অধ্যায় ৬
Deep Learning
Deep learning
গত অধ্যায়ে আমরা শিখলাম যে deep neural network-কে train করা প্রায়শই shallow neural network-এর চেয়ে অনেক কঠিন। এটা দুর্ভাগ্যজনক, কারণ আমাদের কাছে যথেষ্ট কারণ আছে বিশ্বাস করার যে deep net-কে যদি আমরা train করতে পারতাম, তবে সেগুলো shallow net-এর চেয়ে অনেক বেশি শক্তিশালী হতো। গত অধ্যায়ের খবরটা নিরুৎসাহজনক হলেও আমরা থেমে থাকব না। এই অধ্যায়ে আমরা এমন কিছু কৌশল গড়ে তুলব যা deep network train করতে কাজে লাগে, এবং সেগুলো বাস্তবে প্রয়োগ করব। আমরা একটা বড় ছবিও দেখব — image recognition, speech recognition ও অন্যান্য প্রয়োগে deep net ব্যবহারে সাম্প্রতিক অগ্রগতি সংক্ষেপে পর্যালোচনা করব। আর neural net ও artificial intelligence-এর ভবিষ্যৎ কেমন হতে পারে, তা নিয়ে একটা সংক্ষিপ্ত, অনুমানভিত্তিক দৃষ্টিও দেব।
অধ্যায়টা দীর্ঘ। পথ চলতে সুবিধা হবে বলে একটু ঘুরে দেখে নিই। অংশগুলো একে অপরের সাথে শিথিলভাবে যুক্ত, তাই neural net সম্পর্কে কিছু মৌলিক ধারণা থাকলে তুমি যেখানে সবচেয়ে আগ্রহ সেখানেই লাফিয়ে যেতে পারো।
অধ্যায়ের মূল অংশ হলো সবচেয়ে বহুল-ব্যবহৃত এক ধরনের deep network-এর পরিচয়: deep convolutional network। MNIST data set থেকে হাতে লেখা সংখ্যা classify করার সমস্যা সমাধানে convolutional net ব্যবহারের একটা বিস্তারিত উদাহরণ — code-সহ সবকিছু — আমরা ধাপে ধাপে দেখব:
Convolutional network নিয়ে আলোচনা শুরু করব সেই shallow network দিয়ে, যা দিয়ে আমরা বইয়ের আগের অংশে এই সমস্যাটায় হাত দিয়েছিলাম। অনেকগুলো ধাপে আমরা ক্রমশ আরও শক্তিশালী network গড়ে তুলব। যেতে যেতে আমরা অনেক শক্তিশালী কৌশল খতিয়ে দেখব: convolution, pooling, shallow network-এর চেয়ে অনেক বেশি training করতে GPU-র ব্যবহার, training data-র algorithmic সম্প্রসারণ (overfitting কমাতে), dropout কৌশল (overfitting কমাতে), network-এর ensemble ব্যবহার, ইত্যাদি। ফলাফল হবে এমন একটা system যা প্রায় মানুষের সমান কর্মক্ষমতা দেয়। 10,000 MNIST test ছবির মধ্যে — যে ছবিগুলো training-এর সময় দেখা হয়নি! — আমাদের system 9,967টি সঠিকভাবে classify করবে। এই 33টি ভুলভাবে classify হওয়া ছবির দিকে একবার চোখ বুলিয়ে নাও। লক্ষ করো সঠিক classification উপরের ডানদিকে; আমাদের program-এর classification নিচের ডানদিকে:

এগুলোর অনেকগুলো মানুষের পক্ষেও classify করা কঠিন। যেমন উপরের সারির তৃতীয় ছবিটা ধরো। আমার কাছে এটা "8"-এর চেয়ে বরং "9" বলেই মনে হয়, যদিও official classification "8"। আমাদের network-ও মনে করে এটা একটা "9"। এ ধরনের "ভুল" অন্তত বোধগম্য, এমনকি হয়তো প্রশংসনীয়ও। image recognition নিয়ে আলোচনা শেষ করব network (বিশেষত convolutional net) দিয়ে image recognition-এ সাম্প্রতিক চমকপ্রদ অগ্রগতির একটা সংক্ষিপ্ত জরিপ দিয়ে।
অধ্যায়ের বাকি অংশে deep learning নিয়ে আলোচনা হবে আরও বিস্তৃত ও কম বিস্তারিত দৃষ্টিকোণ থেকে। আমরা neural network-এর অন্যান্য model — যেমন recurrent neural net ও long short-term memory unit — এর একটা সংক্ষিপ্ত জরিপ করব, এবং দেখব এসব model কীভাবে speech recognition, natural language processing প্রভৃতি সমস্যায় প্রয়োগ করা যায়। আর আমরা intention-driven user interface থেকে শুরু করে artificial intelligence-এ deep learning-এর ভূমিকা পর্যন্ত — neural network ও deep learning-এর ভবিষ্যৎ নিয়ে অনুমান করব।
এই অধ্যায় বইয়ের আগের অধ্যায়গুলোর উপর ভিত্তি করে গড়ে উঠেছে, এবং backpropagation, regularization, softmax function প্রভৃতি ধারণা ব্যবহার ও সমন্বয় করে। তবে এই অধ্যায় পড়তে আগের সব অধ্যায় বিস্তারিত করে শেষ করার দরকার নেই। তবে neural network-এর মূল বিষয় নিয়ে অধ্যায় ১ পড়া থাকলে সুবিধা হবে। অধ্যায় ২ থেকে ৫-এর ধারণা ব্যবহার করার সময় আমি link দেব, যাতে দরকার হলে নিজেকে সেগুলোর সাথে পরিচিত করে নিতে পারো।
এ অধ্যায়টি কী নয়, তা-ও বলে রাখা দরকার। এটা সর্বশেষ ও সেরা neural network library-র উপর কোনো tutorial নয়। আর আমরা একেবারে অগ্রভাগের সমস্যা সমাধানে কয়েক ডজন layer-এর deep network train করতেও যাচ্ছি না। বরং মূল লক্ষ্য deep neural network-এর পেছনের কিছু core নীতি বোঝা, এবং MNIST সমস্যার সহজ, সহজবোধ্য প্রেক্ষাপটে সেগুলো প্রয়োগ করা। অন্যভাবে বললে: এই অধ্যায় তোমাকে একদম গবেষণার সীমান্তে নিয়ে যাবে না। বরং এই ও আগের অধ্যায়গুলোর উদ্দেশ্য মৌলিক বিষয়ে মনোযোগ দেওয়া, যাতে তুমি বর্তমান নানা কাজ বুঝতে প্রস্তুত হও।
Convolutional network-এর পরিচয়
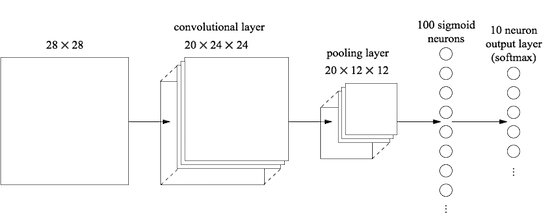
আগের অধ্যায়গুলোতে আমরা আমাদের neural network-কে হাতে লেখা সংখ্যার ছবি চেনার কাজে বেশ ভালোভাবে শিখিয়েছিলাম:
এটা আমরা করেছিলাম এমন network দিয়ে, যেখানে পাশাপাশি network layer-গুলো একে অপরের সাথে fully connected। অর্থাৎ network-এর প্রতিটি neuron পাশের layer-এর প্রতিটি neuron-এর সাথে যুক্ত:
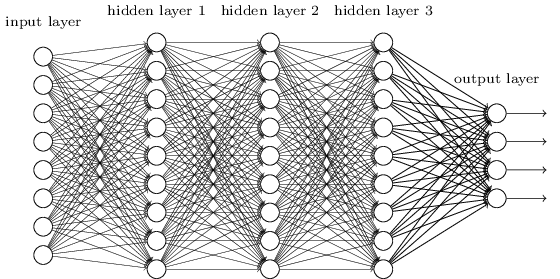
বিশেষভাবে, input ছবির প্রতিটি pixel-এর জন্য আমরা সেই pixel-এর intensity-কে input layer-এর সংশ্লিষ্ট একটা neuron-এর মান হিসেবে encode করেছিলাম। আমরা যে pixel-এর ছবি ব্যবহার করছিলাম, তার মানে আমাদের network-এর () টি input neuron। তারপর আমরা network-এর weight ও bias এমনভাবে train করেছিলাম যাতে network-এর output — আশা করি! — input ছবিটিকে সঠিকভাবে চিনে নেয়: '0', '1', '2', ..., '8' বা '9'।
আমাদের আগের network-গুলো বেশ ভালোই কাজ করে: MNIST হাতে লেখা সংখ্যার data set থেকে training ও test data ব্যবহার করে আমরা 98 শতাংশের বেশি classification accuracy পেয়েছি। কিন্তু একটু ভাবলে, ছবি classify করতে fully-connected layer-যুক্ত network ব্যবহার করাটা অদ্ভুত মনে হয়। কারণ এমন একটা network architecture ছবির spatial structure মোটেও বিবেচনায় নেয় না। যেমন এটা দূরে থাকা ও কাছাকাছি থাকা input pixel-গুলোকে একদম একই চোখে দেখে। spatial structure-এর এমন ধারণা তখন training data থেকে অনুমান করে নিতে হয়। কিন্তু একটা একদম tabula rasa (অর্থাৎ ধারণাহীন) network architecture দিয়ে শুরু করার বদলে, যদি এমন একটা architecture ব্যবহার করি যা spatial structure-এর সুবিধা নিতে চেষ্টা করে? এই অংশে আমি convolutional neural network বর্ণনা করব। এসব network এমন একটা বিশেষ architecture ব্যবহার করে, যা ছবি classify করতে বিশেষভাবে উপযুক্ত। এই architecture ব্যবহার করায় convolutional network দ্রুত train হয়। এটা আবার আমাদের deep, many-layer network train করতে সাহায্য করে, যা ছবি classify করায় খুবই ভালো। আজ image recognition-এর বেশিরভাগ neural network-এ deep convolutional network বা তার কাছাকাছি কোনো রূপ ব্যবহার করা হয়।
Convolutional neural network তিনটি মৌলিক ধারণা ব্যবহার করে: local receptive field, shared weight ও pooling। চলো একে একে এই ধারণাগুলো দেখি।
Local receptive fields: আগে দেখানো fully-connected layer-এ input-গুলোকে neuron-এর একটা উল্লম্ব রেখা হিসেবে আঁকা হয়েছিল। Convolutional net-এ input-গুলোকে বরং neuron-এর একটা বর্গ হিসেবে ভাবলে সুবিধা হবে, যাদের মান input হিসেবে ব্যবহৃত pixel intensity-র সাথে মিলে যায়:

যথারীতি আমরা input pixel-গুলোকে hidden neuron-এর একটা layer-এর সাথে যুক্ত করব। কিন্তু আমরা প্রতিটি input pixel-কে প্রতিটি hidden neuron-এর সাথে যুক্ত করব না। বরং কেবল input ছবির ছোট, স্থানীয় অঞ্চলেই সংযোগ তৈরি করব।
আরও নিখুঁতভাবে বললে, প্রথম hidden layer-এর প্রতিটি neuron input neuron-এর একটা ছোট অঞ্চলের সাথে যুক্ত থাকবে, যেমন একটা অঞ্চল, যা টি input pixel-এর সমান। তাই একটা নির্দিষ্ট hidden neuron-এর জন্য সংযোগগুলো দেখতে হতে পারে এমন:
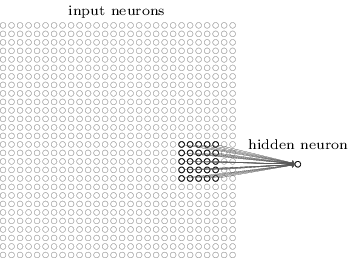
Input ছবির ওই অঞ্চলটিকে hidden neuron-টির local receptive field বলা হয়। এটা input pixel-এর উপর একটা ছোট জানালা। প্রতিটি সংযোগ একটা weight শেখে। আর hidden neuron একটা সামগ্রিক bias-ও শেখে। ওই নির্দিষ্ট hidden neuron-টিকে তুমি ভাবতে পারো নিজের নির্দিষ্ট local receptive field বিশ্লেষণ করতে শিখছে।
তারপর আমরা local receptive field-টিকে পুরো input ছবি জুড়ে slide করি। প্রতিটি local receptive field-এর জন্য প্রথম hidden layer-এ একটা আলাদা hidden neuron থাকে। এটা concrete-ভাবে বোঝাতে চলো উপরের-বাঁদিকের কোণায় একটা local receptive field দিয়ে শুরু করি:

তারপর আমরা local receptive field-টিকে এক pixel ডানদিকে slide করি (অর্থাৎ এক neuron), একটা দ্বিতীয় hidden neuron-এর সাথে যুক্ত করতে:

আর এভাবেই প্রথম hidden layer গড়ে উঠবে। লক্ষ করো, যদি আমাদের input ছবি এবং local receptive field থাকে, তবে hidden layer-এ টি neuron থাকবে। কারণ ছবির ডানপাশ (বা নিচ) ছোঁয়ার আগে আমরা local receptive field-টিকে কেবল neuron ডানদিকে (বা neuron নিচে) সরাতে পারি।
আমি local receptive field-কে একবারে এক pixel করে সরাতে দেখিয়েছি। আসলে কখনো কখনো ভিন্ন stride length ব্যবহার করা হয়। যেমন আমরা হয়তো local receptive field-কে pixel ডানে (বা নিচে) সরাতে পারি, সে ক্ষেত্রে বলব stride length ব্যবহার করা হয়েছে। এই অধ্যায়ে আমরা বেশিরভাগ ক্ষেত্রে stride length রাখব, তবে এটা জানা ভালো যে মানুষ কখনো কখনো ভিন্ন stride length নিয়ে পরীক্ষা করে। আগের অধ্যায়ের মতোই, ভিন্ন stride length চেষ্টা করতে চাইলে আমরা validation data ব্যবহার করে সবচেয়ে ভালো কর্মক্ষমতা দেয় এমন stride length বেছে নিতে পারি। একই পদ্ধতি local receptive field-এর আকার বাছাইয়েও কাজে লাগে — অবশ্যই local receptive field-এ বিশেষ কিছু নেই। সাধারণভাবে, input ছবিগুলো MNIST ছবির চেয়ে অনেক বড় হলে বড় local receptive field সহায়ক হতে থাকে।
Shared weights and biases: আমি বলেছি প্রতিটি hidden neuron-এর একটা bias এবং তার local receptive field-এর সাথে যুক্ত weight আছে। যা এখনো বলিনি তা হলো — আমরা hidden neuron-এর প্রত্যেকটির জন্য একই weight ও bias ব্যবহার করব। অন্যভাবে বললে, -তম hidden neuron-এর জন্য output হলো:
এখানে হলো neural activation function — হয়তো আগের অধ্যায়ে ব্যবহৃত sigmoid function। হলো bias-এর shared মান। হলো shared weight-এর একটা array। আর শেষে, দিয়ে আমরা অবস্থানের input activation বোঝাই।
এর মানে প্রথম hidden layer-এর সব neuron ঠিক একই feature শনাক্ত করে, কেবল input ছবির ভিন্ন ভিন্ন অবস্থানে। (আমি feature-এর ধারণা নিখুঁতভাবে সংজ্ঞায়িত করিনি। অনানুষ্ঠানিকভাবে, একটা hidden neuron যে feature শনাক্ত করে তা হলো সেই ধরনের input pattern যা neuron-টিকে activate করবে: যেমন ছবির কোনো edge, বা অন্য কোনো ধরনের আকৃতি।) কেন এটা যুক্তিযুক্ত তা বুঝতে ধরো weight ও bias এমন যে hidden neuron-টা একটা নির্দিষ্ট local receptive field-এ একটা উল্লম্ব edge শনাক্ত করতে পারে। সেই সক্ষমতা ছবির অন্য জায়গাতেও কাজে লাগার সম্ভাবনা বেশি। তাই একই feature detector-কে ছবির সর্বত্র প্রয়োগ করা উপযোগী। কিছুটা বিমূর্ত ভাষায় বললে, convolutional network ছবির translation invariance-এর সাথে ভালোভাবে খাপ খায়: একটা বিড়ালের ছবি একটু সরিয়ে দাও, তবু সেটা বিড়ালেরই ছবি থাকে।
এই কারণে input layer থেকে hidden layer-এ যাওয়ার map-কে আমরা কখনো কখনো একটা feature map বলি। Feature map সংজ্ঞায়িত করা weight-গুলোকে বলি shared weight। আর এভাবে feature map সংজ্ঞায়িত করা bias-কে বলি shared bias। Shared weight ও bias প্রায়ই বলা হয় একটা kernel বা filter সংজ্ঞায়িত করে। সাহিত্যে মানুষ এসব শব্দ কিছুটা ভিন্ন অর্থে ব্যবহার করে, তাই আমি আর নিখুঁত হতে যাচ্ছি না; বরং একটু পরেই আমরা কিছু concrete উদাহরণ দেখব।
এতক্ষণ যে network structure বর্ণনা করলাম, তা কেবল এক ধরনের স্থানীয় feature শনাক্ত করতে পারে। Image recognition করতে আমাদের একাধিক feature map লাগবে। তাই একটা সম্পূর্ণ convolutional layer-এ কয়েকটি ভিন্ন feature map থাকে:
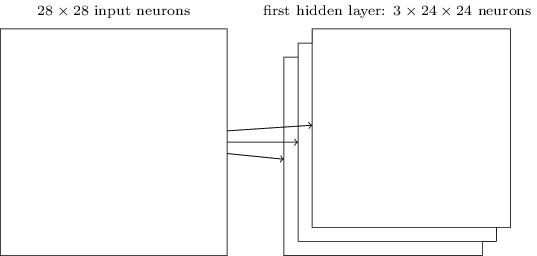
দেখানো উদাহরণে টি feature map আছে। প্রতিটি feature map সংজ্ঞায়িত হয় একটা shared weight সেট ও একটা মাত্র shared bias দিয়ে। ফলে network ধরনের ভিন্ন feature শনাক্ত করতে পারে, প্রতিটি feature পুরো ছবি জুড়ে শনাক্তযোগ্য।
উপরের diagram সরল রাখতে আমি কেবল টি feature map দেখিয়েছি। তবে বাস্তবে convolutional network আরও বেশি (হয়তো অনেক বেশি) feature map ব্যবহার করতে পারে। আদি convolutional network-গুলোর একটি, LeNet-5, MNIST সংখ্যা চিনতে টি feature map ব্যবহার করেছিল, প্রতিটি একটা local receptive field-এর সাথে যুক্ত। তাই উপরের উদাহরণটা আসলে LeNet-5-এর বেশ কাছাকাছি। অধ্যায়ের পরে যে উদাহরণগুলো গড়ব, সেগুলোতে আমরা ও feature map-এর convolutional layer ব্যবহার করব। চলো শেখা কিছু feature-এর দিকে একটু চোখ বুলিয়ে নিই:

টি ছবি টি ভিন্ন feature map-এর (বা filter, বা kernel) সাথে মিলে যায়। প্রতিটি map-কে একটা block image হিসেবে দেখানো হয়েছে, যা local receptive field-এর weight-এর সাথে মিলে। সাদা block মানে ছোট (সাধারণত আরও ঋণাত্মক) weight, তাই feature map সংশ্লিষ্ট input pixel-এ কম সাড়া দেয়। গাঢ় block মানে বড় weight, তাই feature map সংশ্লিষ্ট input pixel-এ বেশি সাড়া দেয়। মোটামুটিভাবে, উপরের ছবিগুলো দেখায় convolutional layer কোন ধরনের feature-এ সাড়া দেয়।
এই feature map থেকে আমরা কী সিদ্ধান্ত নিতে পারি? স্পষ্টতই এখানে এলোমেলো প্রত্যাশার চেয়ে বেশি spatial structure আছে: অনেক feature-এর আলো ও অন্ধকারের স্পষ্ট উপ-অঞ্চল আছে। এটা দেখায় যে আমাদের network সত্যিই spatial structure-সংক্রান্ত কিছু শিখছে। তবে এর বাইরে এই feature detector-গুলো ঠিক কী শিখছে তা বোঝা কঠিন। নিশ্চিতভাবে আমরা (যেমন) Gabor filter শিখছি না, যা image recognition-এর অনেক প্রচলিত পদ্ধতিতে ব্যবহৃত হয়েছে। আসলে এখন convolutional network যে feature শেখে তা আরও ভালোভাবে বোঝার অনেক কাজ চলছে। এই কাজ অনুসরণ করতে চাইলে আমি Matthew Zeiler ও Rob Fergus-এর (২০১৩) "Visualizing and Understanding Convolutional Networks" গবেষণাপত্র দিয়ে শুরু করার পরামর্শ দিই।
Weight ও bias share করার একটা বড় সুবিধা হলো এটা convolutional network-এর parameter-এর সংখ্যা ব্যাপকভাবে কমিয়ে দেয়। প্রতিটি feature map-এর জন্য আমাদের টি shared weight ও একটা মাত্র shared bias লাগে। তাই প্রতিটি feature map-এ টি parameter লাগে। টি feature map থাকলে মোট টি parameter convolutional layer-টি সংজ্ঞায়িত করে। তুলনায় ধরো আমাদের একটা fully connected প্রথম layer ছিল, যাতে টি input neuron ও তুলনামূলক সামান্য টি hidden neuron, যেমনটা বইয়ের আগের অনেক উদাহরণে ব্যবহার করেছি। তাহলে মোট টি weight, প্লাস বাড়তি টি bias — মোট টি parameter। অর্থাৎ fully-connected layer-এ convolutional layer-এর চেয়ে গুণেরও বেশি parameter থাকবে।
