অধ্যায় ২
Backpropagation algorithm কীভাবে কাজ করে
How the backpropagation algorithm works
গত অধ্যায়ে আমরা দেখেছি কীভাবে neural network gradient descent algorithm ব্যবহার করে নিজের weight ও bias শিখে নিতে পারে। তবে আমাদের ব্যাখ্যায় একটা ফাঁক ছিল — cost function-এর gradient কীভাবে compute করতে হয় তা আলোচনা করিনি। সেটা কিন্তু বেশ বড় ফাঁক! এই অধ্যায়ে আমি এমন একটা দ্রুত algorithm ব্যাখ্যা করব যা দিয়ে এই gradient হিসাব করা যায় — এই algorithm-কে বলা হয় backpropagation।
Backpropagation algorithm প্রথম চালু হয়েছিল ১৯৭০-এর দশকে, কিন্তু এর গুরুত্ব পুরোপুরি অনুধাবিত হয়নি যতক্ষণ না David Rumelhart, Geoffrey Hinton ও Ronald Williams-এর ১৯৮৬ সালের একটি বিখ্যাত গবেষণাপত্র প্রকাশিত হয়। সেই পত্রটি এমন কয়েকটি neural network বর্ণনা করে যেখানে backpropagation শেখার আগের পদ্ধতিগুলোর তুলনায় অনেক দ্রুত কাজ করে, ফলে আগে যেসব সমস্যা অসমাধেয় ছিল সেগুলোতেও neural net ব্যবহার সম্ভব হয়। আজ backpropagation algorithm হলো neural network-এ শেখার মূল কর্মীঘোড়া (workhorse)।
এই অধ্যায়টি বইয়ের বাকি অংশের চেয়ে গাণিতিকভাবে বেশি জটিল। গণিত নিয়ে তুমি খুব উৎসাহী না হলে হয়তো অধ্যায়টা এড়িয়ে যেতে চাইবে, আর backpropagation-কে একটা black box ধরে নিয়ে তার খুঁটিনাটি উপেক্ষা করতে চাইবে। তাহলে সময় নিয়ে ওই খুঁটিনাটি পড়ার মানে কী?
কারণটা অবশ্যই — বোঝা। Backpropagation-এর কেন্দ্রে আছে cost function -এর partial derivative -এর একটা রাশি, যা network-এর যেকোনো weight (বা bias ) সাপেক্ষে নেওয়া। এই রাশি আমাদের বলে দেয় weight ও bias বদলালে cost কত দ্রুত বদলায়। রাশিটা একটু জটিল হলেও এর একটা সৌন্দর্যও আছে — এর প্রতিটি উপাদানের একটা স্বাভাবিক, স্বজ্ঞাত ব্যাখ্যা আছে। তাই backpropagation কেবল শেখার একটা দ্রুত algorithm নয়। এটি আসলে আমাদের গভীর অন্তর্দৃষ্টি দেয় — weight ও bias বদলালে network-এর সামগ্রিক আচরণ কীভাবে বদলায়। সেটা বিস্তারিত পড়ার মতো মূল্যবান বিষয়।
এসব বলার পরও, তুমি যদি অধ্যায়টা চোখ বুলিয়ে যেতে চাও, বা সোজা পরের অধ্যায়ে চলে যেতে চাও, তাতেও সমস্যা নেই। বইয়ের বাকি অংশ আমি এমনভাবে লিখেছি যাতে backpropagation-কে black box ধরে নিলেও তা বোঝা যায়। অবশ্যই, বইয়ের পরের কিছু জায়গায় আমি এই অধ্যায়ের ফলাফলগুলোর কথা উল্লেখ করব। তবে সেসব জায়গায়ও সব যুক্তি অনুসরণ না করেই মূল উপসংহারগুলো বুঝতে পারবে।
Warm up: neural network-এর output হিসাব করার একটি দ্রুত matrix-ভিত্তিক পদ্ধতি
Backpropagation নিয়ে আলোচনার আগে চলো একটা দ্রুত matrix-ভিত্তিক algorithm দিয়ে warm up করি যা neural network-এর output হিসাব করে। আসলে এই algorithm আমরা গত অধ্যায়ের শেষদিকে সংক্ষেপে দেখেছিলাম, কিন্তু খুব দ্রুত বর্ণনা করেছিলাম, তাই এটা বিস্তারিতভাবে আবার দেখা সার্থক। বিশেষত, backpropagation-এ ব্যবহৃত notation-এর সাথে একটা পরিচিত প্রসঙ্গে স্বচ্ছন্দ হওয়ার এটা একটা ভালো উপায়।
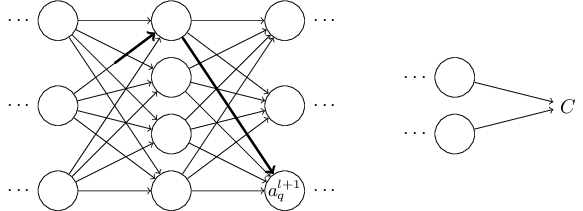
শুরু করি এমন একটা notation দিয়ে যা network-এর weight-গুলোকে দ্ব্যর্থহীনভাবে নির্দেশ করতে দেয়। আমরা ব্যবহার করব layer-এর neuron থেকে layer-এর neuron-এর connection-এর weight বোঝাতে। যেমন নিচের diagram-এ দেখানো হয়েছে একটা network-এর দ্বিতীয় layer-এর চতুর্থ neuron থেকে তৃতীয় layer-এর দ্বিতীয় neuron-এর connection-এর weight:
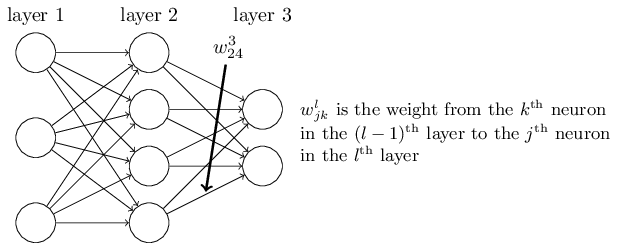
এই notation প্রথমে একটু বেমানান মনে হয়, আর আয়ত্ত করতে কিছুটা পরিশ্রমও লাগে। তবে একটু চেষ্টা করলে দেখবে notation-টা সহজ ও স্বাভাবিক হয়ে গেছে। এই notation-এর একটা খটকা হলো ও index-এর ক্রম। তুমি হয়তো ভাবছ input neuron বোঝাতে আর output neuron বোঝাতে ব্যবহার করাই বেশি যুক্তিযুক্ত হতো — কিন্তু আসলে উল্টোটা করা হয়। এই খটকার কারণ নিচে ব্যাখ্যা করব।
Network-এর bias ও activation-এর জন্যও আমরা একই রকম notation ব্যবহার করি। স্পষ্টভাবে বললে, layer-এর neuron-এর bias বোঝাতে আমরা ব্যবহার করি। আর layer-এর neuron-এর activation বোঝাতে ব্যবহার করি । নিচের diagram-এ এই notation-গুলোর ব্যবহারের উদাহরণ দেখানো হয়েছে:
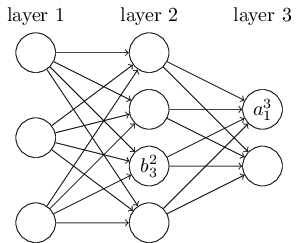
এই notation দিয়ে layer-এর neuron-এর activation এবং layer-এর activation-গুলোর সম্পর্ক নিচের equation দিয়ে প্রকাশ করা যায় (গত অধ্যায়ের Equation (4) ও তার আশপাশের আলোচনার সাথে তুলনা করো):
যেখানে যোগফলটি layer-এর সব neuron -এর উপর নেওয়া। এই রাশিটাকে matrix আকারে আবার লিখতে আমরা প্রতিটি layer -এর জন্য একটা weight matrix সংজ্ঞায়িত করি। Weight matrix -এর entry-গুলো হলো layer-এর neuron-গুলোর সাথে যুক্ত weight, অর্থাৎ সারি ও কলামের entry হলো । একইভাবে, প্রতিটি layer -এর জন্য আমরা একটা bias vector সংজ্ঞায়িত করি। এটা কীভাবে কাজ করে তুমি হয়তো অনুমান করতে পারছ — bias vector-এর component-গুলো হলো মানগুলো, layer-এর প্রতিটি neuron-এর জন্য একটি করে component। আর সবশেষে আমরা একটা activation vector সংজ্ঞায়িত করি যার component-গুলো হলো activation ।
