চেষ্টা করছেন। আমরা আলোচনা করা অনেক heuristic-এর ক্ষেত্রেই এমনটা ঘটে। প্রতিটি heuristic কেবল একটা (সম্ভাব্য) ব্যাখ্যা নয়, এটা আরও বিস্তারিতভাবে তদন্ত ও বোঝার একটা চ্যালেঞ্জও।
অবশ্যই কোনো একক ব্যক্তির পক্ষে এই সব heuristic ব্যাখ্যা গভীরভাবে তদন্ত করার সময় নেই। neural network কীভাবে শেখে তার একটা সত্যিকার শক্তিশালী, প্রমাণ-ভিত্তিক তত্ত্ব গড়ে তুলতে neural network গবেষকদের সম্প্রদায়ের কয়েক দশক (বা তারও বেশি) লাগবে। এর মানে কি তোমার heuristic ব্যাখ্যাগুলোকে অকঠোর ও যথেষ্ট প্রমাণ-ভিত্তিক নয় বলে প্রত্যাখ্যান করা উচিত? না! আসলে আমাদের ভাবনাকে অনুপ্রাণিত ও পথ দেখাতে এমন heuristic দরকার। এটা অভিযানের মহাযুগের মতো: প্রথম দিকের অভিযাত্রীরা কখনও কখনও গুরুত্বপূর্ণ দিক থেকে ভুল বিশ্বাসের ভিত্তিতে অভিযান করতেন (ও নতুন আবিষ্কার করতেন)। পরে, ভূগোল সম্পর্কে আমাদের জ্ঞান পূরণ হওয়ার সাথে সাথে ওই ভুলগুলো সংশোধন করা হয়েছিল। তুমি যখন কোনো কিছু খারাপভাবে বোঝো — যেমন অভিযাত্রীরা ভূগোল বুঝতেন, আর যেমন আমরা আজ neural net বুঝি — তখন তোমার ভাবনার প্রতিটি ধাপে কঠোরভাবে সঠিক হওয়ার চেয়ে সাহসিকভাবে অন্বেষণ করা বেশি গুরুত্বপূর্ণ। তাই এই গল্পগুলোকে তোমার neural net সম্পর্কে কীভাবে ভাবতে হয় তার একটা উপকারী পথনির্দেশ হিসেবে দেখা উচিত, এমন গল্পের সীমাবদ্ধতা সম্পর্কে একটা সুস্থ সচেতনতা রেখে, এবং কোনো দেওয়া যুক্তিধারার পক্ষে প্রমাণ ঠিক কতটা শক্তিশালী তা সতর্কভাবে নজরে রেখে। অন্যভাবে বললে, আমাদের অনুপ্রাণিত ও উদ্বুদ্ধ করতে ভালো গল্প দরকার, এবং বিষয়টির প্রকৃত তথ্য উন্মোচন করতে কঠোর গভীর তদন্ত দরকার।