অবশ্যই parameter-সংখ্যার সরাসরি তুলনা আসলে করা যায় না, কারণ দুটো model মৌলিক দিক থেকে ভিন্ন। তবে স্বজ্ঞাতভাবে মনে হয় convolutional layer-এর translation invariance ব্যবহার fully-connected model-এর সমান কর্মক্ষমতা পেতে দরকারি parameter-সংখ্যা কমিয়ে দেবে। এটা আবার convolutional model-কে দ্রুত train করায়, এবং শেষ পর্যন্ত convolutional layer দিয়ে deep network গড়তে সাহায্য করবে।
প্রসঙ্গত, convolutional নামটা এসেছে এ থেকে যে Equation (125)-এর অপারেশনটিকে কখনো কখনো একটা convolution বলা হয়। আরও একটু নিখুঁতভাবে, মানুষ কখনো ওই সমীকরণটিকে এভাবে লেখে , যেখানে একটা feature map থেকে আসা output activation-এর সেট, input activation-এর সেট, আর -কে বলা হয় convolution operation। আমরা convolution-এর গণিত নিয়ে গভীরে যাচ্ছি না, তাই এই সংযোগ নিয়ে বেশি চিন্তার দরকার নেই। তবে নামটা কোথা থেকে এসেছে তা জানা অন্তত মন্দ নয়।
Pooling layers: এইমাত্র বর্ণিত convolutional layer ছাড়াও convolutional neural network-এ pooling layer থাকে। Pooling layer সাধারণত convolutional layer-এর ঠিক পরেই ব্যবহার করা হয়। Pooling layer যা করে তা হলো convolutional layer-এর output-এর তথ্যকে সরল করা।
বিস্তারিতভাবে, একটা pooling layer convolutional layer থেকে আসা প্রতিটি feature map নেয় এবং একটা condensed feature map প্রস্তুত করে। (এখানে পরিভাষা শিথিলভাবে ব্যবহার করছি। বিশেষত, "feature map" বলতে convolutional layer-এর হিসাব করা function নয়, বরং layer থেকে output হওয়া hidden neuron-এর activation বোঝাচ্ছি।) যেমন pooling layer-এর প্রতিটি unit আগের layer-এর (ধরো) neuron-এর একটা অঞ্চল সংক্ষেপে প্রকাশ করতে পারে। একটা concrete উদাহরণ হলো max-pooling। Max-pooling-এ একটা pooling unit কেবল input অঞ্চলের সর্বোচ্চ activation output দেয়, যেমন নিচের diagram-এ দেখানো:

লক্ষ করো, যেহেতু convolutional layer থেকে আমাদের neuron output হয়, pooling-এর পর আমাদের neuron থাকে।
উপরে বলা হয়েছে যে convolutional layer-এ সাধারণত একটার বেশি feature map থাকে। আমরা max-pooling প্রতিটি feature map-এ আলাদাভাবে প্রয়োগ করি। তাই তিনটি feature map থাকলে সম্মিলিত convolutional ও max-pooling layer দেখতে হবে এমন:
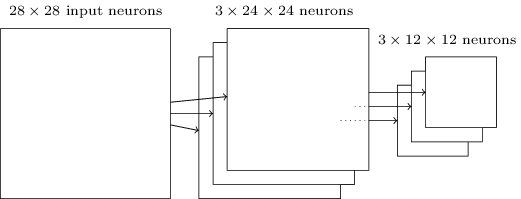
Max-pooling-কে আমরা ভাবতে পারি network-এর এই জিজ্ঞাসা হিসেবে — ছবির একটা অঞ্চলের কোথাও কি একটা নির্দিষ্ট feature পাওয়া যাচ্ছে? এরপর এটা সঠিক অবস্থানগত তথ্য ফেলে দেয়। স্বজ্ঞাটা হলো একবার একটা feature পাওয়া গেলে তার সঠিক অবস্থান অন্য feature-গুলোর তুলনায় তার মোটামুটি অবস্থানের মতো গুরুত্বপূর্ণ নয়। একটা বড় সুবিধা হলো অনেক কম pooled feature থাকে, তাই এটা পরবর্তী layer-গুলোতে দরকারি parameter-সংখ্যা কমাতে সাহায্য করে।
Pooling-এর জন্য max-pooling-ই একমাত্র কৌশল নয়। আরেকটি প্রচলিত পদ্ধতি হলো L2 pooling। এখানে neuron-এর অঞ্চলের সর্বোচ্চ activation নেওয়ার বদলে আমরা অঞ্চলের activation-গুলোর বর্গের যোগফলের বর্গমূল নিই। বিস্তারিত ভিন্ন হলেও স্বজ্ঞাটা max-pooling-এর মতোই: L2 pooling হলো convolutional layer-এর তথ্য সংক্ষিপ্ত করার একটা উপায়। বাস্তবে দুটি কৌশলই ব্যাপকভাবে ব্যবহৃত হয়েছে। কখনো কখনো মানুষ অন্য ধরনের pooling operation-ও ব্যবহার করে। সত্যিই কর্মক্ষমতা optimize করতে চাইলে তুমি validation data ব্যবহার করে কয়েকটি ভিন্ন pooling পদ্ধতি তুলনা করে সবচেয়ে ভালোটা বেছে নিতে পারো। তবে আমরা এমন বিস্তারিত optimization নিয়ে চিন্তা করছি না।
Putting it all together: এবার আমরা এই সব ধারণা একসাথে জুড়ে একটা সম্পূর্ণ convolutional neural network গড়তে পারি। এটা এইমাত্র দেখা architecture-এর মতোই, তবে এর সাথে যোগ হয়েছে টি output neuron-এর একটা layer, যা MNIST সংখ্যার টি সম্ভাব্য মানের ('0', '1', '2' ইত্যাদি) সাথে মিলে যায়:
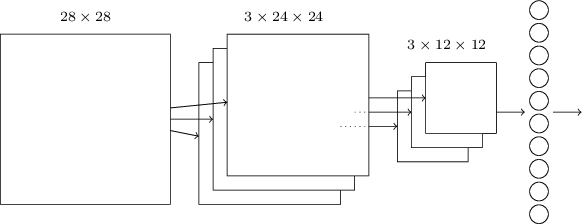
Network শুরু হয় input neuron দিয়ে, যা MNIST ছবির pixel intensity encode করতে ব্যবহৃত হয়। এর পরে একটা convolutional layer, যা একটা local receptive field ও টি feature map ব্যবহার করে। ফলাফল হলো টি hidden feature neuron-এর একটা layer। পরের ধাপ একটা max-pooling layer, যা টি feature map-এর প্রতিটিতে অঞ্চলে প্রয়োগ করা হয়। ফলাফল হলো টি hidden feature neuron-এর একটা layer।
Network-এর শেষ সংযোগ-layer একটা fully-connected layer। অর্থাৎ এই layer max-pooled layer-এর প্রতিটি neuron-কে টি output neuron-এর প্রত্যেকটির সাথে যুক্ত করে। এই fully-connected architecture আগের অধ্যায়ে ব্যবহৃতটির মতোই। তবে লক্ষ করো, উপরের diagram-এ সরলতার জন্য আমি সব সংযোগ না দেখিয়ে একটা মাত্র তীর ব্যবহার করেছি। সংযোগগুলো অবশ্যই সহজেই কল্পনা করতে পারো।
এই convolutional architecture আগের অধ্যায়ে ব্যবহৃত architecture থেকে বেশ ভিন্ন। কিন্তু সামগ্রিক ছবিটা একই রকম: অনেক সরল unit দিয়ে গড়া একটা network, যাদের আচরণ তাদের weight ও bias দ্বারা নির্ধারিত। আর সামগ্রিক লক্ষ্যও এখনো একই: training data ব্যবহার করে network-এর weight ও bias train করা, যাতে network input সংখ্যা ভালোভাবে classify করে।
বিশেষভাবে, বইয়ের আগের মতোই আমরা stochastic gradient descent ও backpropagation ব্যবহার করে network train করব। এটা বেশিরভাগটাই আগের অধ্যায়ের মতোই এগোবে। তবে backpropagation procedure-এ কয়েকটি ছোট পরিবর্তন করতে হবে। কারণ আমাদের আগের backpropagation derivation ছিল fully-connected layer-যুক্ত network-এর জন্য। সৌভাগ্যবশত convolutional ও max-pooling layer-এর জন্য সেই derivation পরিবর্তন করা সহজ। বিস্তারিত বুঝতে চাইলে আমি তোমাকে নিচের সমস্যাটা সমাধানের আমন্ত্রণ জানাই। সতর্ক করি, আগের backpropagation derivation সত্যিই ভালোভাবে আত্মস্থ না করলে এই সমস্যা সমাধানে কিছুটা সময় লাগবে (আত্মস্থ করলে অবশ্য সহজ)।
Convolutional network বাস্তবে
Convolutional neural network-এর পেছনের core ধারণাগুলো এখন আমরা দেখেছি। চলো দেখি বাস্তবে এগুলো কীভাবে কাজ করে — কয়েকটি convolutional network বাস্তবায়ন করে, এবং সেগুলোকে MNIST সংখ্যা classification সমস্যায় প্রয়োগ করে। এই কাজে আমরা যে program ব্যবহার করব তার নাম network3.py, যা আগের অধ্যায়ে তৈরি network.py ও network2.py-এর একটা উন্নত সংস্করণ। অনুসরণ করতে চাইলে code-টি GitHub-এ পাওয়া যাবে। লক্ষ করো, network3.py-এর code আমরা পরের অংশে ধাপে ধাপে দেখব। এই অংশে আমরা network3.py-কে একটা library হিসেবে ব্যবহার করে convolutional network গড়ব।
network.py ও network2.py program দুটো Python ও matrix library Numpy দিয়ে বাস্তবায়িত হয়েছিল। সেই program-গুলো first principle থেকে কাজ করত, এবং backpropagation, stochastic gradient descent প্রভৃতির খুঁটিনাটিতে নেমে যেত। কিন্তু এখন যেহেতু আমরা সেই বিস্তারিত বুঝে গেছি, network3.py-এর জন্য আমরা Theano নামে একটা machine learning library ব্যবহার করব। Theano ব্যবহার করায় convolutional neural network-এর জন্য backpropagation বাস্তবায়ন সহজ হয়ে যায়, কারণ এটা সংশ্লিষ্ট সব mapping স্বয়ংক্রিয়ভাবে হিসাব করে। Theano আমাদের আগের code-এর চেয়ে বেশ দ্রুতও (যা সহজবোধ্য করে লেখা হয়েছিল, দ্রুততার জন্য নয়), আর এটা আরও জটিল network train করা ব্যবহারিক করে তোলে। বিশেষত, Theano-র একটা দারুণ বৈশিষ্ট্য হলো এটা code চালাতে পারে হয় CPU-তে, নয়তো — থাকলে — GPU-তে। GPU-তে চালালে উল্লেখযোগ্য গতি বাড়ে এবং আরও জটিল network train করা ব্যবহারিক হয়।
অনুসরণ করতে চাইলে তোমার system-এ Theano চালু করতে হবে। Theano install করতে project-এর homepage-এর নির্দেশনা অনুসরণ করো। নিচের উদাহরণগুলো Theano 0.6 দিয়ে চালানো হয়েছিল। (এই অধ্যায় প্রকাশের সময় Theano-র সর্বশেষ সংস্করণ 0.7-এ বদলে গেছে। আমি আসলে Theano 0.7-এ উদাহরণগুলো আবার চালিয়ে text-এ লেখা ফলাফলের খুব কাছাকাছি ফল পেয়েছি।) কিছু চালানো হয়েছিল Mac OS X Yosemite-এ, GPU ছাড়া। কিছু চালানো হয়েছিল Ubuntu 14.04-এ, একটা NVIDIA GPU দিয়ে। আর কিছু পরীক্ষা দুই-ই দিয়ে চালানো হয়েছিল। network3.py চালু করতে তোমাকে network3.py source-এ GPU flag-কে True বা False (যথাযথভাবে) সেট করতে হবে। তা ছাড়া GPU-তে Theano চালু করতে গিয়ে তুমি অনলাইন নানা tutorial সহায়ক পাবে, যা Google দিয়ে সহজেই খুঁজে পাওয়া যায়। স্থানীয়ভাবে GPU না থাকলে Amazon Web Services-এর EC2 G2 spot instance দেখতে পারো। লক্ষ করো, GPU থাকলেও code চালাতে কিছুটা সময় লাগবে। অনেক পরীক্ষা মিনিট থেকে ঘণ্টা পর্যন্ত সময় নেয়। CPU-তে সবচেয়ে জটিল পরীক্ষাগুলো চালাতে কয়েক দিনও লাগতে পারে। আগের অধ্যায়ের মতোই, আমি পরামর্শ দিই code চালু করে দিয়ে পড়া চালিয়ে যেতে, মাঝে মাঝে ফিরে এসে output দেখে নিতে। CPU ব্যবহার করলে জটিল পরীক্ষাগুলোর training epoch-সংখ্যা কমিয়ে দিতে পারো, কিংবা সেগুলো পুরোপুরি বাদ দিতে পারো।
একটা baseline পেতে আমরা শুরু করব একটা shallow architecture দিয়ে, যাতে কেবল একটা hidden layer থাকবে, টি hidden neuron সহ। আমরা epoch train করব, learning rate , mini-batch size , এবং কোনো regularization ছাড়া। এই হলো:
>>> import network3
>>> from network3 import Network
>>> from network3 import ConvPoolLayer, FullyConnectedLayer, SoftmaxLayer
>>> training_data, validation_data, test_data = network3.load_data_shared()
>>> mini_batch_size = 10
>>> net = Network([
FullyConnectedLayer(n_in=784, n_out=100),
SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
>>> net.SGD(training_data, 60, mini_batch_size, 0.1,
validation_data, test_data)আমি সেরা classification accuracy পেলাম শতাংশ। এটা test_data-তে classification accuracy, যা সেই training epoch-এ মাপা হয়েছে যেখানে validation_data-তে সেরা classification accuracy পাওয়া যায়। কখন test accuracy মাপা হবে তা ঠিক করতে validation data ব্যবহার করায় test data-তে overfitting এড়াতে সাহায্য হয়। আমরা নিচে এই রীতিই অনুসরণ করব। তোমার ফল সামান্য ভিন্ন হতে পারে, কারণ network-এর weight ও bias এলোমেলোভাবে initialize হয়।
এই শতাংশ accuracy অধ্যায় ৩-এ পাওয়া শতাংশ accuracy-র কাছাকাছি, যেখানে একই রকম network architecture ও learning hyper-parameter ব্যবহার করেছিলাম। বিশেষত, দুটো উদাহরণই একটা shallow network ব্যবহার করেছে, একটা মাত্র hidden layer সহ যাতে টি hidden neuron। দুটোই epoch train করেছে, mini-batch size ও learning rate ব্যবহার করেছে।
তবে আগের network-এ দুটি পার্থক্য ছিল। প্রথমত, আমরা আগের network-কে regularize করেছিলাম, overfitting-এর প্রভাব কমাতে। বর্তমান network-কে regularize করলে accuracy উন্নত হয় বটে, কিন্তু লাভ সামান্য, তাই আমরা regularization নিয়ে আপাতত মাথা ঘামাব না, পরে দেখব। দ্বিতীয়ত, আগের network-এর শেষ layer sigmoid activation ও cross-entropy cost function ব্যবহার করেছিল, কিন্তু বর্তমান network একটা softmax শেষ layer ও log-likelihood cost function ব্যবহার করে। অধ্যায় ৩-এ ব্যাখ্যা করা হয়েছে, এটা বড় কোনো পরিবর্তন নয়। কোনো বিশেষ গভীর কারণে আমি এই পরিবর্তন করিনি — মূলত করেছি কারণ আধুনিক image classification network-এ softmax প্লাস log-likelihood cost বেশি প্রচলিত।
একটা গভীরতর network architecture দিয়ে কি আমরা এই ফলের চেয়ে ভালো করতে পারি?
চলো network-এর একদম শুরুতেই একটা convolutional layer ঢুকিয়ে শুরু করি। আমরা বাই local receptive field, stride length ও টি feature map ব্যবহার করব। সাথে একটা max-pooling layer-ও ঢোকাব, যা বাই pooling window ব্যবহার করে feature-গুলোকে একত্র করে। তাই সামগ্রিক network architecture দেখতে অনেকটা গত অংশে আলোচিত architecture-এর মতো, তবে একটা বাড়তি fully-connected layer সহ:
এই architecture-এ convolutional ও pooling layer-কে আমরা ভাবতে পারি input training ছবির স্থানীয় spatial structure শিখছে, আর পরের fully-connected layer আরও বিমূর্ত স্তরে শিখছে, পুরো ছবি জুড়ে বৈশ্বিক তথ্য একত্র করছে। এটা convolutional neural network-এ একটা প্রচলিত pattern।
চলো এমন একটা network train করি, এবং দেখি এটা কেমন করে:
>>> net = Network([
ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28),
filter_shape=(20, 1, 5, 5),
poolsize=(2, 2)),
FullyConnectedLayer(n_in=20*12*12, n_out=100),
SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
>>> net.SGD(training_data, 60, mini_batch_size, 0.1,
validation_data, test_data)এটা আমাদের শতাংশ accuracy-তে নিয়ে যায়, যা আমাদের আগের যেকোনো ফলের চেয়ে উল্লেখযোগ্য উন্নতি। আসলে আমরা error rate এক-তৃতীয়াংশের বেশি কমিয়ে ফেলেছি, যা দারুণ উন্নতি।
Network structure নির্দিষ্ট করার সময় আমি convolutional ও pooling layer-কে একটা single layer হিসেবে ধরেছি। এদের আলাদা layer নাকি একটা single layer হিসেবে গণ্য করা হবে তা কিছুটা রুচির ব্যাপার। network3.py এদের একটা single layer হিসেবে ধরে কারণ এতে code একটু compact হয়। তবে চাইলে network3.py সহজেই পরিবর্তন করে layer-গুলো আলাদাভাবে নির্দিষ্ট করা যায়।
আমরা কি শতাংশ classification accuracy-র উপর উন্নতি করতে পারি?
চলো একটা দ্বিতীয় convolutional-pooling layer ঢোকানোর চেষ্টা করি। আমরা বিদ্যমান convolutional-pooling layer ও fully-connected hidden layer-এর মাঝখানে এটা ঢোকাব। আবার আমরা একটা local receptive field ব্যবহার করব, এবং অঞ্চলে pool করব। আগের মতোই hyper-parameter ব্যবহার করে train করলে কী হয় দেখি:
>>> net = Network([
ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28),
filter_shape=(20, 1, 5, 5),
poolsize=(2, 2)),
ConvPoolLayer(image_shape=(mini_batch_size, 20, 12, 12),
filter_shape=(40, 20, 5, 5),
poolsize=(2, 2)),
FullyConnectedLayer(n_in=40*4*4, n_out=100),
SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
>>> net.SGD(training_data, 60, mini_batch_size, 0.1,
validation_data, test_data)আবারও আমরা একটা উন্নতি পেলাম: এখন আমরা শতাংশ classification accuracy-তে!