(23)-কে matrix আকারে আবার লিখতে আমাদের শেষ যে উপাদানটা দরকার তা হলো -এর মতো একটা function-কে vectorize করার ধারণা। গত অধ্যায়ে আমরা vectorization সংক্ষেপে দেখেছিলাম, তবে সংক্ষেপে আবার বলি — ধারণাটা হলো আমরা একটা vector -এর প্রতিটি element-এ -এর মতো একটা function প্রয়োগ করতে চাই। এই ধরনের element-ভিত্তিক প্রয়োগ বোঝাতে আমরা স্পষ্ট notation ব্যবহার করি। অর্থাৎ -এর component-গুলো হলো । উদাহরণস্বরূপ, function হলে -এর vectorized রূপের প্রভাব হলো
অর্থাৎ vectorized কেবল vector-এর প্রতিটি element-কে বর্গ করে।
এসব notation মাথায় রেখে Equation (23)-কে নিচের সুন্দর ও সংক্ষিপ্ত vectorized রূপে আবার লেখা যায়
এই রাশি এক layer-এর activation কীভাবে আগের layer-এর activation-এর সাথে সম্পর্কিত তা ভাবার একটা অনেক বেশি সামগ্রিক উপায় দেয়: আমরা কেবল activation-গুলোতে weight matrix প্রয়োগ করি, তারপর bias vector যোগ করি, আর সবশেষে function প্রয়োগ করি*। এই সামগ্রিক দৃষ্টিভঙ্গি প্রায়ই এতক্ষণ নেওয়া neuron-ভিত্তিক দৃষ্টিভঙ্গির চেয়ে সহজ ও সংক্ষিপ্ত (এবং তাতে কম index লাগে!)। একে index-নরক থেকে পালানোর একটা উপায় হিসেবে ভাবতে পারো, যেখানে কী ঘটছে তা নিয়ে নিখুঁত থাকা যায়। রাশিটা বাস্তবেও কাজের, কারণ বেশিরভাগ matrix library matrix গুণ, vector যোগ ও vectorization বাস্তবায়নের দ্রুত উপায় দেয়। আসলে গত অধ্যায়ের code এই রাশিটিই অন্তর্নিহিতভাবে ব্যবহার করেছিল network-এর আচরণ হিসাব করতে।
Equation (25) দিয়ে হিসাব করার সময় আমরা পথে একটা মধ্যবর্তী রাশি হিসাব করি। এই রাশিটা যথেষ্ট কাজের, তাই একে নাম দেওয়া সার্থক: আমরা -কে layer -এর neuron-গুলোর weighted input বলি। অধ্যায়ের পরে weighted input আমরা প্রচুর ব্যবহার করব। Equation (25)-কে কখনো কখনো weighted input দিয়েও লেখা হয়, যেমন । আরও লক্ষণীয় যে -এর component হলো , অর্থাৎ হলো layer -এর neuron -এর activation function-এর weighted input।
Cost function সম্পর্কে আমাদের যে দুটি অনুমান দরকার
Backpropagation-এর লক্ষ্য হলো network-এর যেকোনো weight বা bias সাপেক্ষে cost function -এর partial derivative ও হিসাব করা। Backpropagation কাজ করার জন্য cost function-এর রূপ সম্পর্কে আমাদের দুটি মূল অনুমান করতে হয়। তবে সেই অনুমানগুলো বলার আগে মাথায় একটা উদাহরণ cost function রাখা ভালো। আমরা গত অধ্যায়ের quadratic cost function ব্যবহার করব (তুলনা করো Equation (6) )। আগের অংশের notation-এ quadratic cost-এর রূপ হলো
যেখানে: হলো training example-এর মোট সংখ্যা; যোগফলটি পৃথক পৃথক training example -এর উপর নেওয়া; হলো সংশ্লিষ্ট কাঙ্ক্ষিত output; হলো network-এর layer সংখ্যা; এবং হলো input হিসেবে দিলে network থেকে output হওয়া activation-গুলোর vector।
ঠিক আছে, তাহলে backpropagation প্রয়োগ করতে পারার জন্য আমাদের cost function সম্পর্কে কী কী অনুমান করতে হয়? প্রথম অনুমানটি হলো — cost function-কে পৃথক পৃথক training example -এর cost function -এর গড় হিসেবে লেখা যায়। Quadratic cost function-এর ক্ষেত্রে এটা সত্যি, যেখানে একটিমাত্র training example-এর cost হলো । এই অনুমানটি এই বইয়ে আমরা যত cost function দেখব তাদের সবার ক্ষেত্রেই সত্যি হবে।
এই অনুমান কেন দরকার তার কারণ — backpropagation আসলে আমাদের একটিমাত্র training example-এর জন্য partial derivative ও হিসাব করতে দেয়। তারপর training example-গুলোর উপর গড় নিয়ে আমরা ও পুনরুদ্ধার করি। আসলে এই অনুমান মাথায় রেখে আমরা ধরে নেব training example স্থির করা হয়েছে, এবং subscript বাদ দিয়ে cost -কে শুধু লিখব। শেষে আমরা ফিরিয়ে আনব, কিন্তু আপাতত এটা একটা notation-গত ঝামেলা যা অন্তর্নিহিত রাখাই ভালো।
Cost সম্পর্কে দ্বিতীয় অনুমানটি হলো — একে neural network-এর output-গুলোর একটা function হিসেবে লেখা যায়:
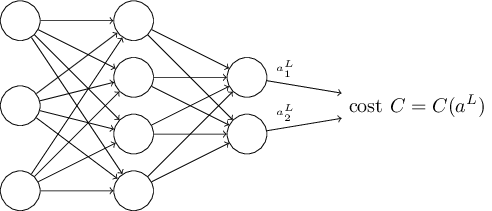
উদাহরণস্বরূপ, quadratic cost function এই শর্ত পূরণ করে, কারণ একটিমাত্র training example -এর quadratic cost-কে লেখা যায়
এবং তাই এটা output activation-গুলোর একটা function। অবশ্যই এই cost function কাঙ্ক্ষিত output -এর উপরও নির্ভর করে, আর তুমি হয়তো ভাবছ আমরা cost-কে -এরও function হিসেবে কেন ধরছি না। মনে রেখো, input training example স্থির, তাই output -ও একটা স্থির parameter। বিশেষত, এটা এমন কিছু নয় যাকে আমরা weight ও bias বদলে যেকোনোভাবে পরিবর্তন করতে পারি, অর্থাৎ এটা এমন কিছু নয় যা neural network শেখে। তাই -কে কেবল output activation -এর একটা function হিসেবে ধরা যুক্তিযুক্ত, যেখানে কেবল একটা parameter যা সেই function সংজ্ঞায়িত করতে সাহায্য করে।
Hadamard product,
Backpropagation algorithm প্রচলিত কিছু linear algebra operation-এর উপর ভিত্তি করে তৈরি — যেমন vector যোগ করা, একটা vector-কে matrix দিয়ে গুণ করা ইত্যাদি। তবে এর একটা operation একটু কম-প্রচলিত। বিশেষভাবে, ধরো ও হলো একই dimension-এর দুটি vector। তখন আমরা দিয়ে এই দুই vector-এর element-ভিত্তিক গুণফল বোঝাই। অর্থাৎ -এর component-গুলো হলো । উদাহরণস্বরূপ,