এই মুহূর্তে দুটো স্বাভাবিক প্রশ্ন ওঠে। প্রথম প্রশ্ন: একটা দ্বিতীয় convolutional-pooling layer প্রয়োগ করার মানে আসলে কী? আসলে দ্বিতীয় convolutional-pooling layer-টিকে তুমি ভাবতে পারো "ছবি"-র input হিসেবে, যাদের "pixel"-গুলো মূল input ছবিতে নির্দিষ্ট স্থানীয় feature-এর উপস্থিতি (বা অনুপস্থিতি) প্রকাশ করে। তাই এই layer-টিকে তুমি ভাবতে পারো মূল input ছবির একটা সংস্করণকে input হিসেবে নিচ্ছে। সেই সংস্করণ বিমূর্ত ও সংক্ষিপ্ত, কিন্তু এখনও অনেক spatial structure আছে, তাই একটা দ্বিতীয় convolutional-pooling layer ব্যবহার করা যুক্তিযুক্ত।
এটা একটা সন্তোষজনক দৃষ্টিভঙ্গি, কিন্তু একটা দ্বিতীয় প্রশ্নের জন্ম দেয়। আগের layer-এর output-এ টি আলাদা feature map জড়িত, তাই দ্বিতীয় convolutional-pooling layer-এ টি input থাকে। মনে হয় যেন আমরা টি আলাদা ছবি input দিচ্ছি, একটা single ছবি নয়, যেমনটা প্রথম convolutional-pooling layer-এর ক্ষেত্রে ছিল। দ্বিতীয় convolutional-pooling layer-এর neuron-গুলো এই একাধিক input ছবিতে কীভাবে সাড়া দেবে? আসলে আমরা এই layer-এর প্রতিটি neuron-কে তার local receptive field-এর সব input neuron থেকে শিখতে দেব। আরও অনানুষ্ঠানিকভাবে: দ্বিতীয় convolutional-pooling layer-এর feature detector-গুলো আগের layer-এর সব feature-এ access পায়, কিন্তু কেবল তাদের নির্দিষ্ট local receptive field-এর মধ্যে।
Rectified linear unit ব্যবহার: এই মুহূর্তে আমরা যে network গড়েছি তা আসলে MNIST সমস্যা পরিচয় করানো যুগান্তকারী ১৯৯৮ গবেষণাপত্রে ব্যবহৃত একটা network-এর রূপভেদ — যাকে LeNet-5 বলা হয়। এটা আরও পরীক্ষা-নিরীক্ষা এবং বোঝাপড়া ও স্বজ্ঞা গড়ার ভালো ভিত্তি। বিশেষত, ফল উন্নত করার চেষ্টায় network-কে আমরা নানাভাবে পরিবর্তন করতে পারি।
শুরুতে চলো আমাদের neuron-গুলো বদলাই যাতে sigmoid activation function-এর বদলে আমরা rectified linear unit ব্যবহার করি। অর্থাৎ আমরা activation function ব্যবহার করব। আমরা epoch train করব, learning rate । আমি আরও দেখলাম কিছুটা l2 regularization ব্যবহার করলে সামান্য সাহায্য হয়, regularization parameter দিয়ে:
>>> from network3 import ReLU
>>> net = Network([
ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28),
filter_shape=(20, 1, 5, 5),
poolsize=(2, 2),
activation_fn=ReLU),
ConvPoolLayer(image_shape=(mini_batch_size, 20, 12, 12),
filter_shape=(40, 20, 5, 5),
poolsize=(2, 2),
activation_fn=ReLU),
FullyConnectedLayer(n_in=40*4*4, n_out=100, activation_fn=ReLU),
SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
>>> net.SGD(training_data, 60, mini_batch_size, 0.03,
validation_data, test_data, lmbda=0.1)আমি শতাংশ classification accuracy পেলাম। এটা sigmoid ফলের () উপর সামান্য উন্নতি। তবে আমার সব পরীক্ষায় আমি দেখলাম rectified linear unit-ভিত্তিক network ধারাবাহিকভাবে sigmoid activation function-ভিত্তিক network-এর চেয়ে ভালো করে। এই সমস্যায় rectified linear unit-এ যাওয়ায় সত্যিকারের লাভ আছে বলে মনে হয়।
Rectified linear activation function কেন sigmoid বা tanh function-এর চেয়ে ভালো? এই মুহূর্তে এই প্রশ্নের উত্তর আমরা ভালোভাবে বুঝি না। আসলে rectified linear unit গত কয়েক বছরেই কেবল ব্যাপকভাবে ব্যবহৃত হতে শুরু করেছে। সাম্প্রতিক গ্রহণের কারণ অভিজ্ঞতাভিত্তিক: কিছু মানুষ rectified linear unit চেষ্টা করেন, প্রায়ই অনুমান বা heuristic যুক্তির ভিত্তিতে। (একটা প্রচলিত যুক্তি হলো বড় -এর সীমায় saturate হয় না, sigmoid neuron-এর মতো নয়, এবং এটা rectified linear unit-কে শেখা চালিয়ে যেতে সাহায্য করে। যুক্তিটা যতদূর যায় ঠিক আছে, কিন্তু এটা খুব বিস্তারিত ন্যায্যতা নয়, বরং একটা just-so গল্প।) তাঁরা benchmark data set-এ ভালো ফল পান, এবং চর্চা ছড়িয়ে পড়ে। একটা আদর্শ জগতে আমাদের কাছে একটা তত্ত্ব থাকত যা বলে দিত কোন প্রয়োগে কোন activation function বাছতে হবে। কিন্তু এখন আমরা এমন জগৎ থেকে অনেক দূরে। আরও ভালো activation function বাছাইয়ের মাধ্যমে আরও বড় উন্নতি পাওয়া গেলে আমি একদমই অবাক হব না। আর আমি এ-ও আশা করি আগামী দশকগুলোতে activation function-এর একটা শক্তিশালী তত্ত্ব গড়ে উঠবে। আজ আমরা এখনো অল্প-বোঝা rule of thumb ও অভিজ্ঞতার উপর নির্ভর করি।
Training data সম্প্রসারণ: ফল উন্নত করার আরেকটা উপায় হলো algorithmic-ভাবে training data সম্প্রসারণ করা। Training data সম্প্রসারণের একটা সহজ উপায় হলো প্রতিটি training ছবিকে এক pixel সরিয়ে দেওয়া — হয় এক pixel উপরে, এক pixel নিচে, এক pixel বাঁয়ে, বা এক pixel ডানে। আমরা shell prompt থেকে expand_mnist.py program চালিয়ে এটা করতে পারি:
$ python expand_mnist.pyএই program MNIST training ছবি নেয়, এবং একটা সম্প্রসারিত training set প্রস্তুত করে, training ছবি সহ। তারপর আমরা সেই training ছবি ব্যবহার করে network train করতে পারি। আমরা উপরের মতোই network ব্যবহার করব, rectified linear unit সহ। প্রাথমিক পরীক্ষায় আমি training epoch-সংখ্যা কমিয়েছিলাম — এটা যুক্তিযুক্ত ছিল, কারণ আমরা গুণ বেশি data দিয়ে train করছি। কিন্তু আসলে data সম্প্রসারণ overfitting-এর প্রভাব অনেকটাই কমিয়ে দিল। তাই কিছু পরীক্ষার পর আমি শেষমেশ আবার epoch train করায় ফিরে গেলাম। যা-ই হোক, চলো train করি:
>>> expanded_training_data, _, _ = network3.load_data_shared(
"../data/mnist_expanded.pkl.gz")
>>> net = Network([
ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28),
filter_shape=(20, 1, 5, 5),
poolsize=(2, 2),
activation_fn=ReLU),
ConvPoolLayer(image_shape=(mini_batch_size, 20, 12, 12),
filter_shape=(40, 20, 5, 5),
poolsize=(2, 2),
activation_fn=ReLU),
FullyConnectedLayer(n_in=40*4*4, n_out=100, activation_fn=ReLU),
SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
>>> net.SGD(expanded_training_data, 60, mini_batch_size, 0.03,
validation_data, test_data, lmbda=0.1)সম্প্রসারিত training data ব্যবহার করে আমি শতাংশ accuracy পেলাম। তাই এই প্রায়-তুচ্ছ পরিবর্তন classification accuracy-তে উল্লেখযোগ্য উন্নতি দেয়। আসলে, আগে আলোচনা করেছি যে algorithmic-ভাবে data সম্প্রসারণের এই ধারণা আরও দূর নেওয়া যায়। সেই আগের আলোচনার কিছু ফলের স্বাদ মনে করিয়ে দিই: ২০০৩ সালে Simard, Steinkraus ও Platt তাঁদের MNIST কর্মক্ষমতা শতাংশে উন্নীত করেন, আমাদেরই মতো একটা neural network ব্যবহার করে, দুটো convolutional-pooling layer ও তারপর neuron-এর একটা fully-connected hidden layer সহ। তাঁদের architecture-এ কিছু বিস্তারিত পার্থক্য ছিল — যেমন তাঁদের কাছে rectified linear unit-এর সুবিধা ছিল না — কিন্তু তাঁদের উন্নত কর্মক্ষমতার মূল চাবিকাঠি ছিল training data সম্প্রসারণ। তাঁরা MNIST training ছবি ঘুরিয়ে, সরিয়ে ও বাঁকিয়ে এটা করেছিলেন। তাঁরা "elastic distortion"-এরও একটা প্রক্রিয়া গড়েছিলেন, যা মানুষ লেখার সময় হাতের পেশির এলোমেলো কম্পন অনুকরণ করার একটা উপায়। এসব প্রক্রিয়া মিলিয়ে তাঁরা তাঁদের training data-র কার্যকর আকার ব্যাপকভাবে বাড়িয়েছিলেন, এভাবেই তাঁরা শতাংশ accuracy অর্জন করেন।
একটি বাড়তি fully-connected layer ঢোকানো: আমরা কি আরও ভালো করতে পারি? একটা সম্ভাবনা হলো ঠিক উপরের পদ্ধতি ব্যবহার করা, তবে fully-connected layer-এর আকার বড় করা। আমি ও neuron দিয়ে চেষ্টা করে যথাক্রমে ও শতাংশ ফল পেলাম। এটা কৌতূহলোদ্দীপক, কিন্তু আগের ফলের ( শতাংশ) উপর সত্যিই দৃঢ় জয় নয়।
একটা বাড়তি fully-connected layer যোগ করলে কেমন হয়? চলো একটা বাড়তি fully-connected layer ঢোকানোর চেষ্টা করি, যাতে আমাদের দুটো -hidden neuron fully-connected layer থাকে:
>>> net = Network([
ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28),
filter_shape=(20, 1, 5, 5),
poolsize=(2, 2),
activation_fn=ReLU),
ConvPoolLayer(image_shape=(mini_batch_size, 20, 12, 12),
filter_shape=(40, 20, 5, 5),
poolsize=(2, 2),
activation_fn=ReLU),
FullyConnectedLayer(n_in=40*4*4, n_out=100, activation_fn=ReLU),
FullyConnectedLayer(n_in=100, n_out=100, activation_fn=ReLU),
SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
>>> net.SGD(expanded_training_data, 60, mini_batch_size, 0.03,
validation_data, test_data, lmbda=0.1)এটা করে আমি শতাংশ test accuracy পেলাম। আবারও, সম্প্রসারিত net তেমন সাহায্য করছে না। ও neuron-এর fully-connected layer দিয়ে একই রকম পরীক্ষা চালিয়ে ও শতাংশ ফল পাওয়া যায়। এটা উৎসাহজনক, কিন্তু এখনো সত্যিই নিষ্পত্তিমূলক জয় থেকে দূরে।
এখানে কী ঘটছে? সম্প্রসারিত বা বাড়তি fully-connected layer কি সত্যিই MNIST-এ সাহায্য করে না? নাকি আমাদের network-এর আরও ভালো করার সক্ষমতা আছে, কিন্তু আমরা ভুল উপায়ে শিখছি? যেমন হয়তো আমরা overfit করার প্রবণতা কমাতে আরও শক্তিশালী regularization কৌশল ব্যবহার করতে পারি। একটা সম্ভাবনা হলো অধ্যায় ৩-এ পরিচয় করানো dropout কৌশল। মনে করো dropout-এর মূল ধারণা হলো network train করার সময় এলোমেলোভাবে আলাদা আলাদা activation সরিয়ে দেওয়া। এটা model-কে আলাদা প্রমাণখণ্ডের ক্ষতির প্রতি আরও সহনশীল করে তোলে, ফলে training data-র বিশেষ idiosyncrasy-র উপর নির্ভর করার সম্ভাবনা কমায়। চলো শেষ fully-connected layer-গুলোতে dropout প্রয়োগ করার চেষ্টা করি:
>>> net = Network([
ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28),
filter_shape=(20, 1, 5, 5),
poolsize=(2, 2),
activation_fn=ReLU),
ConvPoolLayer(image_shape=(mini_batch_size, 20, 12, 12),
filter_shape=(40, 20, 5, 5),
poolsize=(2, 2),
activation_fn=ReLU),
FullyConnectedLayer(
n_in=40*4*4, n_out=1000, activation_fn=ReLU, p_dropout=0.5),
FullyConnectedLayer(
n_in=1000, n_out=1000, activation_fn=ReLU, p_dropout=0.5),
SoftmaxLayer(n_in=1000, n_out=10, p_dropout=0.5)],
mini_batch_size)
>>> net.SGD(expanded_training_data, 40, mini_batch_size, 0.03,
validation_data, test_data)এটা ব্যবহার করে আমরা শতাংশ accuracy পাই, যা আমাদের আগের ফলের উপর উল্লেখযোগ্য উন্নতি, বিশেষত আমাদের প্রধান benchmark — hidden neuron-এর network, যেখানে আমরা শতাংশ অর্জন করেছিলাম।
দুটো পরিবর্তন উল্লেখ করার মতো।
প্রথমত, আমি training epoch-সংখ্যা -এ কমিয়েছি: dropout overfitting কমিয়েছিল, তাই আমরা দ্রুত শিখলাম।
দ্বিতীয়ত, fully-connected hidden layer-গুলোতে neuron, আগে ব্যবহৃত নয়। অবশ্যই, dropout train করার সময় কার্যত অনেক neuron বাদ দেয়, তাই কিছুটা সম্প্রসারণ প্রত্যাশিত। আসলে আমি ও hidden neuron দুটো দিয়েই পরীক্ষা করেছি, এবং hidden neuron দিয়ে (খুব সামান্য) ভালো validation কর্মক্ষমতা পেয়েছি।
Network-এর ensemble ব্যবহার: কর্মক্ষমতা আরও উন্নত করার একটা সহজ উপায় হলো কয়েকটি neural network তৈরি করা, এবং তারপর সেগুলোকে ভোট দিতে দেওয়া যাতে সেরা classification নির্ধারিত হয়। ধরো, যেমন, আমরা উপরের নিয়ম ব্যবহার করে টি ভিন্ন neural network train করলাম, প্রতিটি শতাংশের কাছাকাছি accuracy পাচ্ছে। network-গুলোর accuracy কাছাকাছি হলেও তারা ভিন্ন ভুল করতে পারে, ভিন্ন random initialization-এর কারণে। যুক্তিসঙ্গত যে আমাদের network-এর মধ্যে ভোট নিলে যেকোনো একক network-এর চেয়ে ভালো classification পাওয়া যেতে পারে।
এটা সত্যি হওয়ার পক্ষে বড় বেশি ভালো শোনায়, কিন্তু এই ধরনের ensembling neural network ও অন্যান্য machine learning কৌশল — উভয়েরই একটা প্রচলিত কৌশল। আর এটা সত্যিই আরও উন্নতি দেয়: আমরা শেষ পর্যন্ত শতাংশ accuracy পাই। অন্যভাবে বললে, আমাদের network-এর ensemble test ছবির টি বাদে সব সঠিকভাবে classify করে।
Test set-এ অবশিষ্ট ভুলগুলো নিচে দেখানো হলো। উপরের ডানদিকের label MNIST data অনুযায়ী সঠিক classification, আর নিচের ডানদিকেরটা আমাদের net-এর ensemble-এর দেওয়া label:
এগুলো বিস্তারিত দেখা মূল্যবান। প্রথম দুটো সংখ্যা, একটা 6 ও একটা 5, আমাদের ensemble-এর প্রকৃত ভুল। তবে এগুলো বোধগম্য ভুলও — এমন ভুল মানুষও যুক্তিসঙ্গতভাবে করতে পারে। ওই 6-টা সত্যিই অনেকটা 0-এর মতো দেখায়, আর 5-টা অনেকটা 3-এর মতো। তৃতীয় ছবি, ধরা হয় একটা 8, আমার কাছে আসলে বেশি 9-এর মতো লাগে। তাই আমি এখানে network ensemble-এর পক্ষে: যিনি মূলত সংখ্যাটি এঁকেছেন তাঁর চেয়ে এটা ভালো কাজ করেছে বলেই মনে করি। অন্যদিকে, চতুর্থ ছবি, 6-টা, সত্যিই আমাদের network-এর কাছে খারাপভাবে classify হয়েছে বলে মনে হয়।
এভাবে চলতে থাকে। বেশিরভাগ ক্ষেত্রে আমাদের network-এর পছন্দ অন্তত যুক্তিসঙ্গত মনে হয়, আর কিছু ক্ষেত্রে সংখ্যাটি লেখা মূল ব্যক্তির চেয়ে ভালো classify করেছে। সামগ্রিকভাবে আমাদের network ব্যতিক্রমী কর্মক্ষমতা দেয়, বিশেষত যখন ভাবো এটা 9,967টি ছবি সঠিকভাবে classify করেছে যা দেখানো হয়নি। সেই প্রেক্ষাপটে এখানকার কয়েকটি স্পষ্ট ভুল বেশ বোধগম্য মনে হয়। এমনকি একজন সতর্ক মানুষও মাঝে মাঝে ভুল করে। তাই আমি আশা করি কেবল একজন অত্যন্ত সতর্ক ও পদ্ধতিগত মানুষই এর চেয়ে অনেক ভালো করতে পারবে। আমাদের network মানুষের কর্মক্ষমতার কাছাকাছি পৌঁছে যাচ্ছে।
আমরা কেন কেবল fully-connected layer-এ dropout প্রয়োগ করলাম: উপরের code-এর দিকে মনোযোগ দিয়ে দেখলে লক্ষ করবে আমরা dropout কেবল network-এর fully-connected অংশে প্রয়োগ করেছি, convolutional layer-এ নয়। নীতিগতভাবে আমরা convolutional layer-এও একই রকম পদ্ধতি প্রয়োগ করতে পারতাম। কিন্তু আসলে দরকার নেই: convolutional layer-এর overfitting-এর বিরুদ্ধে যথেষ্ট অন্তর্নিহিত প্রতিরোধ আছে। কারণ shared weight মানে convolutional filter পুরো ছবি থেকে শিখতে বাধ্য। এটা তাদের training data-র স্থানীয় idiosyncrasy ধরে ফেলার সম্ভাবনা কমায়। তাই dropout-এর মতো অন্য regularizer প্রয়োগের কম প্রয়োজন।
আরও দূর যাওয়া: MNIST-এ কর্মক্ষমতা আরও উন্নত করা সম্ভব। Rodrigo Benenson একটা তথ্যপূর্ণ summary page সংকলন করেছেন, যা বছরের পর বছর অগ্রগতি দেখায়, গবেষণাপত্রের link সহ। এর অনেক গবেষণাপত্রই আমরা যেসব network ব্যবহার করছি তার অনুরূপ ধারায় deep convolutional network ব্যবহার করে। গবেষণাপত্রগুলো ঘাঁটলে অনেক কৌতূহলোদ্দীপক কৌশল পাবে, এবং সেগুলোর কিছু বাস্তবায়ন করে মজা পেতে পারো। তা করলে দ্রুত train হয় এমন একটা সরল network দিয়ে বাস্তবায়ন শুরু করা বুদ্ধিমানের কাজ, যা কী ঘটছে তা দ্রুত বুঝতে সাহায্য করবে।
বেশিরভাগ ক্ষেত্রে আমি এই সাম্প্রতিক কাজের জরিপ করতে যাব না। কিন্তু একটা ব্যতিক্রম না করে পারছি না। এটা Cireșan, Meier, Gambardella ও Schmidhuber-এর একটা ২০১০ গবেষণাপত্র। এই গবেষণাপত্রে আমি যা পছন্দ করি তা হলো এটা কত সরল। Network-টা একটা many-layer neural network, কেবল fully-connected layer ব্যবহার করে (কোনো convolution নেই)। তাঁদের সবচেয়ে সফল network-এর hidden layer-গুলোতে যথাক্রমে , ,, ও neuron ছিল। তাঁরা training data সম্প্রসারণে Simard et al-এর মতো ধারণা ব্যবহার করেছিলেন। কিন্তু সেটা বাদে, কোনো convolutional layer সহ তেমন কোনো কৌশল ব্যবহার করেননি: এটা একটা সাধারণ, vanilla network ছিল, যা যথেষ্ট ধৈর্য থাকলে ১৯৮০-এর দশকেই train করা যেত (যদি MNIST data set থাকত), যথেষ্ট computing power থাকলে। তাঁরা শতাংশ classification accuracy অর্জন করেন, মোটামুটি আমাদেরই সমান। মূল চাবিকাঠি ছিল একটা খুব বড়, খুব deep network ব্যবহার করা, এবং training দ্রুত করতে GPU ব্যবহার করা। এতে তাঁরা অনেক epoch train করতে পারলেন। তাঁরা তাঁদের দীর্ঘ training সময়ের সুবিধা নিয়ে learning rate ক্রমশ থেকে -এ কমালেন। তাঁদের মতো একটা architecture দিয়ে এই ফল মেলানোর চেষ্টা করা একটা মজার অনুশীলন।
আমরা কেন train করতে পারছি? গত অধ্যায়ে আমরা দেখেছি deep, many-layer neural network-এ training-এর মৌলিক বাধা আছে। বিশেষত, আমরা দেখেছি gradient বেশ অস্থির হতে থাকে: output layer থেকে আগের layer-এর দিকে যেতে যেতে gradient হয় vanish হয় (vanishing gradient problem) নয়তো explode হয় (exploding gradient problem)। যেহেতু gradient-ই আমরা train করার সংকেত হিসেবে ব্যবহার করি, এটা সমস্যা তৈরি করে।
আমরা কীভাবে এসব ফল এড়িয়েছি?
অবশ্যই, উত্তর হলো আমরা এসব ফল এড়াইনি। বরং আমরা কয়েকটি কাজ করেছি যা আমাদের যেভাবেই হোক এগিয়ে যেতে সাহায্য করে। বিশেষত: (১) Convolutional layer ব্যবহার করায় ওই layer-গুলোর parameter-সংখ্যা ব্যাপকভাবে কমে, learning সমস্যা অনেক সহজ হয়; (২) আরও শক্তিশালী regularization কৌশল (বিশেষত dropout ও convolutional layer) ব্যবহার করে overfitting কমানো, যা না হলে আরও জটিল network-এ বড় সমস্যা; (৩) sigmoid neuron-এর বদলে rectified linear unit ব্যবহার করে training দ্রুত করা — অভিজ্ঞতাভিত্তিকভাবে প্রায়ই - গুণ; (৪) GPU ব্যবহার এবং দীর্ঘ সময় train করতে রাজি থাকা। বিশেষত, আমাদের চূড়ান্ত পরীক্ষায় আমরা raw MNIST training data-র গুণ বড় একটা data set দিয়ে epoch train করেছি। বইয়ের আগে আমরা বেশিরভাগ সময় শুধু raw training data দিয়ে epoch train করেছি। (৩) ও (৪) মিলিয়ে যেন আমরা আগের চেয়ে প্রায় গুণ দীর্ঘ train করেছি।
তোমার প্রতিক্রিয়া হতে পারে "এই? deep network train করতে আমাদের শুধু এটুকুই করতে হলো? এত হইচই কীসের?"
অবশ্যই, আমরা আরও কিছু ধারণাও ব্যবহার করেছি: যথেষ্ট বড় data set ব্যবহার করা (overfitting এড়াতে); সঠিক cost function ব্যবহার করা (learning slowdown এড়াতে); ভালো weight initialization ব্যবহার করা (এ-ও neuron saturation-জনিত learning slowdown এড়াতে); algorithmic-ভাবে training data সম্প্রসারণ করা। আমরা আগের অধ্যায়ে এসব ও অন্যান্য ধারণা আলোচনা করেছি, এবং বেশিরভাগ ক্ষেত্রে এই অধ্যায়ে সামান্য মন্তব্যেই সেগুলো পুনর্ব্যবহার করতে পেরেছি।
তবে এটা সত্যিই একটা বেশ সরল ধারণার সেট। সরল, কিন্তু একসাথে ব্যবহার করলে শক্তিশালী। Deep learning শুরু করা আসলে বেশ সহজই হয়ে দাঁড়াল!
এই network-গুলো আসলে কতটা deep? Convolutional-pooling layer-কে single layer হিসেবে গণনা করলে, আমাদের চূড়ান্ত architecture-এ টি hidden layer। এমন একটা network কি সত্যিই deep network বলে অভিহিত হওয়ার যোগ্য? অবশ্যই, টি hidden layer আমরা আগে যে shallow network পড়েছিলাম তার চেয়ে অনেক বেশি। সেগুলোর বেশিরভাগের কেবল একটা hidden layer ছিল, কখনো টি। অন্যদিকে, ২০১৫ সাল নাগাদ state-of-the-art deep network-এর কখনো কয়েক ডজন hidden layer থাকে। আমি কখনো কখনো শুনেছি মানুষ একটা "তোমার-চেয়ে-গভীর" মনোভাব নেয়, ভাবে hidden layer-সংখ্যায় প্রতিবেশীর সাথে পাল্লা না দিলে তুমি আসলে deep learning করছ না। আমি এই মনোভাবের প্রতি সহানুভূতিশীল নই, আংশিকভাবে কারণ এটা deep learning-এর সংজ্ঞাকে মুহূর্তের-ফলের উপর নির্ভরশীল করে তোলে। Deep learning-এর প্রকৃত breakthrough ছিল এটা উপলব্ধি করা যে ২০০০-এর দশকের মাঝামাঝি পর্যন্ত প্রভাবশালী - ও -hidden layer-এর shallow network-এর বাইরে যাওয়া ব্যবহারিক। সেটা সত্যিই একটা তাৎপর্যপূর্ণ breakthrough ছিল, যা অনেক বেশি expressive model অন্বেষণের পথ খুলে দেয়। কিন্তু তার বাইরে, layer-সংখ্যা মৌলিকভাবে প্রাথমিক আগ্রহের বিষয় নয়। বরং deeper network ব্যবহার অন্য লক্ষ্য — যেমন ভালো classification accuracy — অর্জনে সাহায্য করার একটা হাতিয়ার।
পদ্ধতি সম্পর্কে একটি কথা: এই অংশে আমরা মসৃণভাবে single hidden-layer shallow network থেকে many-layer convolutional network-এ গেলাম। সব এত সহজ মনে হলো! আমরা একটা পরিবর্তন করি এবং বেশিরভাগ ক্ষেত্রে একটা উন্নতি পাই। তুমি যদি পরীক্ষা-নিরীক্ষা শুরু করো, আমি নিশ্চয়তা দিতে পারি সবসময় এত মসৃণ হবে না। কারণ আমি একটা পরিষ্কার-করা আখ্যান উপস্থাপন করেছি, অনেক পরীক্ষা — অনেক ব্যর্থ পরীক্ষা সহ — বাদ দিয়ে। এই পরিষ্কার-করা আখ্যান আশা করি মূল ধারণাগুলো স্পষ্ট করতে সাহায্য করবে। কিন্তু এটা একটা অসম্পূর্ণ ধারণা দেওয়ার ঝুঁকিও বহন করে। একটা ভালো, কার্যকর network পেতে অনেক trial and error ও মাঝে মাঝে হতাশা জড়িত থাকতে পারে। বাস্তবে তোমার বেশ খানিকটা পরীক্ষা-নিরীক্ষায় জড়িত হওয়ার আশা করা উচিত। সেই প্রক্রিয়া দ্রুত করতে অধ্যায় ৩-এর neural network-এর hyper-parameter কীভাবে বাছতে হয় সেই আলোচনা আবার দেখা সহায়ক হতে পারে।
আমাদের convolutional network-এর code
ঠিক আছে, চলো আমাদের program network3.py-এর code-টা দেখি। কাঠামোগতভাবে এটা network2.py-এর মতো — অধ্যায় ৩-এ তৈরি program — যদিও Theano ব্যবহারের কারণে বিস্তারিত ভিন্ন। আমরা শুরু করব FullyConnectedLayer class দিয়ে, যা বইয়ের আগে পড়া layer-গুলোর মতোই। এই হলো code (নিচে আলোচনা):
class FullyConnectedLayer(object):
def __init__(self, n_in, n_out, activation_fn=sigmoid, p_dropout=0.0):
self.n_in = n_in
self.n_out = n_out
self.activation_fn = activation_fn
self.p_dropout = p_dropout
# Initialize weights and biases
self.w = theano.shared(
np.asarray(
np.random.normal(
loc=0.0, scale=np.sqrt(1.0/n_out), size=(n_in, n_out)),
dtype=theano.config.floatX),
name='w', borrow=True)
self.b = theano.shared(
np.asarray(np.random.normal(loc=0.0, scale=1.0, size=(n_out,)),
dtype=theano.config.floatX),
name='b', borrow=True)
self.params = [self.w, self.b]
def set_inpt(self, inpt, inpt_dropout, mini_batch_size):
self.inpt = inpt.reshape((mini_batch_size, self.n_in))
self.output = self.activation_fn(
(1-self.p_dropout)*T.dot(self.inpt, self.w) + self.b)
self.y_out = T.argmax(self.output, axis=1)
self.inpt_dropout = dropout_layer(
inpt_dropout.reshape((mini_batch_size, self.n_in)), self.p_dropout)
self.output_dropout = self.activation_fn(
T.dot(self.inpt_dropout, self.w) + self.b)
def accuracy(self, y):
"Return the accuracy for the mini-batch."
return T.mean(T.eq(y, self.y_out))__init__ method-এর বেশিরভাগটাই স্ব-ব্যাখ্যামূলক, তবে কয়েকটি মন্তব্য code স্পষ্ট করতে সাহায্য করতে পারে। যথারীতি আমরা weight ও bias-গুলো উপযুক্ত standard deviation-সহ normal random variable হিসেবে এলোমেলোভাবে initialize করি। এটা করা লাইনগুলো একটু ভীতিকর দেখায়। তবে জটিলতার বেশিরভাগটাই কেবল weight ও bias-গুলোকে Theano যাকে shared variable বলে তাতে load করা। এটা নিশ্চিত করে যে এই variable-গুলো GPU-তে process করা যাবে, যদি একটা থাকে। আমরা এর বিস্তারিতে বেশি যাব না। আগ্রহী হলে Theano documentation ঘাঁটতে পারো। লক্ষ করো, এই weight ও bias initialization sigmoid activation function-এর জন্য নকশা করা (আগে আলোচিত)। আদর্শভাবে আমরা tanh ও rectified linear function-এর মতো activation function-এর জন্য weight ও bias কিছুটা ভিন্নভাবে initialize করতাম। এটা নিচের সমস্যায় আরও আলোচনা করা হয়েছে। __init__ method শেষ হয় self.params = [self.w, self.b] দিয়ে। এটা layer-এর সাথে যুক্ত সব শেখার-যোগ্য parameter একত্র করার একটা সুবিধাজনক উপায়। পরে Network.SGD method params attribute ব্যবহার করে বের করবে একটা Network instance-এ কোন variable শিখতে পারে।
set_inpt method layer-এর input সেট করতে এবং সংশ্লিষ্ট output হিসাব করতে ব্যবহৃত হয়। আমি input-এর বদলে inpt নাম ব্যবহার করি কারণ input Python-এ একটা built-in function, আর built-in নিয়ে নাড়াচাড়া করলে অপ্রত্যাশিত আচরণ ও কঠিন-নির্ণেয় bug হতে থাকে। লক্ষ করো আমরা আসলে input দুটি আলাদা উপায়ে সেট করি: self.inpt ও self.inpt_dropout হিসেবে। এটা করা হয় কারণ training-এর সময় আমরা হয়তো dropout ব্যবহার করতে চাই। তেমন হলে আমরা একটা ভগ্নাংশ self.p_dropout neuron সরিয়ে দিতে চাই। set_inpt method-এর দ্বিতীয়-শেষ লাইনের dropout_layer function ঠিক এটাই করছে। তাই self.inpt_dropout ও self.output_dropout training-এর সময় ব্যবহৃত হয়, আর self.inpt ও self.output অন্য সব কাজে — যেমন validation ও test data-তে accuracy মূল্যায়নে।
ConvPoolLayer ও SoftmaxLayer class-এর সংজ্ঞা FullyConnectedLayer-এর মতোই। আসলে এরা এত কাছাকাছি যে এখানে code আলাদা করে তুলে দিচ্ছি না। আগ্রহী হলে এই অংশের পরে network3.py-এর পূর্ণ listing দেখতে পারো।
তবে কয়েকটি ছোট পার্থক্য উল্লেখ করার মতো। সবচেয়ে স্পষ্টভাবে, ConvPoolLayer ও SoftmaxLayer উভয়েই আমরা সেই layer type-এর উপযুক্ত উপায়ে output activation হিসাব করি। সৌভাগ্যবশত Theano এটা সহজ করে দেয়, convolution, max-pooling ও softmax function হিসাব করার built-in operation দিয়ে।
কম স্পষ্টভাবে, যখন আমরা softmax layer পরিচয় করিয়েছিলাম, কখনো আলোচনা করিনি কীভাবে weight ও bias initialize করতে হয়। অন্যত্র আমরা যুক্তি দিয়েছি যে sigmoid layer-এর জন্য আমাদের উপযুক্তভাবে parameterized normal random variable ব্যবহার করে weight initialize করা উচিত। কিন্তু সেই heuristic যুক্তি sigmoid neuron-এর জন্য নির্দিষ্ট ছিল (এবং কিছু সংশোধনসহ tanh neuron-এর জন্য)। তবে softmax layer-এ ওই যুক্তি প্রয়োগ করার কোনো বিশেষ কারণ নেই। তাই ওই initialization আবার প্রয়োগ করার কোনো a priori কারণ নেই। তা না করে আমি সব weight ও bias -তে initialize করব। এটা একটা বেশ ad hoc পদ্ধতি, কিন্তু বাস্তবে যথেষ্ট ভালো কাজ করে।
ঠিক আছে, আমরা সব layer class দেখলাম। Network class-এর ব্যাপারটা কী? চলো __init__ method দিয়ে শুরু করি:
class Network(object):
def __init__(self, layers, mini_batch_size):
"""Takes a list of `layers`, describing the network architecture, and
a value for the `mini_batch_size` to be used during training
by stochastic gradient descent.
"""
self.layers = layers
self.mini_batch_size = mini_batch_size
self.params = [param for layer in self.layers for param in layer.params]
self.x = T.matrix("x")
self.y = T.ivector("y")
init_layer = self.layers[0]
init_layer.set_inpt(self.x, self.x, self.mini_batch_size)
for j in xrange(1, len(self.layers)):
prev_layer, layer = self.layers[j-1], self.layers[j]
layer.set_inpt(
prev_layer.output, prev_layer.output_dropout, self.mini_batch_size)
self.output = self.layers[-1].output
self.output_dropout = self.layers[-1].output_dropoutএর বেশিরভাগটাই স্ব-ব্যাখ্যামূলক, বা প্রায়। লাইন self.params = [param for layer in ...] প্রতিটি layer-এর parameter একটা single list-এ একত্র করে। উপরে যেমন আশা করা হয়েছিল, Network.SGD method self.params ব্যবহার করে বের করবে Network-এ কোন variable শিখতে পারে। লাইন self.x = T.matrix("x") ও self.y = T.ivector("y") x ও y নামে Theano symbolic variable সংজ্ঞায়িত করে। এগুলো network-এর input ও কাঙ্ক্ষিত output প্রকাশ করতে ব্যবহৃত হবে।
এটা একটা Theano tutorial নয়, তাই এসব যে symbolic variable তার মানে কী তার গভীরে আমরা বেশি যাব না। কিন্তু মোটামুটি ধারণাটা হলো এরা গাণিতিক variable প্রকাশ করে, সুনির্দিষ্ট মান নয়। এমন variable নিয়ে যা যা করা যায় তার সবই আমরা করতে পারি: যোগ, বিয়োগ, গুণ, function প্রয়োগ, ইত্যাদি। আসলে Theano এমন symbolic variable নিয়ে কাজ করার অনেক উপায় দেয়, যেমন convolution, max-pooling, ইত্যাদি। কিন্তু বড় জয়টা হলো backpropagation algorithm-এর একটা খুব সাধারণ রূপ ব্যবহার করে দ্রুত symbolic differentiation করার সক্ষমতা। এটা নানা ধরনের network architecture-এ stochastic gradient descent প্রয়োগ করতে অত্যন্ত উপযোগী। বিশেষত, পরের কয়েকটি code লাইন network থেকে symbolic output সংজ্ঞায়িত করে। আমরা শুরু করি initial layer-এ input সেট করে, এই লাইন দিয়ে:
init_layer.set_inpt(self.x, self.x, self.mini_batch_size)লক্ষ করো input একবারে এক mini-batch করে সেট করা হয়, এ কারণেই mini-batch size সেখানে আছে। আরও লক্ষ করো আমরা input self.x দুবার পাস করি: কারণ আমরা network-কে দুই ভিন্ন উপায়ে ব্যবহার করতে পারি (dropout সহ বা ছাড়া)। তারপর for loop symbolic variable self.x-কে Network-এর layer-গুলোর মধ্য দিয়ে সামনে propagate করে। এটা আমাদের চূড়ান্ত output ও output_dropout attribute সংজ্ঞায়িত করতে দেয়, যা symbolic-ভাবে Network-এর output প্রকাশ করে।
এখন আমরা বুঝে গেছি একটা Network কীভাবে initialize হয়, চলো দেখি এটা কীভাবে train করা হয়, SGD method ব্যবহার করে। Code দেখতে দীর্ঘ, কিন্তু এর কাঠামো আসলে বেশ সরল। code-এর পরে ব্যাখ্যামূলক মন্তব্য।
def SGD(self, training_data, epochs, mini_batch_size, eta,
validation_data, test_data, lmbda=0.0):
"""Train the network using mini-batch stochastic gradient descent."""
training_x, training_y = training_data
validation_x, validation_y = validation_data
test_x, test_y = test_data
# compute number of minibatches for training, validation and testing
num_training_batches = size(training_data)/mini_batch_size
num_validation_batches = size(validation_data)/mini_batch_size
num_test_batches = size(test_data)/mini_batch_size
# define the (regularized) cost function, symbolic gradients, and updates
l2_norm_squared = sum([(layer.w**2).sum() for layer in self.layers])
cost = self.layers[-1].cost(self)+\
0.5*lmbda*l2_norm_squared/num_training_batches
grads = T.grad(cost, self.params)
updates = [(param, param-eta*grad)
for param, grad in zip(self.params, grads)]
# define functions to train a mini-batch, and to compute the
# accuracy in validation and test mini-batches.
i = T.lscalar() # mini-batch index
train_mb = theano.function(
[i], cost, updates=updates,
givens={
self.x:
training_x[i*self.mini_batch_size: (i+1)*self.mini_batch_size],
self.y:
training_y[i*self.mini_batch_size: (i+1)*self.mini_batch_size]
})
validate_mb_accuracy = theano.function(
[i], self.layers[-1].accuracy(self.y),
givens={
self.x:
validation_x[i*self.mini_batch_size: (i+1)*self.mini_batch_size],
self.y:
validation_y[i*self.mini_batch_size: (i+1)*self.mini_batch_size]
})
test_mb_accuracy = theano.function(
[i], self.layers[-1].accuracy(self.y),
givens={
self.x:
test_x[i*self.mini_batch_size: (i+1)*self.mini_batch_size],
self.y:
test_y[i*self.mini_batch_size: (i+1)*self.mini_batch_size]
})
self.test_mb_predictions = theano.function(
[i], self.layers[-1].y_out,
givens={
self.x:
test_x[i*self.mini_batch_size: (i+1)*self.mini_batch_size]
})
# Do the actual training
best_validation_accuracy = 0.0
for epoch in xrange(epochs):
for minibatch_index in xrange(num_training_batches):
iteration = num_training_batches*epoch+minibatch_index
if iteration % 1000 == 0:
print("Training mini-batch number {0}".format(iteration))
cost_ij = train_mb(minibatch_index)
if (iteration+1) % num_training_batches == 0:
validation_accuracy = np.mean(
[validate_mb_accuracy(j) for j in xrange(num_validation_batches)])
print("Epoch {0}: validation accuracy {1:.2%}".format(
epoch, validation_accuracy))
if validation_accuracy >= best_validation_accuracy:
print("This is the best validation accuracy to date.")