এই ধরনের element-ভিত্তিক গুণকে কখনো কখনো Hadamard product বা Schur product বলা হয়। আমরা একে Hadamard product বলব। ভালো matrix library সাধারণত Hadamard product-এর দ্রুত বাস্তবায়ন দেয়, আর backpropagation বাস্তবায়নের সময় সেটা কাজে লাগে।
Backpropagation-এর পেছনের চারটি মৌলিক equation
Backpropagation আসলে এটা বোঝা যে — network-এর weight ও bias বদলালে cost function কীভাবে বদলায়। শেষ বিচারে এর মানে partial derivative ও হিসাব করা। কিন্তু সেগুলো হিসাব করতে আমরা প্রথমে একটা মধ্যবর্তী রাশি চালু করি, যাকে আমরা layer-এর neuron-এর error বলি। Backpropagation আমাদের error হিসাব করার একটা পদ্ধতি দেবে, এবং তারপর -কে ও -এর সাথে সম্পর্কিত করবে।
Error কীভাবে সংজ্ঞায়িত হয় বুঝতে, কল্পনা করো আমাদের neural network-এ একটা দৈত্য (demon) আছে:

দৈত্যটি layer-এর neuron-এ বসে আছে। Neuron-এ input এলে দৈত্যটি neuron-এর কাজে গোলযোগ বাধায়। সে neuron-এর weighted input-এ একটা সামান্য পরিবর্তন যোগ করে, যাতে output দেওয়ার বদলে neuron-টি output দেয় । এই পরিবর্তন network-এর পরের layer-গুলোর মধ্য দিয়ে ছড়িয়ে পড়ে, শেষে সামগ্রিক cost-কে পরিমাণ বদলে দেয়।
এখন এই দৈত্যটি একটা ভালো দৈত্য, আর সে তোমাকে cost কমাতে সাহায্য করতে চাইছে, অর্থাৎ এমন একটা খুঁজছে যা cost ছোট করে। ধরো -এর মান বড় (ধনাত্মক বা ঋণাত্মক যেকোনোটা)। তখন দৈত্যটি -এর বিপরীত চিহ্নের বেছে নিয়ে cost বেশ খানিকটা কমাতে পারে। উল্টোদিকে, শূন্যের কাছাকাছি হলে দৈত্যটি weighted input বিচলিত করে cost খুব একটা উন্নত করতে পারে না। দৈত্যটি যতটা বুঝতে পারে, neuron-টি ইতিমধ্যে মোটামুটি optimal-এর কাছাকাছি*। তাই একটা heuristic অর্থে হলো neuron-টির error-এর একটা পরিমাপ।
এই গল্পে অনুপ্রাণিত হয়ে আমরা layer-এর neuron -এর error সংজ্ঞায়িত করি এভাবে
আমাদের সাধারণ প্রথা অনুযায়ী, layer-এর সাথে যুক্ত error-গুলোর vector বোঝাতে আমরা ব্যবহার করি। Backpropagation আমাদের প্রতিটি layer-এর জন্য হিসাব করার একটা উপায় দেবে, তারপর সেই error-গুলোকে আমাদের আসল আগ্রহের রাশি ও -এর সাথে সম্পর্কিত করবে।
তুমি হয়তো ভাবছ দৈত্যটি weighted input কেন বদলাচ্ছে। দৈত্যটি output activation বদলাচ্ছে ভাবা নিশ্চয়ই বেশি স্বাভাবিক হতো, ফলে error-এর পরিমাপ হিসেবে আমরা ব্যবহার করতাম। আসলে তুমি যদি তা করো তবে নিচের আলোচনার সাথে অনেকটা একই রকম ফল পাবে। কিন্তু এতে backpropagation-এর উপস্থাপনা algebraically একটু বেশি জটিল হয়ে যায়। তাই আমরা error-এর পরিমাপ হিসেবে -এই থাকব*।
আক্রমণের পরিকল্পনা: Backpropagation চারটি মৌলিক equation ঘিরে গড়ে উঠেছে। একসাথে এই equation-গুলো আমাদের error এবং cost function-এর gradient — দুটোই হিসাব করার উপায় দেয়। নিচে আমি চারটি equation দিচ্ছি। তবে সাবধান করছি: equation চারটি তাৎক্ষণিকভাবে আত্মস্থ হয়ে যাবে এমন আশা কোরো না। এমন আশা হতাশায় পরিণত হবে। আসলে backpropagation equation-গুলো এত সমৃদ্ধ যে এগুলো ভালোভাবে বুঝতে যথেষ্ট সময় ও ধৈর্য লাগে, যত তুমি ক্রমশ এগুলোর গভীরে ঢুকবে। সুখবর হলো, এই ধৈর্যের পুরস্কার বহুগুণে ফিরে আসে। তাই এই অংশের আলোচনা কেবল একটা শুরু, যা equation-গুলো পুঙ্খানুপুঙ্খভাবে বোঝার পথে তোমাকে সাহায্য করবে।
অধ্যায়ের পরে কীভাবে আমরা equation-গুলোর আরও গভীরে যাব তার একটা পূর্বাভাস: আমি equation-গুলোর একটা সংক্ষিপ্ত প্রমাণ দেব, যা ব্যাখ্যা করতে সাহায্য করবে কেন এগুলো সত্যি; আমরা equation-গুলোকে pseudocode আকারে algorithm হিসেবে আবার লিখব, এবং দেখব সেই pseudocode কীভাবে বাস্তব, চলমান Python code-এ বাস্তবায়িত হতে পারে; আর অধ্যায়ের শেষ অংশে আমরা একটা স্বজ্ঞাত ছবি গড়ে তুলব — backpropagation equation-গুলোর মানে কী, এবং কেউ কীভাবে শূন্য থেকে এগুলো আবিষ্কার করতে পারত। পথে আমরা বারবার এই চারটি মৌলিক equation-এ ফিরে আসব, আর তোমার বোঝাপড়া যত গভীর হবে, equation-গুলো তত স্বচ্ছন্দ — এমনকি হয়তো সুন্দর ও স্বাভাবিক — মনে হতে থাকবে।
Output layer-এর error -এর equation: -এর component-গুলো দেওয়া হয়
এটা খুবই স্বাভাবিক একটা রাশি। ডানদিকের প্রথম পদ কেবল মাপে output activation-এর function হিসেবে cost কত দ্রুত বদলাচ্ছে। যেমন, যদি কোনো একটা নির্দিষ্ট output neuron -এর উপর খুব একটা নির্ভর না করে, তবে ছোট হবে, যা আমরা আশাই করি। ডানদিকের দ্বিতীয় পদ মাপে activation function কত দ্রুত -তে বদলাচ্ছে।
লক্ষ করো (BP1)-এর সবকিছুই সহজে হিসাব করা যায়। বিশেষত, network-এর আচরণ হিসাব করার সময়ই আমরা হিসাব করি, আর হিসাব করতে কেবল সামান্য বাড়তি খরচ লাগে।-এর নিখুঁত রূপ অবশ্যই cost function-এর রূপের উপর নির্ভর করবে। তবে cost function জানা থাকলে হিসাব করতে খুব একটা ঝামেলা হওয়ার কথা নয়। যেমন, quadratic cost function ব্যবহার করলে , আর তাই , যা স্পষ্টতই সহজে হিসাব করা যায়।
Equation (BP1) হলো -এর একটা component-ভিত্তিক রাশি। এটা পুরোপুরি ভালো একটা রাশি, কিন্তু backpropagation-এর জন্য আমরা যে matrix-ভিত্তিক রূপ চাই তা নয়। তবে equation-টিকে matrix-ভিত্তিক রূপে আবার লেখা সহজ, যেমন