best_validation_accuracy = validation_accuracy
best_iteration = iteration
if test_data:
test_accuracy = np.mean(
[test_mb_accuracy(j) for j in xrange(num_test_batches)])
print('The corresponding test accuracy is {0:.2%}'.format(
test_accuracy))
print("Finished training network.")
print("Best validation accuracy of {0:.2%} obtained at iteration {1}".format(
best_validation_accuracy, best_iteration))
print("Corresponding test accuracy of {0:.2%}".format(test_accuracy))প্রথম কয়েকটি লাইন সরল, dataset-গুলোকে ও অংশে আলাদা করছে, এবং প্রতিটি dataset-এ ব্যবহৃত mini-batch-সংখ্যা হিসাব করছে। পরের কয়েকটি লাইন আরও কৌতূহলোদ্দীপক, এবং দেখায় Theano নিয়ে কাজ করা কীসে মজাদার করে তোলে। চলো লাইনগুলো এখানে স্পষ্ট করে তুলে ধরি:
# define the (regularized) cost function, symbolic gradients, and updates
l2_norm_squared = sum([(layer.w**2).sum() for layer in self.layers])
cost = self.layers[-1].cost(self)+\
0.5*lmbda*l2_norm_squared/num_training_batches
grads = T.grad(cost, self.params)
updates = [(param, param-eta*grad)
for param, grad in zip(self.params, grads)]এই লাইনগুলোতে আমরা symbolic-ভাবে regularized log-likelihood cost function সেট করি, grads function-এ সংশ্লিষ্ট derivative হিসাব করি, এবং সংশ্লিষ্ট parameter update গণনা করি। Theano আমাদের এই কয়েকটি লাইনেই এর সবটুকু অর্জন করতে দেয়। একমাত্র যা গোপন তা হলো cost হিসাব করতে output layer-এর cost method-এ একটা call জড়িত; সেই code network3.py-এর অন্যত্র। তবে সেই code-ও সংক্ষিপ্ত ও সরল। এসব সংজ্ঞায়িত হওয়ার পর train_mb function সংজ্ঞায়িত করার মঞ্চ প্রস্তুত — এটা একটা Theano symbolic function, যা একটা mini-batch index দিলে updates ব্যবহার করে Network-এর parameter update করে। একইভাবে validate_mb_accuracy ও test_mb_accuracy validation বা test data-র যেকোনো mini-batch-এ Network-এর accuracy হিসাব করে। এসব function-এর উপর গড় করে আমরা পুরো validation ও test data set-এ accuracy হিসাব করতে পারব।
SGD method-এর বাকি অংশ স্ব-ব্যাখ্যামূলক — আমরা কেবল epoch-গুলোর উপর iterate করি, বারবার training data-র mini-batch-এ network train করি, এবং validation ও test accuracy হিসাব করি।
ঠিক আছে, এখন আমরা network3.py-এর সবচেয়ে গুরুত্বপূর্ণ code-অংশগুলো বুঝেছি। চলো পুরো program-টায় একটা সংক্ষিপ্ত নজর দিই। বিস্তারিত পড়ার দরকার নেই, কিন্তু চোখ বুলিয়ে নিতে এবং যে অংশগুলো তোমার মন কাড়ে সেগুলোর গভীরে নেমে যেতে মজা পেতে পারো। এটা সত্যিই বোঝার সেরা উপায় অবশ্যই হলো এটা পরিবর্তন করা, বাড়তি feature যোগ করা, বা আরও সুন্দরভাবে করা যায় বলে মনে হওয়া যেকোনো কিছু refactor করা। code-এর পরে কয়েকটি সমস্যা আছে যা কিছু শুরুর পরামর্শ দেয়। এই হলো code:
"""network3.py
~~~~~~~~~~~~~~
A Theano-based program for training and running simple neural
networks.
Supports several layer types (fully connected, convolutional, max
pooling, softmax), and activation functions (sigmoid, tanh, and
rectified linear units, with more easily added).
When run on a CPU, this program is much faster than network.py and
network2.py. However, unlike network.py and network2.py it can also
be run on a GPU, which makes it faster still.
Because the code is based on Theano, the code is different in many
ways from network.py and network2.py. However, where possible I have
tried to maintain consistency with the earlier programs. In
particular, the API is similar to network2.py. Note that I have
focused on making the code simple, easily readable, and easily
modifiable. It is not optimized, and omits many desirable features.
This program incorporates ideas from the Theano documentation on
convolutional neural nets (notably,
http://deeplearning.net/tutorial/lenet.html ), from Misha Denil's
implementation of dropout (https://github.com/mdenil/dropout ), and
from Chris Olah (http://colah.github.io ).
Written for Theano 0.6 and 0.7, needs some changes for more recent
versions of Theano.
"""
#### Libraries
# Standard library
import cPickle
import gzip
# Third-party libraries
import numpy as np
import theano
import theano.tensor as T
from theano.tensor.nnet import conv
from theano.tensor.nnet import softmax
from theano.tensor import shared_randomstreams
from theano.tensor.signal import downsample
# Activation functions for neurons
def linear(z): return z
def ReLU(z): return T.maximum(0.0, z)
from theano.tensor.nnet import sigmoid
from theano.tensor import tanh
#### Constants
GPU = True
if GPU:
print "Trying to run under a GPU. If this is not desired, then modify "+\
"network3.py\nto set the GPU flag to False."
try: theano.config.device = 'gpu'
except: pass # it's already set
theano.config.floatX = 'float32'
else:
print "Running with a CPU. If this is not desired, then the modify "+\
"network3.py to set\nthe GPU flag to True."
#### Load the MNIST data
def load_data_shared(filename="../data/mnist.pkl.gz"):
f = gzip.open(filename, 'rb')
training_data, validation_data, test_data = cPickle.load(f)
f.close()
def shared(data):
"""Place the data into shared variables. This allows Theano to copy
the data to the GPU, if one is available.
"""
shared_x = theano.shared(
np.asarray(data[0], dtype=theano.config.floatX), borrow=True)
shared_y = theano.shared(
np.asarray(data[1], dtype=theano.config.floatX), borrow=True)
return shared_x, T.cast(shared_y, "int32")
return [shared(training_data), shared(validation_data), shared(test_data)]
#### Main class used to construct and train networks
class Network(object):
def __init__(self, layers, mini_batch_size):
"""Takes a list of `layers`, describing the network architecture, and
a value for the `mini_batch_size` to be used during training
by stochastic gradient descent.
"""
self.layers = layers
self.mini_batch_size = mini_batch_size
self.params = [param for layer in self.layers for param in layer.params]
self.x = T.matrix("x")
self.y = T.ivector("y")
init_layer = self.layers[0]
init_layer.set_inpt(self.x, self.x, self.mini_batch_size)
for j in xrange(1, len(self.layers)):
prev_layer, layer = self.layers[j-1], self.layers[j]
layer.set_inpt(
prev_layer.output, prev_layer.output_dropout, self.mini_batch_size)
self.output = self.layers[-1].output
self.output_dropout = self.layers[-1].output_dropout
def SGD(self, training_data, epochs, mini_batch_size, eta,
validation_data, test_data, lmbda=0.0):
"""Train the network using mini-batch stochastic gradient descent."""
training_x, training_y = training_data
validation_x, validation_y = validation_data
test_x, test_y = test_data
# compute number of minibatches for training, validation and testing
num_training_batches = size(training_data)/mini_batch_size
num_validation_batches = size(validation_data)/mini_batch_size
num_test_batches = size(test_data)/mini_batch_size
# define the (regularized) cost function, symbolic gradients, and updates
l2_norm_squared = sum([(layer.w**2).sum() for layer in self.layers])
cost = self.layers[-1].cost(self)+\
0.5*lmbda*l2_norm_squared/num_training_batches
grads = T.grad(cost, self.params)
updates = [(param, param-eta*grad)
for param, grad in zip(self.params, grads)]
# define functions to train a mini-batch, and to compute the
# accuracy in validation and test mini-batches.
i = T.lscalar() # mini-batch index
train_mb = theano.function(
[i], cost, updates=updates,
givens={
self.x:
training_x[i*self.mini_batch_size: (i+1)*self.mini_batch_size],
self.y:
training_y[i*self.mini_batch_size: (i+1)*self.mini_batch_size]
})
validate_mb_accuracy = theano.function(
[i], self.layers[-1].accuracy(self.y),
givens={
self.x:
validation_x[i*self.mini_batch_size: (i+1)*self.mini_batch_size],
self.y:
validation_y[i*self.mini_batch_size: (i+1)*self.mini_batch_size]
})
test_mb_accuracy = theano.function(
[i], self.layers[-1].accuracy(self.y),
givens={
self.x:
test_x[i*self.mini_batch_size: (i+1)*self.mini_batch_size],
self.y:
test_y[i*self.mini_batch_size: (i+1)*self.mini_batch_size]
})
self.test_mb_predictions = theano.function(
[i], self.layers[-1].y_out,
givens={
self.x:
test_x[i*self.mini_batch_size: (i+1)*self.mini_batch_size]
})
# Do the actual training
best_validation_accuracy = 0.0
for epoch in xrange(epochs):
for minibatch_index in xrange(num_training_batches):
iteration = num_training_batches*epoch+minibatch_index
if iteration % 1000 == 0:
print("Training mini-batch number {0}".format(iteration))
cost_ij = train_mb(minibatch_index)
if (iteration+1) % num_training_batches == 0:
validation_accuracy = np.mean(
[validate_mb_accuracy(j) for j in xrange(num_validation_batches)])
print("Epoch {0}: validation accuracy {1:.2%}".format(
epoch, validation_accuracy))
if validation_accuracy >= best_validation_accuracy:
print("This is the best validation accuracy to date.")
best_validation_accuracy = validation_accuracy
best_iteration = iteration
if test_data:
test_accuracy = np.mean(
[test_mb_accuracy(j) for j in xrange(num_test_batches)])
print('The corresponding test accuracy is {0:.2%}'.format(
test_accuracy))
print("Finished training network.")
print("Best validation accuracy of {0:.2%} obtained at iteration {1}".format(
best_validation_accuracy, best_iteration))
print("Corresponding test accuracy of {0:.2%}".format(test_accuracy))
#### Define layer types
class ConvPoolLayer(object):
"""Used to create a combination of a convolutional and a max-pooling
layer. A more sophisticated implementation would separate the
two, but for our purposes we'll always use them together, and it
simplifies the code, so it makes sense to combine them.
"""
def __init__(self, filter_shape, image_shape, poolsize=(2, 2),
activation_fn=sigmoid):
"""`filter_shape` is a tuple of length 4, whose entries are the number
of filters, the number of input feature maps, the filter height, and the
filter width.
`image_shape` is a tuple of length 4, whose entries are the
mini-batch size, the number of input feature maps, the image
height, and the image width.
`poolsize` is a tuple of length 2, whose entries are the y and
x pooling sizes.
"""
self.filter_shape = filter_shape
self.image_shape = image_shape
self.poolsize = poolsize
self.activation_fn=activation_fn
# initialize weights and biases
n_out = (filter_shape[0]*np.prod(filter_shape[2:])/np.prod(poolsize))
self.w = theano.shared(
np.asarray(
np.random.normal(loc=0, scale=np.sqrt(1.0/n_out), size=filter_shape),
dtype=theano.config.floatX),
borrow=True)
self.b = theano.shared(
np.asarray(
np.random.normal(loc=0, scale=1.0, size=(filter_shape[0],)),
dtype=theano.config.floatX),
borrow=True)
self.params = [self.w, self.b]
def set_inpt(self, inpt, inpt_dropout, mini_batch_size):
self.inpt = inpt.reshape(self.image_shape)
conv_out = conv.conv2d(
input=self.inpt, filters=self.w, filter_shape=self.filter_shape,
image_shape=self.image_shape)
pooled_out = downsample.max_pool_2d(
input=conv_out, ds=self.poolsize, ignore_border=True)
self.output = self.activation_fn(
pooled_out + self.b.dimshuffle('x', 0, 'x', 'x'))
self.output_dropout = self.output # no dropout in the convolutional layers
class FullyConnectedLayer(object):
def __init__(self, n_in, n_out, activation_fn=sigmoid, p_dropout=0.0):
self.n_in = n_in
self.n_out = n_out
self.activation_fn = activation_fn
self.p_dropout = p_dropout
# Initialize weights and biases
self.w = theano.shared(
np.asarray(
np.random.normal(
loc=0.0, scale=np.sqrt(1.0/n_out), size=(n_in, n_out)),
dtype=theano.config.floatX),
name='w', borrow=True)
self.b = theano.shared(
np.asarray(np.random.normal(loc=0.0, scale=1.0, size=(n_out,)),
dtype=theano.config.floatX),
name='b', borrow=True)
self.params = [self.w, self.b]
def set_inpt(self, inpt, inpt_dropout, mini_batch_size):
self.inpt = inpt.reshape((mini_batch_size, self.n_in))
self.output = self.activation_fn(
(1-self.p_dropout)*T.dot(self.inpt, self.w) + self.b)
self.y_out = T.argmax(self.output, axis=1)
self.inpt_dropout = dropout_layer(
inpt_dropout.reshape((mini_batch_size, self.n_in)), self.p_dropout)
self.output_dropout = self.activation_fn(
T.dot(self.inpt_dropout, self.w) + self.b)
def accuracy(self, y):
"Return the accuracy for the mini-batch."
return T.mean(T.eq(y, self.y_out))
class SoftmaxLayer(object):
def __init__(self, n_in, n_out, p_dropout=0.0):
self.n_in = n_in
self.n_out = n_out
self.p_dropout = p_dropout
# Initialize weights and biases
self.w = theano.shared(
np.zeros((n_in, n_out), dtype=theano.config.floatX),
name='w', borrow=True)
self.b = theano.shared(
np.zeros((n_out,), dtype=theano.config.floatX),
name='b', borrow=True)
self.params = [self.w, self.b]
def set_inpt(self, inpt, inpt_dropout, mini_batch_size):
self.inpt = inpt.reshape((mini_batch_size, self.n_in))
self.output = softmax((1-self.p_dropout)*T.dot(self.inpt, self.w) + self.b)
self.y_out = T.argmax(self.output, axis=1)
self.inpt_dropout = dropout_layer(
inpt_dropout.reshape((mini_batch_size, self.n_in)), self.p_dropout)
self.output_dropout = softmax(T.dot(self.inpt_dropout, self.w) + self.b)
def cost(self, net):
"Return the log-likelihood cost."
return -T.mean(T.log(self.output_dropout)[T.arange(net.y.shape[0]), net.y])
def accuracy(self, y):
"Return the accuracy for the mini-batch."
return T.mean(T.eq(y, self.y_out))
#### Miscellanea
def size(data):
"Return the size of the dataset `data`."
return data[0].get_value(borrow=True).shape[0]
def dropout_layer(layer, p_dropout):
srng = shared_randomstreams.RandomStreams(
np.random.RandomState(0).randint(999999))
mask = srng.binomial(n=1, p=1-p_dropout, size=layer.shape)
return layer*T.cast(mask, theano.config.floatX)Image recognition-এ সাম্প্রতিক অগ্রগতি
১৯৯৮ সালে, যে বছর MNIST পরিচয় করানো হয়, একটা state-of-the-art workstation train করতে কয়েক সপ্তাহ লাগত — তাও আমরা আজ একটা GPU ও এক ঘণ্টারও কম training দিয়ে যা অর্জন করি তার চেয়ে অনেক খারাপ accuracy পেতে। তাই MNIST আর এমন সমস্যা নয় যা প্রাপ্য কৌশলের সীমা ঠেলে দেয়; বরং training-এর গতির মানে এটা শেখানো ও শেখার উদ্দেশ্যে একটা ভালো সমস্যা। ইতিমধ্যে গবেষণার মনোযোগ এগিয়ে গেছে, এবং আধুনিক কাজ অনেক বেশি চ্যালেঞ্জিং image recognition সমস্যা নিয়ে। এই অংশে আমি neural network দিয়ে image recognition নিয়ে সাম্প্রতিক কিছু কাজ সংক্ষেপে বর্ণনা করছি।
এই অংশ বইয়ের বেশিরভাগ অংশ থেকে ভিন্ন। বই জুড়ে আমি স্থায়ী আগ্রহের সম্ভাবনাময় ধারণার উপর জোর দিয়েছি — যেমন backpropagation, regularization ও convolutional network। আমি এমন ফল এড়ানোর চেষ্টা করেছি যা লেখার সময় চলতি কিন্তু যার দীর্ঘমেয়াদি মূল্য অজানা। বিজ্ঞানে এমন ফল প্রায়শই ক্ষণস্থায়ী, যা মিলিয়ে যায় এবং সামান্যই স্থায়ী প্রভাব রাখে। এ অবস্থায় একজন সংশয়বাদী বলতে পারেন: "image recognition-এ সাম্প্রতিক অগ্রগতি কি এমনই ক্ষণস্থায়ী জিনিসের উদাহরণ নয়? আরও দু-তিন বছরে ব্যাপারটা এগিয়ে যাবে। তাহলে এসব ফল কি কেবল ওই কয়েকজন বিশেষজ্ঞের কাছেই আগ্রহের, যাঁরা একদম সীমান্তে প্রতিযোগিতা করতে চান? এ নিয়ে আলোচনার কী দরকার?"
এমন সংশয়বাদী এ ব্যাপারে ঠিক যে সাম্প্রতিক গবেষণাপত্রের কিছু সূক্ষ্ম বিস্তারিত ক্রমশ গুরুত্ব হারাবে। তবে গত কয়েক বছরে অত্যন্ত কঠিন image recognition কাজে deep net ব্যবহার করে অসাধারণ উন্নতি দেখা গেছে। কল্পনা করো ২১০০ সালে একজন বিজ্ঞান-ইতিহাসবিদ computer vision নিয়ে লিখছেন। তাঁরা ২০১১ থেকে ২০১৫ (এবং সম্ভবত আরও কয়েক বছর) চিহ্নিত করবেন deep convolutional net-চালিত বিশাল breakthrough-এর সময় হিসেবে। এর মানে এই নয় যে ২১০০ সালে deep convolutional net এখনও ব্যবহৃত হবে, dropout, rectified linear unit প্রভৃতি সূক্ষ্ম ধারণা তো দূরের কথা। কিন্তু এর মানে এই যে ধারণার ইতিহাসে এই মুহূর্তে একটা গুরুত্বপূর্ণ পরিবর্তন ঘটছে। এটা অনেকটা পরমাণু আবিষ্কার বা antibiotic উদ্ভাবন দেখার মতো: ঐতিহাসিক মাপের উদ্ভাবন ও আবিষ্কার। তাই যদিও আমরা খুঁটিনাটিতে গভীরে যাব না, এই উত্তেজনাপূর্ণ আবিষ্কারগুলো সম্পর্কে কিছু ধারণা নেওয়া মূল্যবান।
২০১২-এর LRMD গবেষণাপত্র: Stanford ও Google-এর একদল গবেষকের একটা ২০১২ গবেষণাপত্র দিয়ে শুরু করি। প্রথম চার লেখকের শেষ নাম অনুসারে আমি একে LRMD বলব। LRMD একটা neural network ব্যবহার করে ImageNet থেকে ছবি classify করেছিল, যা একটা খুব চ্যালেঞ্জিং image recognition সমস্যা। তাঁরা যে ২০১১ ImageNet data ব্যবহার করেছিলেন তাতে ছিল 1 কোটি 60 লক্ষ full color ছবি, 20 হাজার category-তে। ছবিগুলো খোলা net থেকে crawl করে Amazon-এর Mechanical Turk service-এর কর্মীরা classify করেছিলেন। এই হলো কয়েকটি ImageNet ছবি:




এগুলো যথাক্রমে beading plane, brown root rot fungus, scalded milk ও common roundworm category-র ছবি। চ্যালেঞ্জ খুঁজলে আমি তোমাকে ImageNet-এর hand tools-এর তালিকা দেখার পরামর্শ দিই, যা beading plane, block plane, chamfer plane এবং আরও প্রায় এক ডজন ধরনের plane-এর মধ্যে পার্থক্য করে। তোমার কথা জানি না, কিন্তু আমি এই সব tool-এর ধরন আত্মবিশ্বাসের সাথে আলাদা করতে পারি না। এটা স্পষ্টতই MNIST-এর চেয়ে অনেক বেশি চ্যালেঞ্জিং image recognition কাজ! LRMD-র network ImageNet ছবি সঠিকভাবে classify করায় একটা সম্মানজনক শতাংশ accuracy পেয়েছিল। এটা চিত্তাকর্ষক না শোনালেও আগের সেরা ফল শতাংশ accuracy-র উপর একটা বিশাল উন্নতি ছিল। এই লাফ ইঙ্গিত দিল যে neural network ImageNet-এর মতো অত্যন্ত চ্যালেঞ্জিং image recognition কাজে একটা শক্তিশালী approach দিতে পারে।
২০১২-এর KSH গবেষণাপত্র: LRMD-র কাজের পর আসে Krizhevsky, Sutskever ও Hinton-এর (KSH) একটা ২০১২ গবেষণাপত্র। KSH ImageNet data-র একটা সীমিত subset ব্যবহার করে একটা deep convolutional neural network train ও test করেন। তাঁরা যে subset ব্যবহার করেছিলেন তা একটা জনপ্রিয় machine learning প্রতিযোগিতা — ImageNet Large-Scale Visual Recognition Challenge (ILSVRC) থেকে এসেছিল। প্রতিযোগিতার dataset ব্যবহার তাঁদের নিজেদের approach অন্য শীর্ষ কৌশলের সাথে তুলনা করার একটা ভালো উপায় দিয়েছিল। ILSVRC-2012 training set-এ ছিল প্রায় 12 লক্ষ ImageNet ছবি, 1,000 category থেকে নেওয়া। Validation ও test set-এ যথাক্রমে 50,000 ও 150,000 ছবি ছিল, একই 1,000 category থেকে নেওয়া।
ILSVRC প্রতিযোগিতা চালানোর একটা অসুবিধা হলো অনেক ImageNet ছবিতে একাধিক বস্তু থাকে। ধরো একটা ছবিতে একটা labrador retriever একটা soccer ball-এর পিছনে ছুটছে। ছবিটির তথাকথিত "সঠিক" ImageNet classification হতে পারে labrador retriever। একটা algorithm ছবিটিকে soccer ball হিসেবে label করলে কি তাকে শাস্তি দেওয়া উচিত? এই অস্পষ্টতার কারণে একটা algorithm সঠিক ধরা হতো যদি প্রকৃত ImageNet classification algorithm-এর বিবেচিত সবচেয়ে সম্ভাব্য টি classification-এর মধ্যে থাকত। এই top- নিরিখে KSH-র deep convolutional network শতাংশ accuracy অর্জন করে, পরবর্তী-সেরা প্রতিযোগী entry-র চেয়ে অনেক ভালো, যা শতাংশ accuracy অর্জন করেছিল। label একদম সঠিক পাওয়ার আরও কঠোর metric ব্যবহার করলে KSH-র network শতাংশ accuracy অর্জন করে।
KSH-র network সংক্ষেপে বর্ণনা করা মূল্যবান, কারণ এটা পরবর্তী অনেক কাজকে অনুপ্রাণিত করেছে। আমরা যেমন দেখব, এটা এই অধ্যায়ে আমাদের আগে train করা network-এর সাথেও ঘনিষ্ঠভাবে সম্পর্কিত, যদিও আরও বিস্তৃত। KSH দুটো GPU-তে train করা একটা deep convolutional neural network ব্যবহার করেছিলেন। তাঁরা দুটো GPU ব্যবহার করেছিলেন কারণ তাঁদের ব্যবহৃত নির্দিষ্ট ধরনের GPU-তে (একটা NVIDIA GeForce GTX 580) পুরো network রাখার মতো যথেষ্ট on-chip memory ছিল না। তাই তাঁরা network-কে দুই ভাগে ভাগ করে দুই GPU-তে বণ্টন করেছিলেন।
KSH network-এ টি hidden neuron-এর layer আছে। প্রথম টি hidden layer convolutional layer (কিছু max-pooling সহ), আর পরের টি layer fully-connected layer। Output layer একটা -unit softmax layer, যা টি image class-এর সাথে মিলে যায়। এই হলো network-এর একটা স্কেচ, KSH গবেষণাপত্র থেকে নেওয়া। বিস্তারিত নিচে ব্যাখ্যা করা হলো। লক্ষ করো অনেক layer ভাগে বিভক্ত, যা টি GPU-র সাথে মিলে যায়।
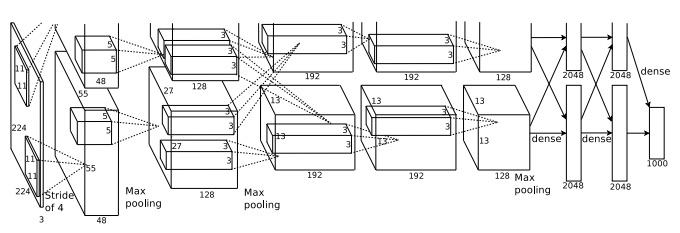
Input layer-এ টি neuron, যা একটা ছবির RGB মান প্রকাশ করে। মনে করো, আগে যেমন বলা হয়েছে, ImageNet-এ বিভিন্ন resolution-এর ছবি থাকে। এটা একটা সমস্যা তৈরি করে, কারণ neural network-এর input layer সাধারণত একটা নির্দিষ্ট আকারের হয়। KSH এটা সামলেছিলেন প্রতিটি ছবিকে এমনভাবে rescale করে যাতে ছোট দিকটির দৈর্ঘ্য হয়। তারপর তাঁরা rescale করা ছবির কেন্দ্রের একটা এলাকা crop করতেন। শেষে KSH ওই ছবি থেকে এলোমেলো subimage (ও তাদের অনুভূমিক প্রতিফলন) বের করতেন। তাঁরা এই এলোমেলো cropping training data সম্প্রসারণের একটা উপায় হিসেবে করতেন, এবং এভাবে overfitting কমাতেন। এটা KSH-র মতো একটা বড় network-এ বিশেষভাবে সহায়ক। এই ছবিগুলোই network-এর input হিসেবে ব্যবহৃত হতো। বেশিরভাগ ক্ষেত্রে crop করা ছবিতে এখনও crop-না-করা ছবির মূল বস্তুটি থাকে।
KSH-র network-এর hidden layer-গুলোয় যাই, প্রথম hidden layer একটা convolutional layer, একটা max-pooling ধাপ সহ। এটা আকারের local receptive field, এবং pixel-এর stride length ব্যবহার করে। মোট টি feature map। feature map-গুলো প্রতিটি টির দুই গ্রুপে বিভক্ত, প্রথম টি feature map এক GPU-তে, আর দ্বিতীয় টি অন্য GPU-তে। এই ও পরের layer-গুলোতে max-pooling অঞ্চলে করা হয়, কিন্তু pooling অঞ্চলগুলো একে অপরকে overlap করতে পারে, এবং কেবল pixel দূরে।
দ্বিতীয় hidden layer-ও একটা convolutional layer, একটা max-pooling ধাপ সহ। এটা local receptive field ব্যবহার করে, এবং মোট টি feature map, প্রতি GPU-তে টি ভাগে বিভক্ত। লক্ষ করো feature map-গুলো কেবল টি input channel ব্যবহার করে, আগের layer থেকে আসা পুরো output নয় (যেমনটা সাধারণত হতো)। কারণ যেকোনো একটা feature map কেবল একই GPU থেকে input ব্যবহার করে। এই অর্থে network আমরা অধ্যায়ের আগে বর্ণনা করা convolutional architecture থেকে কিছুটা সরে যায়, যদিও মূল ধারণা স্পষ্টতই একই।
তৃতীয়, চতুর্থ ও পঞ্চম hidden layer convolutional layer, কিন্তু আগের layer-গুলোর মতো নয়, এগুলোতে max-pooling নেই। এদের নিজ নিজ parameter: (৩) টি feature map, local receptive field ও টি input channel সহ; (৪) টি feature map, local receptive field ও টি input channel সহ; এবং (৫) টি feature map, local receptive field ও টি input channel সহ। লক্ষ করো তৃতীয় layer-এ কিছু inter-GPU communication জড়িত (figure-এ দেখানো) যাতে feature map-গুলো সব টি input channel ব্যবহার করে।
ষষ্ঠ ও সপ্তম hidden layer fully-connected layer, প্রতিটি layer-এ টি neuron সহ।
Output layer একটা -unit softmax layer।
KSH network অনেক কৌশলের সুবিধা নেয়। sigmoid বা tanh activation function ব্যবহারের বদলে KSH rectified linear unit ব্যবহার করেন, যা training উল্লেখযোগ্যভাবে দ্রুত করেছিল। KSH-র network-এ মোটামুটি 6 কোটি শেখা parameter ছিল, তাই বড় training set সত্ত্বেও এটা overfitting-এর প্রবণ ছিল। এটা কাটাতে তাঁরা উপরে আলোচিত এলোমেলো cropping কৌশল দিয়ে training set সম্প্রসারণ করেন। তাঁরা l2 regularization-এর একটা রূপ ও dropout ব্যবহার করেও overfitting আরও সামলান। Network-টা momentum-ভিত্তিক mini-batch stochastic gradient descent ব্যবহার করে train করা হয়েছিল।
এই হলো KSH গবেষণাপত্রের অনেক core ধারণার একটা সংক্ষিপ্ত পরিচয়। আমি কিছু বিস্তারিত বাদ দিয়েছি, যার জন্য তোমার গবেষণাপত্রটা দেখা উচিত। তুমি Alex Krizhevsky-র cuda-convnet (ও তার উত্তরসূরি) দেখতেও পারো, যাতে অনেক ধারণা বাস্তবায়নকারী code আছে। একটা Theano-ভিত্তিক বাস্তবায়নও তৈরি হয়েছে। সেই code এই অধ্যায়ে তৈরি code-এর অনুরূপ ধারায়, যদিও একাধিক GPU ব্যবহার ব্যাপারটা কিছুটা জটিল করে। Caffe neural net framework-এও KSH network-এর একটা সংস্করণ আছে, বিস্তারিত জানতে তাদের Model Zoo দেখো।
২০১৪-এর ILSVRC প্রতিযোগিতা: ২০১২ সাল থেকে দ্রুত অগ্রগতি চলছে। ২০১৪-এর ILSVRC প্রতিযোগিতার কথা ধরো। ২০১২-র মতোই এতে ছিল মিলিয়ন ছবির একটা training set, category-তে, এবং figure of merit ছিল top ভবিষ্যদ্বাণীতে সঠিক category থাকল কিনা। বিজয়ী দল, মূলত Google-ভিত্তিক, layer-এর neuron-যুক্ত একটা deep convolutional network ব্যবহার করেছিল। তাঁরা LeNet-5-এর প্রতি শ্রদ্ধা হিসেবে তাঁদের network-এর নাম দেন GoogLeNet। GoogLeNet একটা top-5 accuracy শতাংশ অর্জন করে, ২০১৩-এর বিজয়ীর (Clarifai, শতাংশ সহ) ও ২০১২-এর বিজয়ীর (KSH, শতাংশ সহ) উপর এক বিশাল উন্নতি।
GoogLeNet-এর শতাংশ accuracy ঠিক কতটা ভালো? ২০১৪ সালে একদল গবেষক ILSVRC প্রতিযোগিতা নিয়ে একটা survey গবেষণাপত্র লেখেন। তাঁরা যে প্রশ্নগুলো আলোচনা করেন তার একটা হলো ILSVRC-তে মানুষ কতটা ভালো করে। এটা করতে তাঁরা একটা system বানালেন যা মানুষকে ILSVRC ছবি classify করতে দেয়। একজন লেখক, Andrej Karpathy, একটা তথ্যপূর্ণ blog post-এ ব্যাখ্যা করেন যে মানুষকে GoogLeNet-এর কর্মক্ষমতায় পৌঁছাতে অনেক ঝামেলা পোহাতে হয়েছিল:
অন্যভাবে বললে, একজন expert মানুষ, পরিশ্রম করে, বহু চেষ্টায় কোনোমতে deep neural network-কে সামান্য হারাতে পারল। আসলে Karpathy রিপোর্ট করেন যে একটা ছোট নমুনায় train করা একজন দ্বিতীয় human expert কেবল একটা শতাংশ top-5 error rate অর্জন করতে পারলেন, GoogLeNet-এর কর্মক্ষমতার অনেক নিচে। প্রায় অর্ধেক ভুল হয়েছিল expert-এর "ground truth label-কে একটা option হিসেবে খুঁজে ও বিবেচনা করতে ব্যর্থ হওয়ার" কারণে।
এগুলো বিস্ময়কর ফল। আসলে এই কাজের পর থেকে কয়েকটি দল এমন system রিপোর্ট করেছে যাদের top-5 error rate আসলে 5.1%-এরও ভালো। এটা কখনো কখনো গণমাধ্যমে রিপোর্ট করা হয়েছে যে system-গুলোর মানুষের-চেয়ে-ভালো দৃষ্টি আছে। ফলগুলো সত্যিই উত্তেজনাপূর্ণ হলেও অনেক সতর্কতা আছে যা system-গুলোকে মানুষের-চেয়ে-ভালো দৃষ্টিসম্পন্ন ভাবাকে বিভ্রান্তিকর করে তোলে। ILSVRC চ্যালেঞ্জ নানা দিক থেকে একটা বেশ সীমিত সমস্যা — খোলা web-এর একটা crawl প্রয়োগে পাওয়া ছবির প্রতিনিধিত্বশীল নাও হতে পারে! আর অবশ্যই top- নিরিখ বেশ কৃত্রিম। আমরা এখনও image recognition বা আরও বিস্তৃতভাবে computer vision-এর সমস্যা সমাধান থেকে অনেক দূরে। তবু এত চ্যালেঞ্জিং একটা সমস্যায় মাত্র কয়েক বছরে এত অগ্রগতি দেখা অত্যন্ত উৎসাহজনক।
অন্যান্য কার্যকলাপ: আমি ImageNet-এর উপর জোর দিয়েছি, কিন্তু image recognition করতে neural net ব্যবহারে আরও অনেক কার্যকলাপ আছে। চলতি কিছু কাজের স্বাদ দিতে কয়েকটি কৌতূহলোদ্দীপক সাম্প্রতিক ফল সংক্ষেপে বর্ণনা করি।
একটা উৎসাহজনক ব্যবহারিক ফল-সেট আসে Google-এর একটা দল থেকে, যাঁরা Google-এর Street View imagery-তে street number চেনার সমস্যায় deep convolutional network প্রয়োগ করেন। তাঁদের গবেষণাপত্রে তাঁরা একজন human operator-এর সমান accuracy-তে প্রায় 10 কোটি street number শনাক্ত ও স্বয়ংক্রিয়ভাবে transcribe করার কথা জানান। System-টা দ্রুত: তাঁদের system এক ঘণ্টারও কম সময়ে France-এর সব Street View street-number ছবি transcribe করেছিল! তাঁরা বলেন: "এই নতুন dataset থাকায় বেশ কয়েকটি দেশে Google Maps-এর geocoding-এর মান উল্লেখযোগ্যভাবে বেড়েছে, বিশেষত যাদের আগে ভালো geocoding-এর অন্য উৎস ছিল না।" আর তাঁরা আরও বিস্তৃত দাবি করেন: "আমরা বিশ্বাস করি এই model দিয়ে আমরা অনেক প্রয়োগের জন্য ছোট [character] sequence-এর [optical character recognition] সমাধান করে ফেলেছি।"
হয়তো আমি এমন ধারণা দিয়েছি যে এটা সবই উৎসাহজনক ফলের কুচকাওয়াজ। অবশ্যই, সবচেয়ে কৌতূহলোদ্দীপক কিছু কাজ এমন মৌলিক বিষয় নিয়ে রিপোর্ট করে যা আমরা এখনও বুঝি না। যেমন একটা ২০১৩ গবেষণাপত্র দেখিয়েছিল deep network কার্যত blind spot-এ ভুগতে পারে। নিচের ছবিগুলোর সারি দেখো। বাঁদিকে একটা ImageNet ছবি যা তাঁদের network সঠিকভাবে classify করেছে। ডানদিকে একটা সামান্য বিকৃত ছবি (বিকৃতিটা মাঝখানে) যা network ভুলভাবে classify করে। লেখকেরা দেখলেন প্রতিটি নমুনা ছবির জন্যই এমন "adversarial" ছবি আছে, কেবল কয়েকটি বিশেষ ছবির জন্য নয়।

এটা একটা উদ্বেগজনক ফল। গবেষণাপত্রটি KSH-র network-এর মতোই code-এর উপর ভিত্তি করে একটা network ব্যবহার করেছিল — অর্থাৎ ঠিক সেই ধরনের network যা ক্রমশ বেশি ব্যবহৃত হচ্ছে। এমন neural network নীতিগতভাবে যেসব function হিসাব করে তা continuous হলেও, এ ধরনের ফল ইঙ্গিত দেয় বাস্তবে এরা প্রায় discontinuous function হিসাব করে। আরও খারাপ, এরা এমনভাবে discontinuous হবে যা যুক্তিযুক্ত আচরণ সম্পর্কে আমাদের স্বজ্ঞা লঙ্ঘন করে। এটা উদ্বেগের। তাছাড়া, discontinuity-র কারণ কী তা এখনও ভালোভাবে বোঝা যায়নি: এটা কি loss function-সংক্রান্ত কিছু? ব্যবহৃত activation function? network-এর architecture? অন্য কিছু? আমরা এখনও জানি না।
তবে এসব ফল যতটা খারাপ শোনায় ততটা নয়। যদিও এমন adversarial ছবি সাধারণ, বাস্তবে এরা অসম্ভাব্যও। গবেষণাপত্র যেমন উল্লেখ করে:
তবু এটা পীড়াদায়ক যে আমরা neural net এত কম বুঝি যে এ ধরনের ফল একটা সাম্প্রতিক আবিষ্কার হওয়া উচিত। অবশ্যই, এসব ফলের একটা বড় সুবিধা হলো এগুলো অনেক followup কাজে উদ্দীপনা জুগিয়েছে। যেমন একটা সাম্প্রতিক গবেষণাপত্র দেখায় যে একটা train করা network দিয়ে এমন ছবি তৈরি করা সম্ভব যা মানুষের কাছে white noise-এর মতো দেখায়, কিন্তু network খুব উচ্চ আত্মবিশ্বাসের সাথে একটা পরিচিত category-তে classify করে। এটা আরেকটা প্রমাণ যে neural network ও image recognition-এ এর ব্যবহার বুঝতে আমাদের অনেক পথ পাড়ি দিতে হবে।
এমন ফল সত্ত্বেও সামগ্রিক ছবিটা উৎসাহজনক। আমরা ImageNet-এর মতো অত্যন্ত কঠিন benchmark-এ দ্রুত অগ্রগতি দেখছি। StreetView-তে street number চেনার মতো বাস্তব সমস্যার সমাধানেও দ্রুত অগ্রগতি দেখছি। কিন্তু এটা উৎসাহজনক হলেও কেবল benchmark-এ, এমনকি বাস্তব প্রয়োগেও উন্নতি দেখাই যথেষ্ট নয়। এমন মৌলিক ঘটনা আছে যা আমরা এখনও খারাপভাবে বুঝি, যেমন adversarial ছবির অস্তিত্ব। এমন মৌলিক সমস্যা যখন এখনও আবিষ্কৃত হচ্ছে (সমাধানের কথা তো বাদই), তখন বলা অকালপক্ব যে আমরা image recognition-এর সমস্যা সমাধানের কাছাকাছি। একই সাথে এমন সমস্যা আরও কাজের একটা উত্তেজনাপূর্ণ উদ্দীপক।
Deep net-এর অন্যান্য approach