এখানে -কে এমন একটা vector হিসেবে সংজ্ঞায়িত করা হয় যার component-গুলো হলো partial derivative । -কে তুমি output activation সাপেক্ষে -এর পরিবর্তনের হার প্রকাশকারী হিসেবে ভাবতে পারো। সহজেই দেখা যায় Equation (BP1a) ও (BP1) সমতুল্য, আর সেই কারণে এখন থেকে আমরা দুটো equation-কেই বোঝাতে (BP1) পরস্পর-বিনিময়যোগ্যভাবে ব্যবহার করব। উদাহরণস্বরূপ, quadratic cost-এর ক্ষেত্রে আমরা পাই , আর তাই (BP1)-এর পুরোপুরি matrix-ভিত্তিক রূপ হয়
দেখতেই পাচ্ছ, এই রাশির সবকিছুরই একটা সুন্দর vector রূপ আছে, এবং Numpy-র মতো library দিয়ে সহজেই হিসাব করা যায়।
পরের layer-এর error -এর সাপেক্ষে error -এর equation: বিশেষভাবে
যেখানে হলো layer-এর weight matrix -এর transpose। এই equation জটিল দেখায়, কিন্তু এর প্রতিটি উপাদানের একটা সুন্দর ব্যাখ্যা আছে। ধরো আমরা layer-এর error জানি। যখন আমরা transpose weight matrix প্রয়োগ করি, তখন একে আমরা স্বজ্ঞাতভাবে network-এর মধ্য দিয়ে error-কে পেছনের দিকে সরানো হিসেবে ভাবতে পারি, যা আমাদের layer-এর output-এ error-এর একটা মাপ দেয়। তারপর আমরা Hadamard product নিই। এটা error-কে layer -এর activation function-এর মধ্য দিয়ে পেছনে সরায়, যা আমাদের layer -এর weighted input-এ error দেয়।
(BP2)-কে (BP1)-এর সাথে মিলিয়ে আমরা network-এর যেকোনো layer-এর জন্য error হিসাব করতে পারি। আমরা শুরু করি (BP1) দিয়ে হিসাব করে, তারপর Equation (BP2) প্রয়োগ করে হিসাব করি, তারপর আবার Equation (BP2) দিয়ে হিসাব করি, এভাবে network-এর পুরো পেছন পর্যন্ত যাই।
Network-এর যেকোনো bias সাপেক্ষে cost-এর পরিবর্তনের হারের equation: বিশেষভাবে:
অর্থাৎ error ঠিক পরিবর্তনের হার -এর সমান। এটা দারুণ খবর, কারণ (BP1) ও (BP2) আমাদের ইতিমধ্যেই বলে দিয়েছে কীভাবে হিসাব করতে হয়। আমরা (BP3)-কে সংক্ষেপে লিখতে পারি
যেখানে বোঝা যাচ্ছে -কে bias -এর সাথে একই neuron-এ মূল্যায়ন করা হচ্ছে।
Network-এর যেকোনো weight সাপেক্ষে cost-এর পরিবর্তনের হারের equation: বিশেষভাবে:
এটা আমাদের বলে দেয় কীভাবে partial derivative -কে আমরা ইতিমধ্যেই হিসাব করতে জানা রাশি ও -এর সাপেক্ষে হিসাব করতে হয়। Equation-টিকে কম index-ভারী notation-এ আবার লেখা যায়
যেখানে বোঝা যাচ্ছে হলো weight -এ input দেওয়া neuron-এর activation, আর হলো weight থেকে output নেওয়া neuron-এর error। কেবল weight এবং সেই weight দিয়ে যুক্ত দুটি neuron-এর দিকে নিবিড়ভাবে তাকালে আমরা একে এভাবে দেখাতে পারি:
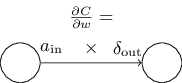
Equation (32)-এর একটা সুন্দর পরিণতি হলো — activation ছোট হলে, অর্থাৎ হলে, gradient পদ -ও ছোট হওয়ার প্রবণতা দেখায়। এই ক্ষেত্রে আমরা বলব weight-টি ধীরে শেখে, অর্থাৎ gradient descent-এর সময় এটা খুব একটা বদলায় না। অন্যভাবে বললে, (BP4)-এর একটা পরিণতি হলো low-activation neuron থেকে বেরিয়ে আসা weight-গুলো ধীরে শেখে।
(BP1)–(BP4) থেকে এই ধরনের আরও কিছু অন্তর্দৃষ্টি পাওয়া যায়। চলো output layer দিয়ে শুরু করি। (BP1)-এর পদটি বিবেচনা করো। গত অধ্যায়ের sigmoid function-এর graph থেকে মনে করো — যখন প্রায় বা তখন function খুব সমতল (flat) হয়ে যায়। এমন হলে আমরা পাই । তাই শিক্ষা হলো — শেষ layer-এর একটা weight ধীরে শিখবে যদি output neuron হয় low activation () বা high activation ()। এই ক্ষেত্রে সাধারণভাবে বলা হয় output neuron-টি saturated হয়ে গেছে, ফলে weight-টি শেখা বন্ধ করে দিয়েছে (বা ধীরে শিখছে)। Output neuron-এর bias-এর ক্ষেত্রেও একই কথা খাটে।
আগের layer-গুলোর জন্যও আমরা একই রকম অন্তর্দৃষ্টি পেতে পারি। বিশেষত, (BP2)-এর পদটি লক্ষ করো। এর মানে neuron যদি saturation-এর কাছাকাছি থাকে তবে ছোট হওয়ার সম্ভাবনা থাকে। আর এর ফলে, একটা saturated neuron-এ input দেওয়া যেকোনো weight ধীরে শিখবে*।
সব মিলিয়ে আমরা শিখলাম — একটা weight ধীরে শিখবে যদি হয় input neuron low-activation হয়, নয়তো output neuron saturated হয়, অর্থাৎ হয় high- বা low-activation হয়।
এই পর্যবেক্ষণগুলোর কোনোটাই খুব একটা অবাক করার মতো নয়। তবু এগুলো একটা neural network শেখার সময় কী ঘটছে সে সম্পর্কে আমাদের মানসিক model উন্নত করতে সাহায্য করে। আরও, এই ধরনের যুক্তি আমরা উল্টোভাবেও কাজে লাগাতে পারি। দেখা যায় এই চারটি মৌলিক equation যেকোনো activation function-এর জন্যই খাটে, কেবল standard sigmoid function নয় (কারণ, একটু পরেই দেখব, প্রমাণে -এর কোনো বিশেষ ধর্ম ব্যবহার করা হয় না)। তাই আমরা এই equation-গুলো ব্যবহার করে এমন activation function নকশা করতে পারি যাদের নির্দিষ্ট কাঙ্ক্ষিত শেখার ধর্ম আছে। ধারণা দিতে একটা উদাহরণ দিই — ধরো আমরা এমন একটা (non-sigmoid) activation function বেছে নিলাম যাতে সবসময় ধনাত্মক, আর কখনো শূন্যের কাছাকাছি যায় না। তাহলে সাধারণ sigmoid neuron saturate হলে যে শেখার ধীরগতি ঘটে তা এড়ানো যেত। বইয়ের পরে আমরা এমন উদাহরণ দেখব যেখানে activation function-এ এই ধরনের পরিবর্তন করা হয়। চারটি equation (BP1)–(BP4) মাথায় রাখলে এমন পরিবর্তন কেন চেষ্টা করা হয় এবং তার প্রভাব কী হতে পারে তা ব্যাখ্যা করতে সাহায্য হয়।

চারটি মৌলিক equation-এর প্রমাণ (ঐচ্ছিক)
এবার আমরা চারটি মৌলিক equation (BP1)–(BP4) প্রমাণ করব। চারটিই multivariable calculus-এর chain rule-এর পরিণতি। তুমি যদি chain rule-এ স্বচ্ছন্দ হও, তবে আমি জোর দিয়ে উৎসাহ দিচ্ছি — পড়ার আগে নিজেই derivation চেষ্টা করো।
শুরু করি Equation (BP1) দিয়ে, যা output error -এর একটা রাশি দেয়। এটা প্রমাণ করতে মনে করো সংজ্ঞা অনুযায়ী
Chain rule প্রয়োগ করে, উপরের partial derivative-কে আমরা output activation সাপেক্ষে partial derivative দিয়ে আবার প্রকাশ করতে পারি,
যেখানে যোগফলটি output layer-এর সব neuron -এর উপর নেওয়া। অবশ্যই, neuron-এর output activation কেবল neuron-এর weighted input -এর উপর নির্ভর করে যখন । আর তাই বিলীন হয়ে যায় যখন । ফলে আগের equation-টিকে আমরা সরল করতে পারি
মনে করে দেখো , তাই ডানদিকের দ্বিতীয় পদটিকে লেখা যায়, আর equation-টি হয়
যা component আকারে ঠিক (BP1)।
এরপর আমরা (BP2) প্রমাণ করব, যা পরের layer-এর error -এর সাপেক্ষে error -এর একটা equation দেয়। এটা করতে আমরা -কে -এর সাপেক্ষে আবার লিখতে চাই। এটা আমরা chain rule দিয়ে করতে পারি,
যেখানে শেষ লাইনে আমরা ডানদিকের দুটি পদ অদলবদল করেছি, এবং -এর সংজ্ঞা বসিয়েছি। শেষ লাইনের প্রথম পদটি মূল্যায়ন করতে লক্ষ করো যে
Differentiate করে আমরা পাই
(42)-তে আবার বসিয়ে আমরা পাই
যা component আকারে লেখা ঠিক (BP2)।
শেষ যে দুটি equation আমরা প্রমাণ করতে চাই তা হলো (BP3) ও (BP4)। এগুলোও chain rule থেকে আসে, উপরের দুটি equation-এর প্রমাণের মতোই। এগুলো আমি তোমার জন্য একটা অনুশীলনী হিসেবে রেখে দিলাম।
এতে backpropagation-এর চারটি মৌলিক equation-এর প্রমাণ সম্পূর্ণ হলো। প্রমাণটা জটিল মনে হতে পারে। কিন্তু এটা আসলে কেবল যত্ন করে chain rule প্রয়োগ করার ফল মাত্র। একটু কম সংক্ষিপ্তভাবে বললে, backpropagation-কে আমরা multivariable calculus-এর chain rule নিয়মিতভাবে প্রয়োগ করে cost function-এর gradient হিসাব করার একটা উপায় হিসেবে ভাবতে পারি। Backpropagation আসলে এটুকুই — বাকিটা খুঁটিনাটি।
Backpropagation algorithm
Backpropagation equation-গুলো আমাদের cost function-এর gradient হিসাব করার একটা উপায় দেয়। চলো এটা স্পষ্টভাবে একটা algorithm আকারে লিখে ফেলি:
- Input : input layer-এর জন্য সংশ্লিষ্ট activation সেট করো।
- Feedforward: প্রতিটি -এর জন্য এবং হিসাব করো।
- Output error : vector হিসাব করো।
- Error backpropagate করো: প্রতিটি -এর জন্য হিসাব করো।
- Output: cost function-এর gradient দেওয়া হয় ও দিয়ে।
Algorithm-টা পরীক্ষা করলে বুঝবে কেন একে backpropagation বলা হয়। আমরা error vector পেছন থেকে — শেষ layer থেকে শুরু করে — পেছনের দিকে হিসাব করি। Network-এর মধ্য দিয়ে পেছন দিকে যাওয়াটা অদ্ভুত মনে হতে পারে। কিন্তু backpropagation-এর প্রমাণের কথা ভাবলে দেখবে এই পেছনদিকে চলাটা আসলে এই সত্যেরই পরিণতি যে cost হলো network-এর output-গুলোর একটা function। আগের weight ও bias-এর সাথে cost কীভাবে বদলায় তা বুঝতে আমাদের বারবার chain rule প্রয়োগ করতে হয়, layer-গুলোর মধ্য দিয়ে পেছনে গিয়ে কাজের রাশি বের করতে হয়।
উপরে আমি যেভাবে বর্ণনা করলাম, backpropagation algorithm একটিমাত্র training example -এর জন্য cost function-এর gradient হিসাব করে। বাস্তবে, backpropagation-কে stochastic gradient descent-এর মতো একটা learning algorithm-এর সাথে মিলিয়ে ব্যবহার করাই প্রচলিত, যেখানে আমরা অনেকগুলো training example-এর জন্য gradient হিসাব করি। বিশেষভাবে, -টি training example-এর একটা mini-batch দিলে নিচের algorithm সেই mini-batch-এর ভিত্তিতে একটা gradient descent শেখার পদক্ষেপ প্রয়োগ করে:
- একগুচ্ছ training example input দাও।
- প্রতিটি training example -এর জন্য: সংশ্লিষ্ট input activation সেট করো, এবং নিচের পদক্ষেপগুলো সম্পন্ন করো:
- Feedforward: প্রতিটি -এর জন্য এবং হিসাব করো।
- Output error : vector হিসাব করো।
- Error backpropagate করো: প্রতিটি -এর জন্য হিসাব করো।
- Gradient descent: প্রতিটি -এর জন্য weight-গুলো নিয়ম অনুযায়ী, এবং bias-গুলো নিয়ম অনুযায়ী update করো।
অবশ্যই, বাস্তবে stochastic gradient descent বাস্তবায়ন করতে তোমার একটা বাইরের loop-ও লাগবে যা training example-এর mini-batch তৈরি করে, এবং আরেকটা বাইরের loop যা training-এর একাধিক epoch পেরিয়ে যায়। সরলতার জন্য আমি এগুলো বাদ দিয়েছি।
Backpropagation-এর code
বিমূর্তভাবে backpropagation বুঝে নেওয়ার পর, এবার আমরা গত অধ্যায়ে backpropagation বাস্তবায়ন করতে যে code ব্যবহার করেছিলাম তা বুঝতে পারব। সেই অধ্যায় থেকে মনে করো — code-টি ছিল Network class-এর update_mini_batch ও backprop method-এ। এই method-গুলোর code হলো উপরে বর্ণিত algorithm-এর একটা সরাসরি অনুবাদ। বিশেষভাবে, update_mini_batch method চলতি mini_batch-এর training example-গুলোর জন্য gradient হিসাব করে Network-এর weight ও bias update করে:
class Network(object):
...
def update_mini_batch(self, mini_batch, eta):
"""Update the network's weights and biases by applying
gradient descent using backpropagation to a single mini batch.