এই বই জুড়ে আমরা একটাই সমস্যায় মনোযোগ দিয়েছি: MNIST সংখ্যা classify করা। এটা একটা রসালো সমস্যা যা আমাদের অনেক শক্তিশালী ধারণা বুঝতে বাধ্য করেছে: stochastic gradient descent, backpropagation, convolutional net, regularization, ইত্যাদি। কিন্তু এটা একটা সংকীর্ণ সমস্যাও। Neural network-এর সাহিত্য পড়লে তুমি এমন অনেক ধারণার মুখোমুখি হবে যা আমরা আলোচনা করিনি: recurrent neural network, Boltzmann machine, generative model, transfer learning, reinforcement learning, ইত্যাদি, আরও কত কী আর কত কী! Neural network একটা বিশাল ক্ষেত্র। তবে অনেক গুরুত্বপূর্ণ ধারণা আমরা ইতিমধ্যে আলোচনা করা ধারণারই রূপভেদ, এবং একটু চেষ্টায় বোঝা যায়। এই অংশে আমি এসব এখনো-অদেখা দৃশ্যপটের একটা ঝলক দিই। আলোচনা বিস্তারিত নয়, ব্যাপকও নয় — তাতে বই অনেক বড় হয়ে যেত। বরং এটা ভাবধর্মী, ক্ষেত্রটির ধারণাগত সমৃদ্ধি জাগিয়ে তোলার এবং সেই সম্পদের কিছুকে আমরা যা দেখেছি তার সাথে সম্পর্কিত করার একটা চেষ্টা। অংশজুড়ে আমি আরও জানার প্রবেশদ্বার হিসেবে কয়েকটি link দেব। অবশ্যই এসব link-এর অনেকগুলো শীঘ্রই পুরোনো হয়ে যাবে, এবং তুমি হয়তো আরও সাম্প্রতিক সাহিত্য খুঁজতে চাইবে। তা সত্ত্বেও আমি আশা করি অন্তর্নিহিত ধারণাগুলোর অনেকগুলো স্থায়ী আগ্রহের হবে।
Recurrent neural network (RNN): আমরা এতক্ষণ যে feedforward net ব্যবহার করছিলাম তাতে একটা single input পুরোপুরি বাকি layer-গুলোর সব neuron-এর activation নির্ধারণ করে। এটা খুব static একটা ছবি: network-এর সবকিছু স্থির, একটা জমাট, স্ফটিকসুলভ গুণসম্পন্ন। কিন্তু ধরো আমরা network-এর উপাদানগুলোকে গতিশীলভাবে বদলাতে দিই। যেমন hidden neuron-এর আচরণ কেবল আগের hidden layer-এর activation দিয়ে নয়, আগের সময়ের activation দিয়েও নির্ধারিত হতে পারে। আসলে একটা neuron-এর activation আংশিকভাবে তার নিজের আগের সময়ের activation দিয়েও নির্ধারিত হতে পারে। feedforward network-এ অবশ্যই এমন ঘটে না। কিংবা হয়তো hidden ও output neuron-এর activation কেবল network-এর বর্তমান input দিয়ে নয়, আগের input দিয়েও নির্ধারিত হবে।
এমন time-varying আচরণসম্পন্ন neural network-কে recurrent neural network বা RNN বলা হয়। গত অনুচ্ছেদে দেওয়া recurrent net-এর অনানুষ্ঠানিক বর্ণনাকে গাণিতিকভাবে আনুষ্ঠানিক করার অনেক ভিন্ন উপায় আছে। RNN-এর Wikipedia article-এ চোখ বুলিয়ে এসব গাণিতিক model-এর কিছুর স্বাদ পেতে পারো। আমি লেখার সময় ওই page-এ অন্তত 13টি ভিন্ন model তালিকাবদ্ধ ছিল। কিন্তু গাণিতিক বিস্তারিত বাদ দিলে, বিস্তৃত ধারণাটা হলো RNN এমন neural network যেখানে সময়ের সাথে গতিশীল পরিবর্তনের একটা ধারণা আছে। আর অবাক করার মতো নয় যে এরা সময়ের সাথে বদলে যাওয়া data বা process বিশ্লেষণে বিশেষভাবে উপযোগী। যেমন speech বা natural language-এর মতো সমস্যায় এমন data ও process স্বাভাবিকভাবেই দেখা দেয়।
RNN বর্তমানে যেভাবে ব্যবহৃত হচ্ছে তার একটা হলো neural network-কে algorithm নিয়ে চিন্তা করার প্রচলিত উপায়ের সাথে আরও ঘনিষ্ঠভাবে যুক্ত করা — Turing machine ও (প্রচলিত) programming language-এর মতো ধারণার ভিত্তিতে চিন্তা। একটা ২০১৪ গবেষণাপত্র একটা RNN গড়ে তোলে যা একটা (খুব, খুব সরল!) Python program-এর character-by-character বর্ণনাকে input হিসেবে নিতে পারত, এবং সেই বর্ণনা ব্যবহার করে output ভবিষ্যদ্বাণী করত। অনানুষ্ঠানিকভাবে, network কিছু Python program "বুঝতে" শিখছে। ২০১৪-এরই আরেকটা গবেষণাপত্র RNN-কে শুরুর বিন্দু হিসেবে নিয়ে যাকে তাঁরা বলেন neural Turing machine (NTM), তা গড়ে তোলে। এটা একটা সর্বজনীন computer যার পুরো কাঠামো gradient descent ব্যবহার করে train করা যায়। তাঁরা তাঁদের NTM-কে sort ও copy করার মতো কয়েকটি সরল সমস্যার জন্য algorithm অনুমান করতে train করেন।
এ অবস্থায় এগুলো অত্যন্ত সরল toy model। Python program print(398345+42598) চালাতে শেখা একটা network-কে একটা পূর্ণাঙ্গ Python interpreter বানায় না! এই ধারণাগুলো আর কতদূর ঠেলা যাবে তা স্পষ্ট নয়। তবু ফলগুলো কৌতূহলোদ্দীপক। ঐতিহাসিকভাবে, যেসব pattern recognition সমস্যায় প্রচলিত algorithmic পদ্ধতির অসুবিধা হয়, সেখানে neural network ভালো করেছে। উল্টোভাবে, neural net যেসব সমস্যায় তত ভালো নয়, প্রচলিত algorithmic পদ্ধতি সেগুলো ভালো সমাধান করে। আজ কেউ neural network দিয়ে web server বা database program বানায় না! neural network ও algorithm নিয়ে আরও প্রচলিত পদ্ধতি — উভয়ের শক্তি সমন্বিত করে এমন একীভূত model গড়া দারুণ হবে। RNN ও RNN-অনুপ্রাণিত ধারণা আমাদের তা করতে সাহায্য করতে পারে।
RNN সাম্প্রতিক বছরগুলোতে আরও অনেক সমস্যা সমাধানে ব্যবহৃত হয়েছে। এরা speech recognition-এ বিশেষভাবে উপযোগী হয়েছে। RNN-ভিত্তিক পদ্ধতি, যেমন, phoneme recognition-এর accuracy-তে record গড়েছে। এরা মানুষ কথা বলার সময় যে ভাষা ব্যবহার করে তার উন্নত model গড়তেও ব্যবহৃত হয়েছে। ভালো language model এমন উচ্চারণ স্পষ্ট করতে সাহায্য করে যা শুনতে একই রকম। যেমন একটা ভালো language model আমাদের বলবে "to infinity and beyond" "two infinity and beyond"-এর চেয়ে অনেক বেশি সম্ভাব্য, যদিও দুটো বাক্যাংশ শুনতে অভিন্ন। RNN কিছু language benchmark-এ নতুন record গড়তে ব্যবহৃত হয়েছে।
প্রসঙ্গত, এই কাজ speech recognition-এ কেবল RNN নয়, সব ধরনের deep neural net-এর একটা বিস্তৃত ব্যবহারের অংশ। যেমন deep net-ভিত্তিক একটা পদ্ধতি large vocabulary continuous speech recognition-এ অসাধারণ ফল অর্জন করেছে। আর deep net-ভিত্তিক আরেকটা system Google-এর Android operating system-এ মোতায়েন করা হয়েছে।
আমি RNN কী করতে পারে তা নিয়ে একটু বললাম, কিন্তু এরা কীভাবে কাজ করে তা নিয়ে তেমন নয়। তোমার হয়তো অবাক লাগবে না জানতে যে feedforward network-এ ব্যবহৃত অনেক ধারণা RNN-এও ব্যবহার করা যায়। বিশেষত, gradient descent ও backpropagation-এ সরল কিছু পরিবর্তন করে আমরা RNN train করতে পারি। feedforward net-এ ব্যবহৃত আরও অনেক ধারণা — regularization কৌশল থেকে convolution, ব্যবহৃত activation ও cost function পর্যন্ত — recurrent net-এও উপযোগী। তাই বইয়ে আমরা যেসব কৌশল গড়েছি তার অনেকগুলো RNN-এর সাথে ব্যবহারের জন্য মানিয়ে নেওয়া যায়।
Long short-term memory unit (LSTM): RNN-কে প্রভাবিত করা একটা চ্যালেঞ্জ হলো আদি model-গুলো train করা খুব কঠিন হয়ে দাঁড়িয়েছিল, deep feedforward network-এর চেয়েও কঠিন। কারণ অধ্যায় ৫-এ আলোচিত unstable gradient problem। মনে করো এই সমস্যার সাধারণ প্রকাশ হলো gradient layer-এর মধ্য দিয়ে পিছিয়ে যেতে যেতে ছোট থেকে ছোট হতে থাকে। এটা আগের layer-গুলোতে শেখা অত্যন্ত ধীর করে দেয়। RNN-এ সমস্যা আসলে আরও খারাপ হয়, কারণ gradient কেবল layer-এর মধ্য দিয়ে পিছিয়ে যায় না, সময়ের মধ্য দিয়েও পিছিয়ে যায়। Network দীর্ঘ সময় চললে তা gradient-কে অত্যন্ত অস্থির ও তা থেকে শেখা কঠিন করে দিতে পারে। সৌভাগ্যবশত, RNN-এ long short-term memory unit (LSTM) নামে একটা ধারণা যুক্ত করা সম্ভব। ১৯৯৭ সালে Hochreiter ও Schmidhuber এই unit-গুলো পরিচয় করান, স্পষ্টভাবে unstable gradient problem সামলানোর উদ্দেশ্যে। LSTM RNN train করার সময় ভালো ফল পাওয়া অনেক সহজ করে, এবং অনেক সাম্প্রতিক গবেষণাপত্র (উপরে link করা অনেকগুলো সহ) LSTM বা সম্পর্কিত ধারণা ব্যবহার করে।
Deep belief net, generative model ও Boltzmann machine: Deep learning-এ আধুনিক আগ্রহ শুরু হয় ২০০৬ সালে, এমন কিছু গবেষণাপত্র দিয়ে যেগুলো ব্যাখ্যা করে কীভাবে একটা deep belief network (DBN) নামে এক ধরনের neural network train করা যায়। DBN কয়েক বছর প্রভাবশালী ছিল, কিন্তু পরে জনপ্রিয়তা হারিয়েছে, যখন feedforward network ও recurrent neural net-এর মতো model চলতি হয়ে উঠেছে। এ সত্ত্বেও DBN-এর কয়েকটি বৈশিষ্ট্য একে কৌতূহলোদ্দীপক করে তোলে।
DBN কৌতূহলোদ্দীপক হওয়ার একটা কারণ হলো এরা generative model নামে যা পরিচিত তার একটা উদাহরণ। একটা feedforward network-এ আমরা input activation নির্দিষ্ট করি, এবং সেগুলো network-এর পরের feature neuron-এর activation নির্ধারণ করে। DBN-এর মতো একটা generative model একইভাবে ব্যবহার করা যায়, কিন্তু কিছু feature neuron-এর মান নির্দিষ্ট করে "network-কে উল্টোদিকে চালানো"-ও সম্ভব, input activation-এর মান তৈরি করে। আরও concrete-ভাবে, হাতে লেখা সংখ্যার ছবিতে train করা একটা DBN (সম্ভাব্যভাবে ও কিছু যত্নে) এমন ছবিও তৈরি করতে পারে যা হাতে লেখা সংখ্যার মতো দেখায়। অন্যভাবে বললে, DBN কোনো অর্থে লিখতে শিখবে। এতে একটা generative model অনেকটা মানুষের মস্তিষ্কের মতো: এটা কেবল সংখ্যা পড়তে পারে না, লিখতেও পারে। Geoffrey Hinton-এর স্মরণীয় বাক্যে, "আকৃতি চিনতে হলে আগে ছবি তৈরি করতে শেখো।"
DBN কৌতূহলোদ্দীপক হওয়ার একটা দ্বিতীয় কারণ হলো এরা unsupervised ও semi-supervised learning করতে পারে। যেমন image data দিয়ে train করলে DBN অন্য ছবি বোঝার জন্য উপযোগী feature শিখতে পারে, এমনকি training ছবিগুলো unlabelled হলেও। আর unsupervised learning করার সক্ষমতা মৌলিক বৈজ্ঞানিক কারণে — এবং যথেষ্ট ভালো কাজ করানো গেলে ব্যবহারিক প্রয়োগের জন্যও — অত্যন্ত কৌতূহলোদ্দীপক।
এসব আকর্ষণীয় বৈশিষ্ট্য সত্ত্বেও DBN deep learning-এর model হিসেবে কেন জনপ্রিয়তা হারিয়েছে? কারণের একটা অংশ হলো feedforward ও recurrent net-এর মতো model অনেক চমকপ্রদ ফল অর্জন করেছে, যেমন image ও speech recognition benchmark-এ তাদের breakthrough। এসব model-এ এখন অনেক মনোযোগ দেওয়া অবাক করার মতো নয় এবং বেশ যথাযথ। তবে একটা দুর্ভাগ্যজনক উপসিদ্ধান্ত আছে। ধারণার বাজার প্রায়ই winner-take-all ধাঁচে কাজ করে, যেকোনো ক্ষেত্রে প্রায় সব মনোযোগ মুহূর্তের চলতি জিনিসে চলে যায়। মানুষের পক্ষে মুহূর্তের অ-চলতি ধারণা নিয়ে কাজ করা অত্যন্ত কঠিন হয়ে দাঁড়াতে পারে, এমনকি সেই ধারণা স্পষ্টতই দীর্ঘমেয়াদি আগ্রহের হলেও। আমার ব্যক্তিগত মত হলো DBN ও অন্যান্য generative model বর্তমানে যতটা মনোযোগ পাচ্ছে তার চেয়ে বেশি প্রাপ্য। আর DBN বা সম্পর্কিত কোনো model একদিন বর্তমান চলতি model-গুলোকে ছাড়িয়ে গেলে আমি অবাক হব না।
অন্যান্য ধারণা: Neural network ও deep learning-এ আর কী ঘটছে? বেশ, আরও বিপুল পরিমাণ আকর্ষণীয় কাজ চলছে। সক্রিয় গবেষণা-ক্ষেত্রের মধ্যে আছে natural language processing, machine translation, এবং হয়তো আরও বিস্ময়কর প্রয়োগ যেমন music informatics করতে neural network ব্যবহার। অবশ্যই আরও অনেক ক্ষেত্রও আছে। অনেক ক্ষেত্রে এই বই পড়ার পর তুমি সাম্প্রতিক কাজ অনুসরণ করতে শুরু করতে পারবে, যদিও (অবশ্যই) ধরে-নেওয়া পটভূমি জ্ঞানের ফাঁক পূরণ করতে হবে।
একটা বিশেষভাবে মজার গবেষণাপত্র উল্লেখ করে এই অংশ শেষ করি। এটা deep convolutional network-কে reinforcement learning নামে পরিচিত একটা কৌশলের সাথে মিলিয়ে video game ভালোভাবে খেলতে শেখে। ধারণাটা হলো game screen-এর pixel data সরল করতে convolutional network ব্যবহার করা, তাকে একটা সরলতর feature-সেটে পরিণত করা, যা দিয়ে কোন action নিতে হবে তা ঠিক করা যায়: "বাঁয়ে যাও", "নিচে যাও", "fire", ইত্যাদি। বিশেষভাবে কৌতূহলোদ্দীপক যা তা হলো একটা single network সাতটি ভিন্ন classic video game বেশ ভালোভাবে খেলতে শিখল, তিনটিতে human expert-দের ছাড়িয়ে গেল। এখন এ সবই একটা stunt-এর মতো শোনায়, এবং নিঃসন্দেহে গবেষণাপত্রটি ভালোভাবে বাজারজাত হয়েছিল, "Playing Atari with reinforcement learning" শিরোনামে। কিন্তু উপরিতলের ঝকঝকে ভাব ছাড়িয়ে ভাবো, এই system raw pixel data নিচ্ছে — এটা game-এর নিয়মও জানে না! — এবং সেই data থেকে কয়েকটি খুব ভিন্ন ও খুব adversarial পরিবেশে, প্রতিটির নিজস্ব জটিল নিয়মের সেট সহ, উচ্চমানের সিদ্ধান্তগ্রহণ করতে শিখছে। এটা বেশ চমৎকার।
Neural network-এর ভবিষ্যৎ নিয়ে
Intention-driven user interface: একটা পুরোনো রসিকতা আছে যেখানে এক অধৈর্য অধ্যাপক বিভ্রান্ত ছাত্রকে বলেন: "আমি যা বলি তা শোনো না; আমি যা বোঝাতে চাই তা শোনো।" ঐতিহাসিকভাবে computer প্রায়ই, ওই বিভ্রান্ত ছাত্রের মতো, ব্যবহারকারী কী বোঝাতে চান সে ব্যাপারে অন্ধকারে থেকেছে। কিন্তু এটা বদলাচ্ছে। আমার এখনও মনে আছে প্রথমবার যখন একটা Google search query ভুল বানানে লিখলাম, আর Google বলল "তুমি কি [সংশোধিত query] বোঝাতে চেয়েছিলে?" এবং সংশ্লিষ্ট search ফল দিল — তখনকার বিস্ময়। Google CEO Larry Page একবার নিখুঁত search engine-কে বর্ণনা করেছিলেন এমন কিছু হিসেবে যা ঠিক বোঝে [তোমার query] কী বোঝায় এবং তোমাকে ঠিক তা-ই ফিরিয়ে দেয় যা তুমি চাও।
এটা একটা intention-driven user interface-এর দৃষ্টিভঙ্গি। এই দৃষ্টিভঙ্গিতে ব্যবহারকারীর আক্ষরিক query-র সাড়া দেওয়ার বদলে search machine learning ব্যবহার করে অস্পষ্ট user input নেবে, ঠিক কী বোঝানো হয়েছে তা নির্ণয় করবে, এবং সেই অন্তর্দৃষ্টির ভিত্তিতে action নেবে।
Intention-driven interface-এর ধারণা search-এর চেয়ে অনেক বিস্তৃতভাবে প্রয়োগ করা যায়। আগামী কয়েক দশকে হাজার হাজার কোম্পানি এমন product বানাবে যা machine learning ব্যবহার করে এমন user interface তৈরি করে যা অসূক্ষ্মতা সহ্য করতে পারে, একই সাথে ব্যবহারকারীর প্রকৃত অভিপ্রায় নির্ণয় ও তার ভিত্তিতে action নিতে পারে। আমরা এখনই এমন intention-driven interface-এর আদি উদাহরণ দেখছি: Apple-এর Siri; Wolfram Alpha; IBM-এর Watson; ছবি ও video annotate করতে পারে এমন system; এবং আরও অনেক কিছু।
এসব product-এর বেশিরভাগই ব্যর্থ হবে। অনুপ্রাণিত user interface design কঠিন, এবং আমি আশা করি অনেক কোম্পানি শক্তিশালী machine learning প্রযুক্তি নিয়ে তা দিয়ে নিরস user interface বানাবে। তোমার user interface ধারণা বাজে হলে পৃথিবীর সেরা machine learning-ও সাহায্য করবে না। কিন্তু সফল হবে এমন product-ও কিছু অবশিষ্ট থাকবে। সময়ের সাথে তা computer-এর সাথে আমাদের সম্পর্কে একটা গভীর পরিবর্তন আনবে। খুব বেশিদিন আগে নয় — ধরো ২০০৫ — ব্যবহারকারীরা ধরে নিতেন computer-এর সাথে বেশিরভাগ মিথস্ক্রিয়ায় তাঁদের নিখুঁততা দরকার। আসলে computer literacy অনেকাংশে মানে ছিল এই ধারণা আত্মস্থ করা যে computer অত্যন্ত আক্ষরিক; একটা ভুল জায়গায় বসানো semicolon computer-এর সাথে মিথস্ক্রিয়ার ধরন পুরোপুরি বদলে দিতে পারে। কিন্তু আগামী কয়েক দশকে আমি আশা করি আমরা অনেক সফল intention-driven user interface গড়ব, এবং তা computer-এর সাথে মিথস্ক্রিয়ার সময় আমাদের প্রত্যাশা নাটকীয়ভাবে বদলে দেবে।
Machine learning, data science ও উদ্ভাবনের সদগুণ চক্র: অবশ্যই, machine learning কেবল intention-driven interface বানাতে ব্যবহৃত হচ্ছে না। আরেকটা উল্লেখযোগ্য প্রয়োগ data science-এ, যেখানে machine learning ব্যবহার করে data-তে লুকানো "known unknown" খুঁজে বের করা হয়। এটা ইতিমধ্যে একটা চলতি ক্ষেত্র, এবং এ নিয়ে অনেক লেখা হয়েছে, তাই বেশি বলব না। তবে এই চলতি ভাবের একটা পরিণতি উল্লেখ করতে চাই যা তত বেশি আলোচিত হয় না: দীর্ঘমেয়াদে machine learning-এ সবচেয়ে বড় breakthrough হয়তো কোনো একক ধারণাগত breakthrough হবে না। বরং সবচেয়ে বড় breakthrough হবে এই যে machine learning গবেষণা data science ও অন্যান্য ক্ষেত্রে প্রয়োগের মাধ্যমে লাভজনক হয়ে উঠবে। একটা কোম্পানি যদি machine learning গবেষণায় 1 ডলার বিনিয়োগ করে যুক্তিসঙ্গত দ্রুততায় 1 ডলার 10 সেন্ট ফেরত পায়, তবে প্রচুর অর্থ machine learning গবেষণায় ঢুকবে। অন্যভাবে বললে, machine learning প্রযুক্তিতে কয়েকটি বড় নতুন বাজার ও বৃদ্ধির ক্ষেত্র সৃষ্টির একটা ইঞ্জিন। ফলাফল হবে গভীর বিষয়-দক্ষতাসম্পন্ন ও অসাধারণ সম্পদে access থাকা মানুষের বড় বড় দল। তা machine learning-কে আরও এগিয়ে নেবে, আরও বাজার ও সুযোগ সৃষ্টি করবে — উদ্ভাবনের একটা সদগুণ চক্র।
Neural network ও deep learning-এর ভূমিকা: আমি প্রযুক্তির নতুন সুযোগ সৃষ্টিকারী হিসেবে machine learning নিয়ে বিস্তৃতভাবে কথা বলছিলাম। এ সবে neural network ও deep learning-এর সুনির্দিষ্ট ভূমিকা কী হবে?