The "mini_batch" is a list of tuples "(x, y)", and "eta"
is the learning rate."""
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights]
for x, y in mini_batch:
delta_nabla_b, delta_nabla_w = self.backprop(x, y)
nabla_b = [nb+dnb for nb, dnb in zip(nabla_b, delta_nabla_b)]
nabla_w = [nw+dnw for nw, dnw in zip(nabla_w, delta_nabla_w)]
self.weights = [w-(eta/len(mini_batch))*nw
for w, nw in zip(self.weights, nabla_w)]
self.biases = [b-(eta/len(mini_batch))*nb
for b, nb in zip(self.biases, nabla_b)]বেশিরভাগ কাজ করে এই লাইনটি — delta_nabla_b, delta_nabla_w = self.backprop(x, y) — যা backprop method ব্যবহার করে partial derivative ও বের করে। backprop method আগের অংশের algorithm-কে নিবিড়ভাবে অনুসরণ করে। একটা ছোট্ট পরিবর্তন আছে — layer-গুলোকে index করতে আমরা একটু ভিন্ন পদ্ধতি ব্যবহার করি। এই পরিবর্তনটি করা হয়েছে Python-এর একটা বৈশিষ্ট্যের সুবিধা নিতে, অর্থাৎ list-এর শেষ থেকে পেছনে গোনার জন্য ঋণাত্মক list index ব্যবহার করার সুবিধা। যেমন, l[-3] হলো একটা list l-এর শেষ থেকে তৃতীয় entry। backprop-এর code নিচে দেওয়া হলো, সাথে কয়েকটা helper function, যেগুলো function, এর derivative , এবং cost function-এর derivative হিসাব করতে ব্যবহৃত হয়। এগুলো অন্তর্ভুক্ত থাকায় তুমি code-টা স্বয়ংসম্পূর্ণভাবে বুঝতে পারবে। কোথাও আটকে গেলে, code-এর মূল বর্ণনা (ও সম্পূর্ণ listing) দেখা সাহায্য করতে পারে।
class Network(object):
...
def backprop(self, x, y):
"""Return a tuple "(nabla_b, nabla_w)" representing the
gradient for the cost function C_x. "nabla_b" and
"nabla_w" are layer-by-layer lists of numpy arrays, similar
to "self.biases" and "self.weights"."""
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights]
# feedforward
activation = x
activations = [x] # list to store all the activations, layer by layer
zs = [] # list to store all the z vectors, layer by layer
for b, w in zip(self.biases, self.weights):
z = np.dot(w, activation)+b
zs.append(z)
activation = sigmoid(z)
activations.append(activation)
# backward pass
delta = self.cost_derivative(activations[-1], y) * \
sigmoid_prime(zs[-1])
nabla_b[-1] = delta
nabla_w[-1] = np.dot(delta, activations[-2].transpose())
# Note that the variable l in the loop below is used a little
# differently to the notation in Chapter 2 of the book. Here,
# l = 1 means the last layer of neurons, l = 2 is the
# second-last layer, and so on. It's a renumbering of the
# scheme in the book, used here to take advantage of the fact
# that Python can use negative indices in lists.
for l in xrange(2, self.num_layers):
z = zs[-l]
sp = sigmoid_prime(z)
delta = np.dot(self.weights[-l+1].transpose(), delta) * sp
nabla_b[-l] = delta
nabla_w[-l] = np.dot(delta, activations[-l-1].transpose())
return (nabla_b, nabla_w)
...
def cost_derivative(self, output_activations, y):
"""Return the vector of partial derivatives \partial C_x /
\partial a for the output activations."""
return (output_activations-y)
def sigmoid(z):
"""The sigmoid function."""
return 1.0/(1.0+np.exp(-z))
def sigmoid_prime(z):
"""Derivative of the sigmoid function."""
return sigmoid(z)*(1-sigmoid(z))কোন অর্থে backpropagation একটি দ্রুত algorithm?
কোন অর্থে backpropagation একটা দ্রুত algorithm? এই প্রশ্নের উত্তর দিতে চলো gradient হিসাব করার আরেকটা পদ্ধতি বিবেচনা করি। কল্পনা করো এটা neural network গবেষণার একদম গোড়ার দিন। হয়তো ১৯৫০ বা ১৯৬০-এর দশক, আর তুমিই পৃথিবীর প্রথম ব্যক্তি যে শেখার জন্য gradient descent ব্যবহারের কথা ভাবলে! কিন্তু ধারণাটা কাজে লাগাতে তোমার cost function-এর gradient হিসাব করার একটা উপায় দরকার। তুমি তোমার calculus-এর জ্ঞান মনে করে দেখো, আর ঠিক করো chain rule দিয়ে gradient হিসাব করা যায় কিনা চেষ্টা করবে। কিন্তু একটু নাড়াচাড়া করার পর algebra জটিল দেখায়, আর তুমি নিরুৎসাহিত হয়ে পড়ো। তাই তুমি আরেকটা পদ্ধতি খুঁজতে যাও। তুমি ঠিক করো cost-কে কেবল weight-গুলোর একটা function হিসেবে ধরবে (bias-এর কথায় একটু পরে আসব)। তুমি weight-গুলোকে নম্বর দাও, আর কোনো একটা নির্দিষ্ট weight -এর জন্য হিসাব করতে চাও। এটা করার একটা সুস্পষ্ট উপায় হলো নিচের approximation ব্যবহার করা
যেখানে একটা ছোট ধনাত্মক সংখ্যা, আর হলো দিকের unit vector। অন্যভাবে বললে, -এর দুটি সামান্য ভিন্ন মানের জন্য cost হিসাব করে, তারপর Equation (46) প্রয়োগ করে আমরা আন্দাজ করতে পারি। একই ধারণা আমাদের bias সাপেক্ষে partial derivative হিসাব করতেও দেবে।
এই পদ্ধতিকে খুব সম্ভাবনাময় মনে হয়। ধারণাগতভাবে এটা সরল, আর কয়েক লাইন code দিয়েই অত্যন্ত সহজে বাস্তবায়ন করা যায়। নিশ্চিতভাবেই, gradient হিসাব করতে chain rule ব্যবহারের ধারণার চেয়ে এটা অনেক বেশি সম্ভাবনাময় দেখায়!