প্রশ্নের উত্তর দিতে ইতিহাসের দিকে তাকানো সাহায্য করে। ১৯৮০-এর দশকে neural network নিয়ে প্রচুর উত্তেজনা ও আশাবাদ ছিল, বিশেষত backpropagation ব্যাপকভাবে পরিচিত হওয়ার পর। সেই উত্তেজনা মিলিয়ে যায়, আর ১৯৯০-এর দশকে machine learning-এর ব্যাটন support vector machine-এর মতো অন্য কৌশলে চলে যায়। আজ neural network আবার উঁচুতে উঠছে, নানা record গড়ছে, অনেক সমস্যায় সবাইকে হারাচ্ছে। কিন্তু কে বলবে আগামীকাল কোনো নতুন approach গড়ে উঠে neural network-কে আবার সরিয়ে দেবে না? কিংবা হয়তো neural network-এর অগ্রগতি থমকে যাবে, এবং তাৎক্ষণিকভাবে তাদের জায়গা নিতে কিছু আসবে না?
এই কারণে neural network-এর চেয়ে machine learning-এর ভবিষ্যৎ নিয়ে বিস্তৃতভাবে ভাবা অনেক সহজ। সমস্যার একটা অংশ হলো আমরা neural network এত কম বুঝি। কেন neural network এত ভালো generalize করতে পারে? এত বিপুলসংখ্যক parameter শেখা সত্ত্বেও কীভাবে এরা এত ভালোভাবে overfitting এড়ায়? কেন stochastic gradient descent এত ভালো কাজ করে? Data set বড় হলে neural network কত ভালো করবে? যেমন ImageNet গুণ বড় হলে neural network-এর কর্মক্ষমতা অন্য machine learning কৌশলের চেয়ে বেশি না কম উন্নত হবে? এসব সরল, মৌলিক প্রশ্ন। আর এখন আমরা এসব প্রশ্নের উত্তর খুব খারাপভাবে বুঝি। যতদিন তা থাকবে, machine learning-এর ভবিষ্যতে neural network কী ভূমিকা রাখবে তা বলা কঠিন।
আমি একটা ভবিষ্যদ্বাণী করব: আমি বিশ্বাস করি deep learning থেকে যাবে। ধারণার শ্রেণিবিন্যাস শেখার সক্ষমতা, একাধিক স্তরের abstraction গড়ে তোলা, পৃথিবীকে বোঝার জন্য মৌলিক বলে মনে হয়। এর মানে এই নয় যে আগামীকালের deep learner আজকের চেয়ে আমূল ভিন্ন হবে না। ব্যবহৃত উপাদান unit-এ, architecture-এ, বা learning algorithm-এ বড় পরিবর্তন আমরা দেখতে পারি। সেই পরিবর্তন এতটাই নাটকীয় হতে পারে যে আমরা আর ফলাফল system-গুলোকে neural network ভাবব না। কিন্তু তারা তবু deep learning করছে।
Neural network ও deep learning কি শীঘ্রই artificial intelligence-এ নিয়ে যাবে? এই বইয়ে আমরা সুনির্দিষ্ট কাজ — যেমন ছবি classify করা — করতে neural net ব্যবহারে মনোযোগ দিয়েছি। চলো আমাদের উচ্চাকাঙ্ক্ষা বিস্তৃত করি, এবং জিজ্ঞাসা করি: সাধারণ-উদ্দেশ্যের চিন্তাশীল computer-এর ব্যাপারটা কী? Neural network ও deep learning কি আমাদের (সাধারণ) artificial intelligence (AI)-এর সমস্যা সমাধানে সাহায্য করতে পারে? আর যদি পারে, deep learning-এর সাম্প্রতিক দ্রুত অগ্রগতির কথা ভেবে, আমরা কি শীঘ্রই সাধারণ AI আশা করতে পারি?
এসব প্রশ্নের ব্যাপক উত্তর দিতে একটা আলাদা বই লাগবে। বরং আমি একটা পর্যবেক্ষণ তুলে ধরি। এটা Conway's law নামে পরিচিত একটা ধারণার ভিত্তিতে:
যেমন, Conway's law ইঙ্গিত দেয় যে একটা Boeing 747 বিমানের নকশা 747 নকশা করার সময় Boeing ও তার ঠিকাদারদের বিস্তৃত organizational কাঠামোর প্রতিফলন ঘটাবে। কিংবা একটা সরল, সুনির্দিষ্ট উদাহরণ ধরো — একটা কোম্পানি একটা জটিল software application বানাচ্ছে। Application-এর dashboard যদি কোনো machine learning algorithm-এর সাথে integrate করা উচিত হয়, তবে dashboard বানানো ব্যক্তির কোম্পানির machine learning expert-এর সাথে কথা বলা ভালো। Conway's law নিছক সেই পর্যবেক্ষণটা, বড় পরিসরে।
Conway's law প্রথম শুনে অনেকে হয় বলেন "এটা কি বাজে আর সুস্পষ্ট কথা নয়?" নয়তো "এটা কি ভুল নয়?" ভুল হওয়ার আপত্তি দিয়ে শুরু করি। এই আপত্তির একটা উদাহরণ হিসেবে প্রশ্ন ধরো: Boeing-এর accounting department 747-এর নকশায় কোথায় দেখা যায়? তাদের janitorial department? তাদের internal catering? উত্তর হলো organization-এর এসব অংশ সম্ভবত 747-এ স্পষ্টভাবে কোথাও দেখা যায় না। তাই আমাদের Conway's law-কে কেবল organization-এর সেইসব অংশের প্রতি ইঙ্গিত হিসেবে বোঝা উচিত যারা স্পষ্টভাবে design ও engineering নিয়ে যুক্ত।
আর অন্য আপত্তি, যে Conway's law বাজে আর সুস্পষ্ট? এটা হয়তো সত্যি, কিন্তু আমি তা মনে করি না, কারণ organization প্রায়ই Conway's law উপেক্ষা করে কাজ করে। নতুন product বানানো দল প্রায়ই legacy নিয়োগে ফুলে থাকে, বা উল্টোভাবে কোনো গুরুত্বপূর্ণ দক্ষতাসম্পন্ন ব্যক্তির অভাবে ভোগে। সেই সব product-এর কথা ভাবো যাদের অকেজো জটিলকারী feature আছে। বা সেই সব product যাদের সুস্পষ্ট বড় ঘাটতি আছে — যেমন একটা ভয়ানক user interface। উভয় শ্রেণির সমস্যাই প্রায়ই ঘটে একটা ভালো product বানাতে যে দল দরকার ছিল আর আসলে যে দল জড়ো করা হয়েছিল তার মধ্যে অমিলের কারণে। Conway's law সুস্পষ্ট হতে পারে, কিন্তু তার মানে এই নয় যে মানুষ নিয়মিত একে উপেক্ষা করে না।
Conway's law এমন system-এর design ও engineering-এ প্রযোজ্য যেখানে আমরা সম্ভাব্য উপাদান অংশ ও কীভাবে সেগুলো বানাতে হয় তার বেশ ভালো বোঝাপড়া নিয়ে শুরু করি। এটা সরাসরি artificial intelligence-এর বিকাশে প্রয়োগ করা যায় না, কারণ AI (এখনও) তেমন সমস্যা নয়: আমরা জানি না উপাদান অংশগুলো কী। আসলে আমরা নিশ্চিতও নই কোন মৌলিক প্রশ্নগুলো জিজ্ঞাসা করতে হবে। অন্যভাবে বললে, এ মুহূর্তে AI engineering-এর চেয়ে বেশি বিজ্ঞানের সমস্যা। জেট ইঞ্জিন বা aerodynamics-এর নীতি না জেনে 747-এর নকশা শুরু করার কল্পনা করো। তুমি জানতে না তোমার organization-এ কী ধরনের expert নিয়োগ করতে হবে। Wernher von Braun যেমন বলেছিলেন, "basic research হলো আমি যখন জানি না আমি কী করছি তখন যা করি"। Engineering-এর চেয়ে বেশি বিজ্ঞান এমন সমস্যায় প্রযোজ্য Conway's law-এর কোনো সংস্করণ কি আছে?
এই প্রশ্নের অন্তর্দৃষ্টি পেতে চিকিৎসাবিদ্যার ইতিহাস ধরো। আদিকালে চিকিৎসা ছিল Galen ও Hippocrates-এর মতো চিকিৎসকদের ক্ষেত্র, যাঁরা পুরো শরীর অধ্যয়ন করতেন। কিন্তু আমাদের জ্ঞান বাড়ার সাথে সাথে মানুষ বিশেষায়িত হতে বাধ্য হলো। আমরা অনেক গভীর নতুন ধারণা আবিষ্কার করলাম: যেমন রোগের জীবাণু-তত্ত্ব, বা antibody কীভাবে কাজ করে তার বোঝাপড়া, বা এই বোঝাপড়া যে হৃদয়, ফুসফুস, শিরা ও ধমনী মিলে একটা সম্পূর্ণ cardiovascular system গঠন করে। এমন গভীর অন্তর্দৃষ্টি epidemiology, immunology, এবং cardiovascular system ঘিরে আন্তঃসংযুক্ত ক্ষেত্রগুলোর মতো উপ-ক্ষেত্রের ভিত্তি গড়ল। তাই আমাদের জ্ঞানের কাঠামো চিকিৎসার সামাজিক কাঠামো গড়ে তুলেছে। এটা immunology-র ক্ষেত্রে বিশেষভাবে চমকপ্রদ: immune system যে আছে এবং তা অধ্যয়নযোগ্য একটা system, এটা উপলব্ধি করা একটা অত্যন্ত গুরুত্বপূর্ণ অন্তর্দৃষ্টি। তাই আমাদের একটা পুরো চিকিৎসা-ক্ষেত্র আছে — বিশেষজ্ঞ, conference, এমনকি পুরস্কার ইত্যাদি সহ — যা এমন কিছু ঘিরে সংগঠিত যা কেবল অদৃশ্যই নয়, যুক্তিসঙ্গতভাবে একটা স্বতন্ত্র জিনিসও নয়।
এটা একটা প্রচলিত pattern যা অনেক সুপ্রতিষ্ঠিত বিজ্ঞানে বারবার পুনরাবৃত্ত হয়েছে: কেবল চিকিৎসা নয়, পদার্থবিজ্ঞান, গণিত, রসায়ন ও অন্যান্যও। ক্ষেত্রগুলো শুরু হয় একশিলা হিসেবে, কেবল কয়েকটি গভীর ধারণা নিয়ে। আদি বিশেষজ্ঞরা সব ধারণা আয়ত্ত করতে পারতেন। কিন্তু সময়ের সাথে সেই একশিলা চরিত্র বদলায়। আমরা অনেক গভীর নতুন ধারণা আবিষ্কার করি, একজন মানুষের সত্যিই আয়ত্ত করার মতো অনেক বেশি। ফলে ক্ষেত্রটির সামাজিক কাঠামো সেই ধারণাগুলো ঘিরে পুনর্গঠিত ও বিভক্ত হয়। একশিলার বদলে আমরা পাই ক্ষেত্রের ভেতরে ক্ষেত্রের ভেতরে ক্ষেত্র, একটা জটিল, recursive, স্ব-উল্লেখী সামাজিক কাঠামো, যার সংগঠন আমাদের গভীরতম অন্তর্দৃষ্টির মধ্যকার সংযোগের প্রতিফলন। তাই আমাদের জ্ঞানের কাঠামো বিজ্ঞানের সামাজিক সংগঠন গড়ে তোলে। কিন্তু সেই সামাজিক রূপ আবার আমরা কী আবিষ্কার করতে পারি তা সীমিত ও নির্ধারণ করতে সাহায্য করে। এটা Conway's law-এর বৈজ্ঞানিক সমতুল্য।
তাহলে এর সাথে deep learning বা AI-এর সম্পর্ক কী?
AI-এর আদিকাল থেকে এ নিয়ে যুক্তি চলে আসছে যে, একদিকে "আরে, এটা অত কঠিন হবে না, আমাদের পক্ষে [super-special weapon] আছে", আর অন্যদিকে "[super-special weapon] যথেষ্ট হবে না"। Deep learning হলো এমন যুক্তিতে আমি শোনা সর্বশেষ super-special weapon; যুক্তির আগের সংস্করণগুলো logic, বা Prolog, বা expert system, বা সেদিনের সবচেয়ে শক্তিশালী কৌশল যা-ই হোক তা ব্যবহার করত। এমন যুক্তির সমস্যা হলো এরা তোমাকে কোনো ভালো উপায় দেয় না বলার যে কোনো প্রার্থী super-special weapon ঠিক কতটা শক্তিশালী। অবশ্যই, আমরা এইমাত্র একটা পুরো অধ্যায় কাটিয়েছি এই প্রমাণ পর্যালোচনা করে যে deep learning অত্যন্ত চ্যালেঞ্জিং সমস্যা সমাধান করতে পারে। এটা নিশ্চয়ই খুব উত্তেজনাপূর্ণ ও প্রতিশ্রুতিশীল দেখায়। কিন্তু Prolog বা Eurisko বা expert system-এর মতো system-ও তাদের দিনে তা-ই ছিল। তাই একটা ধারণার সেট খুব প্রতিশ্রুতিশীল দেখায় বলেই তা বেশি কিছু বোঝায় না। Deep learning সত্যিই এই আগের ধারণাগুলো থেকে ভিন্ন কিনা তা আমরা কীভাবে বুঝব? একটা ধারণার সেট কতটা শক্তিশালী ও প্রতিশ্রুতিশীল তা মাপার কোনো উপায় আছে? Conway's law ইঙ্গিত দেয় যে একটা মোটামুটি ও heuristic proxy metric হিসেবে আমরা সেই ধারণাগুলোর সাথে যুক্ত সামাজিক কাঠামোর জটিলতা মূল্যায়ন করতে পারি।
তাহলে দুটো প্রশ্ন জিজ্ঞাসা করতে হবে। প্রথমত, এই সামাজিক জটিলতার metric অনুযায়ী deep learning-এর সাথে যুক্ত ধারণার সেট কতটা শক্তিশালী? দ্বিতীয়ত, একটা সাধারণ artificial intelligence গড়তে সক্ষম হতে আমাদের কতটা শক্তিশালী তত্ত্ব লাগবে?
প্রথম প্রশ্নের ব্যাপারে: আজ deep learning-এর দিকে তাকালে এটা একটা উত্তেজনাপূর্ণ ও দ্রুতগতির, কিন্তু তুলনামূলকভাবে একশিলা ক্ষেত্র। কয়েকটি গভীর ধারণা আছে, কয়েকটি প্রধান conference আছে, এবং বেশ কয়েকটি conference-এর মধ্যে উল্লেখযোগ্য overlap। আর গবেষণাপত্রের পর গবেষণাপত্র একই মৌলিক ধারণা-সেট কাজে লাগাচ্ছে: একটা cost function optimize করতে stochastic gradient descent (বা তার কাছাকাছি কোনো রূপ) ব্যবহার। এই ধারণাগুলো এত সফল হওয়া চমৎকার। কিন্তু যা আমরা এখনও দেখি না তা হলো অনেক সুবিকশিত উপ-ক্ষেত্র, প্রতিটি নিজের গভীর ধারণা-সেট অন্বেষণ করছে, deep learning-কে নানা দিকে ঠেলছে। তাই সামাজিক জটিলতার metric অনুযায়ী, deep learning — শব্দের খেলা ক্ষমা করলে — এখনও একটা বেশ shallow ক্ষেত্র। এখনও একজন মানুষের পক্ষে ক্ষেত্রটির গভীরতম ধারণার বেশিরভাগ আয়ত্ত করা সম্ভব।
দ্বিতীয় প্রশ্নের ব্যাপারে: AI পেতে কতটা জটিল ও শক্তিশালী ধারণা-সেট লাগবে? অবশ্যই, এর উত্তর হলো: কেউ নিশ্চিতভাবে জানে না। তবে appendix-এ আমি এই প্রশ্নে বিদ্যমান কিছু প্রমাণ পরীক্ষা করি। আমি সিদ্ধান্তে পৌঁছাই যে, বেশ আশাবাদীভাবে ভাবলেও, একটা AI গড়তে অনেক, অনেক গভীর ধারণা লাগবে। তাই Conway's law ইঙ্গিত দেয় যে এমন একটা বিন্দুতে পৌঁছাতে আমরা অনিবার্যভাবে অনেক আন্তঃসম্পর্কিত discipline-এর উদ্ভব দেখব, যার একটা জটিল ও বিস্ময়কর কাঠামো আমাদের গভীরতম অন্তর্দৃষ্টির কাঠামোর প্রতিফলন ঘটাবে। Neural network ও deep learning-এর ব্যবহারে আমরা এখনও এই সমৃদ্ধ সামাজিক কাঠামো দেখি না। তাই আমি বিশ্বাস করি সাধারণ AI গড়তে deep learning ব্যবহার করা থেকে আমরা (অন্তত) কয়েক দশক দূরে।
আমি একটা যুক্তি গড়তে অনেক কষ্ট করেছি যা সংশয়াত্মক, হয়তো বেশ সুস্পষ্ট মনে হয়, এবং যার একটা অনিশ্চিত সিদ্ধান্ত আছে। এটা নিঃসন্দেহে নিশ্চয়তা-প্রত্যাশীদের হতাশ করবে। অনলাইনে ঘুরে আমি অনেককে দেখি AI সম্পর্কে খুব সুনির্দিষ্ট, খুব দৃঢ়ভাবে ধরে রাখা মতামত উচ্চস্বরে দাবি করতে, প্রায়ই দুর্বল যুক্তি ও অস্তিত্বহীন প্রমাণের ভিত্তিতে। আমার সরল মত হলো: এখনও বলার সময় হয়নি। পুরোনো রসিকতা যেমন বলে, একজন বিজ্ঞানীকে জিজ্ঞাসা করো কোনো আবিষ্কার কত দূরে আর তিনি যদি বলেন "10 বছর" (বা তার বেশি), তবে তিনি বোঝান "আমার কোনো ধারণা নেই"। AI, controlled fusion ও আরও কয়েকটি প্রযুক্তির মতো, 60 বছরেরও বেশি সময় ধরে 10 বছর দূরে আছে। অন্যদিকে, deep learning-এ আমাদের যা নিশ্চিতভাবে আছে তা হলো একটা শক্তিশালী কৌশল যার সীমা এখনও পাওয়া যায়নি, এবং অনেক সম্পূর্ণ-খোলা মৌলিক সমস্যা। এটা একটা উত্তেজনাপূর্ণ সৃজনশীল সুযোগ।