দুর্ভাগ্যবশত, এই পদ্ধতি সম্ভাবনাময় মনে হলেও, code বাস্তবায়ন করলে দেখা যায় এটা অত্যন্ত ধীর। কেন তা বুঝতে কল্পনা করো আমাদের network-এ দশ লক্ষ weight আছে। তখন প্রতিটি আলাদা weight -এর জন্য হিসাব করতে আমাদের হিসাব করতে হবে। অর্থাৎ gradient হিসাব করতে আমাদের cost function দশ লক্ষবার হিসাব করতে হবে, যার জন্য network-এর মধ্য দিয়ে দশ লক্ষ forward pass লাগবে (প্রতিটি training example-এর জন্য)। আমাদের -ও হিসাব করতে হবে, তাই সব মিলিয়ে network-এর মধ্য দিয়ে দশ লক্ষ এক বার pass।
Backpropagation-এর চতুরতা হলো এটা আমাদের সব partial derivative একসাথে হিসাব করতে দেয় — কেবল network-এর মধ্য দিয়ে একটিমাত্র forward pass, তারপর একটিমাত্র backward pass দিয়ে। মোটামুটিভাবে, backward pass-এর computational খরচ প্রায় forward pass-এর সমান*। তাই backpropagation-এর মোট খরচ প্রায় network-এর মধ্য দিয়ে কেবল দুটি forward pass করার সমান। এর সাথে তুলনা করো (46)-এর ভিত্তিক পদ্ধতির জন্য আমাদের যে দশ লক্ষ এক বার forward pass লাগত! তাই backpropagation উপর-উপর (46)-এর ভিত্তিক পদ্ধতির চেয়ে বেশি জটিল মনে হলেও, এটা আসলে অনেক, অনেক বেশি দ্রুত।
এই গতিবৃদ্ধি প্রথম পুরোপুরি অনুধাবিত হয় ১৯৮৬ সালে, আর এটা neural network যেসব সমস্যা সমাধান করতে পারত তার পরিধি অনেক বাড়িয়ে দেয়। সেটা, ফলে, neural network ব্যবহার করার লোকের ঢল নামায়। অবশ্যই, backpropagation কোনো সর্বরোগের মহৌষধ নয়। এমনকি ১৯৮০-এর দশকের শেষ দিকেও মানুষ সীমার মুখোমুখি হয়েছিল, বিশেষ করে যখন backpropagation দিয়ে deep neural network — অর্থাৎ অনেক hidden layer সহ network — train করার চেষ্টা করা হয়েছিল। বইয়ের পরে আমরা দেখব কীভাবে আধুনিক computer এবং কিছু চতুর নতুন ধারণা এখন backpropagation দিয়ে এমন deep neural network train করা সম্ভব করেছে।
Backpropagation: বড় ছবি
আমি যেভাবে ব্যাখ্যা করেছি, সেভাবে backpropagation দুটি রহস্য তুলে ধরে। প্রথমত, algorithm-টা আসলে কী করছে? আমরা output থেকে error backpropagate হওয়ার একটা ছবি গড়ে তুলেছি। কিন্তু আমরা কি আরও গভীরে গিয়ে, এই সব matrix ও vector গুণ করার সময় কী ঘটছে সে সম্পর্কে আরও বেশি অন্তর্দৃষ্টি গড়তে পারি? দ্বিতীয় রহস্য হলো — কেউ কীভাবে প্রথমেই backpropagation আবিষ্কার করতে পারল? একটা algorithm-এর ধাপগুলো অনুসরণ করা, এমনকি algorithm-টা কাজ করে তার প্রমাণ অনুসরণ করা — এক কথা। কিন্তু এর মানে এই নয় যে তুমি সমস্যাটা এত ভালোভাবে বুঝেছ যে প্রথমেই algorithm-টা আবিষ্কার করতে পারতে। Backpropagation algorithm আবিষ্কারের দিকে নিয়ে যেতে পারে এমন কোনো যুক্তিযুক্ত চিন্তাধারা কি আছে? এই অংশে আমি এই দুটি রহস্যেরই কথা বলব।
Algorithm-টা কী করছে সে সম্পর্কে আমাদের অন্তর্দৃষ্টি উন্নত করতে, চলো কল্পনা করি আমরা network-এর কোনো একটা weight -এ একটা সামান্য পরিবর্তন করলাম:
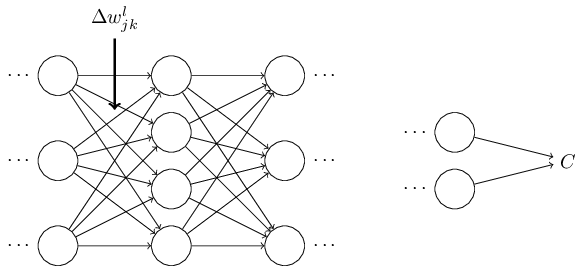
Weight-এ ওই পরিবর্তন সংশ্লিষ্ট neuron-এর output activation-এ একটা পরিবর্তন ঘটাবে:
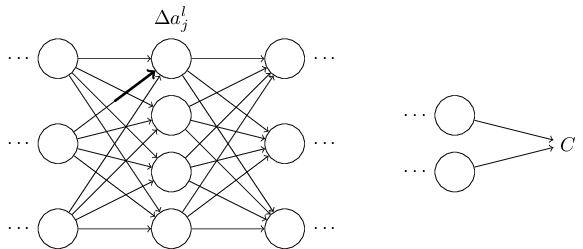
সেটা, ফলে, পরের layer-এর সব activation-এ একটা পরিবর্তন ঘটাবে:
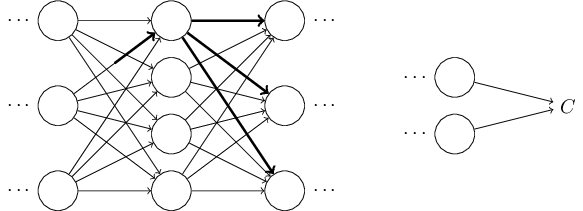
ওই পরিবর্তনগুলো ফলে পরের layer-এ পরিবর্তন ঘটাবে, তারপর তার পরের layer-এ, এভাবে শেষ পর্যন্ত final layer-এ পরিবর্তন ঘটাবে, আর তারপর cost function-এ:
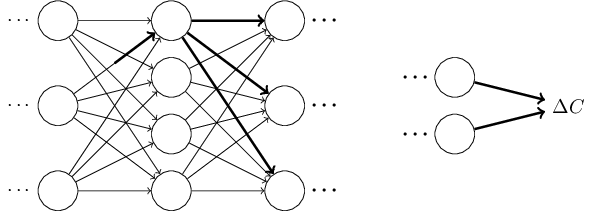
cost-এ পরিবর্তন এবং weight-এ পরিবর্তন -এর সম্পর্ক নিচের equation দিয়ে দেওয়া হয়
এটা ইঙ্গিত করে যে হিসাব করার একটা সম্ভাব্য পদ্ধতি হলো — -এ একটা সামান্য পরিবর্তন কীভাবে ছড়িয়ে পড়ে -এ একটা সামান্য পরিবর্তন ঘটায় তা যত্ন করে অনুসরণ করা। যদি আমরা তা করতে পারি, পথের সবকিছু সহজে-হিসাব-করা-যায় এমন রাশিতে প্রকাশ করতে সতর্ক থাকি, তবে আমরা হিসাব করতে পারব।
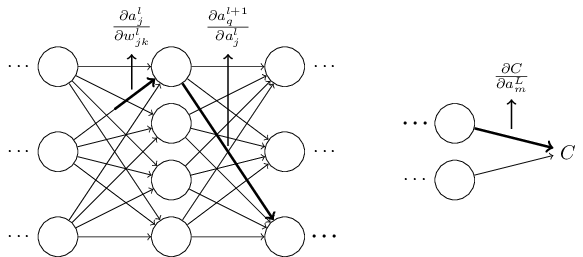
চলো এটা করার চেষ্টা করি। পরিবর্তন layer-এর neuron-এর activation-এ একটা সামান্য পরিবর্তন ঘটায়। এই পরিবর্তন দেওয়া হয়
activation-এ পরিবর্তন পরের layer, অর্থাৎ layer-এর সব activation-এ পরিবর্তন ঘটাবে। আমরা সেগুলোর কেবল একটা activation, ধরো , কীভাবে প্রভাবিত হয় তার উপর মনোযোগ দেব,
আসলে, এটা নিচের পরিবর্তন ঘটাবে:
Equation (48) থেকে রাশি বসিয়ে আমরা পাই:
অবশ্যই, পরিবর্তন , ফলে, পরের layer-এর activation-গুলোতে পরিবর্তন ঘটাবে। আসলে আমরা থেকে পর্যন্ত network জুড়ে একটা পথ কল্পনা করতে পারি, যেখানে activation-এর প্রতিটি পরিবর্তন পরের activation-এ পরিবর্তন ঘটায়, আর সবশেষে output-এ cost-এ পরিবর্তন ঘটায়। যদি পথটি activation -এর মধ্য দিয়ে যায় তবে ফলাফল-রাশি হলো
অর্থাৎ আমরা যত অতিরিক্ত neuron-এর মধ্য দিয়ে গিয়েছি প্রতিটির জন্য একটা ধরনের পদ পেয়েছি, সেইসাথে শেষে পদ। এটা network-এর এই নির্দিষ্ট পথ ধরে activation-এর পরিবর্তনের কারণে -এর পরিবর্তন প্রকাশ করে। অবশ্যই, -এ একটা পরিবর্তন ছড়িয়ে পড়ে cost-কে প্রভাবিত করতে পারে এমন অনেক পথ আছে, আর আমরা কেবল একটা পথ বিবেচনা করছিলাম। -এর মোট পরিবর্তন হিসাব করতে এটা যুক্তিযুক্ত যে weight ও final cost-এর মধ্যকার সম্ভাব্য সব পথের উপর আমাদের যোগফল নেওয়া উচিত, অর্থাৎ,
যেখানে আমরা পথ ধরে মধ্যবর্তী neuron-গুলোর সব সম্ভাব্য পছন্দের উপর যোগফল নিয়েছি। (47)-এর সাথে তুলনা করে আমরা দেখি যে
এখন, Equation (53) জটিল দেখায়। তবে এর একটা সুন্দর স্বজ্ঞাত ব্যাখ্যা আছে। আমরা network-এর একটা weight সাপেক্ষে -এর পরিবর্তনের হার হিসাব করছি। equation আমাদের বলে — network-এর দুটি neuron-এর মধ্যকার প্রতিটি edge-এর সাথে একটা rate factor যুক্ত, যা কেবল একটা neuron-এর activation-এর সাপেক্ষে আরেকটা neuron-এর activation-এর partial derivative। প্রথম weight থেকে প্রথম neuron পর্যন্ত edge-এর rate factor হলো । একটা পথের rate factor হলো সেই পথ ধরে rate factor-গুলোর গুণফল। আর মোট পরিবর্তনের হার হলো প্রাথমিক weight থেকে চূড়ান্ত cost পর্যন্ত সব পথের rate factor-গুলোর যোগফল। এই প্রক্রিয়াটি এখানে একটা একক পথের জন্য দেখানো হলো:
এতক্ষণ আমি যা দিয়েছি তা হলো একটা heuristic যুক্তি, network-এর একটা weight বিচলিত করলে কী ঘটছে তা ভাবার একটা উপায়। চলো এই যুক্তি আরও বিকশিত করতে একটা চিন্তাধারার রূপরেখা দিই। প্রথমত, তুমি Equation (53)-এর সব পৃথক partial derivative-এর জন্য সুস্পষ্ট রাশি বের করতে পারতে। একটু calculus দিয়ে সেটা সহজেই করা যায়। তা করার পর, তুমি index-এর উপর সব যোগফলকে কীভাবে matrix গুণ হিসেবে লেখা যায় তা বের করার চেষ্টা করতে পারতে। এটা ক্লান্তিকর, আর কিছুটা অধ্যবসায় দরকার, কিন্তু কোনো অসাধারণ অন্তর্দৃষ্টি লাগে না। এসব করার পর, এবং যতটা সম্ভব সরল করার পর, তুমি যা আবিষ্কার করবে তা হলো — তুমি ঠিক backpropagation algorithm-এই পৌঁছে গেছ! তাই backpropagation algorithm-কে তুমি এই সব পথের জন্য rate factor-এর যোগফল হিসাব করার একটা উপায় হিসেবে ভাবতে পারো। কিংবা, একটু অন্যভাবে বললে, backpropagation algorithm হলো weight (ও bias)-এ ছোট বিচলন network-এর মধ্য দিয়ে ছড়িয়ে পড়ে, output-এ পৌঁছে, তারপর cost-কে প্রভাবিত করার সময় সেগুলোর হিসাব রাখার একটা চতুর উপায়।
এখন, আমি এখানে এই পুরোটা বিস্তারিত করব না। এটা এলোমেলো, আর সব খুঁটিনাটি সম্পন্ন করতে যথেষ্ট যত্ন দরকার। তুমি যদি একটা চ্যালেঞ্জের জন্য তৈরি থাকো, তবে এটা চেষ্টা করতে হয়তো উপভোগ করবে। আর তা না করলেও, আশা করি এই চিন্তাধারা তোমাকে backpropagation কী সাধন করছে সে সম্পর্কে কিছু অন্তর্দৃষ্টি দেবে।
আর সেই অন্য রহস্যটা — backpropagation প্রথমে কীভাবে আবিষ্কার হতে পারত? আসলে তুমি যদি আমি যে পদ্ধতির রূপরেখা দিলাম তা অনুসরণ করো, তবে তুমি backpropagation-এর একটা প্রমাণ আবিষ্কার করবে। দুর্ভাগ্যবশত, সেই প্রমাণ এই অধ্যায়ে আগে বর্ণিত প্রমাণের চেয়ে বেশ খানিকটা দীর্ঘ ও জটিল। তাহলে ওই সংক্ষিপ্ত (কিন্তু বেশি রহস্যময়) প্রমাণটা কীভাবে আবিষ্কার হলো? দীর্ঘ প্রমাণের সব খুঁটিনাটি লিখে ফেললে তুমি যা পাবে তা হলো — পরে দেখা যায় কয়েকটা সুস্পষ্ট সরলীকরণ তোমার চোখের সামনেই দাঁড়িয়ে আছে। তুমি সেই সরলীকরণগুলো করো, একটা ছোট প্রমাণ পাও, আর সেটা লিখে ফেলো। তারপর আরও কয়েকটা সুস্পষ্ট সরলীকরণ তোমার চোখে পড়ে। তাই তুমি আবার পুনরাবৃত্তি করো। কয়েকটা পুনরাবৃত্তির পর ফল হলো সেই প্রমাণ যা আমরা আগে দেখেছি* — সংক্ষিপ্ত, কিন্তু কিছুটা দুর্বোধ্য, কারণ এর নির্মাণের সব দিকনির্দেশনা মুছে ফেলা হয়েছে! অবশ্যই আমি তোমাকে এ ব্যাপারে আমার উপর ভরসা করতে বলছি, কিন্তু আগের প্রমাণের উৎপত্তিতে সত্যিই কোনো বড় রহস্য নেই। এটা কেবল এই অংশে আমার রূপরেখা-দেওয়া প্রমাণটাকে সরল করার প্রচুর পরিশ্রম মাত্র।