অধ্যায় ৪
Neural net যেকোনো function compute করতে পারে — একটি visual proof
A visual proof that neural nets can compute any function
Neural network সম্পর্কে সবচেয়ে চমকপ্রদ তথ্যগুলোর একটি হলো — এরা যেকোনো function-ই compute করতে পারে। অর্থাৎ ধরো কেউ তোমাকে একটা জটিল, এলোমেলো, আঁকাবাঁকা function ধরিয়ে দিল:
Function যেমনই হোক না কেন, এটা নিশ্চিত যে এমন একটা neural network থাকবে যাতে প্রতিটি সম্ভাব্য input -এর জন্য network-এর output হবে (বা তার কাছাকাছি একটা approximation), যেমন:
এই ফলাফল তখনও সত্যি থাকে যখন function-টির অনেকগুলো input থাকে, , এবং অনেকগুলো output থাকে। উদাহরণস্বরূপ, এই হলো এমন একটা network যা input ও output-যুক্ত একটা function compute করছে:
এই ফলাফল আমাদের বলে যে neural network-এর এক ধরনের universality আছে। আমরা যে function-ই compute করতে চাই না কেন, আমরা জানি এমন একটা neural network আছে যা কাজটা করতে পারে।
আরও বড় কথা, এই universality theorem তখনও খাটে যখন আমরা আমাদের network-কে input ও output neuron-এর মাঝে কেবল একটিমাত্র intermediate layer — তথাকথিত single hidden layer — রাখায় সীমাবদ্ধ করি। অর্থাৎ খুব সরল network architecture-ও অসম্ভব শক্তিশালী হতে পারে।
Neural network ব্যবহারকারীদের কাছে universality theorem সুপরিচিত। কিন্তু কেন এটা সত্যি তা ততটা ব্যাপকভাবে বোঝা যায় না। যেসব ব্যাখ্যা পাওয়া যায় তার বেশিরভাগই বেশ technical। যেমন, এই ফলাফল প্রমাণ করা মূল গবেষণাপত্রগুলোর একটি* কাজটি করেছে Hahn-Banach theorem, Riesz Representation theorem এবং কিছু Fourier analysis ব্যবহার করে। তুমি গণিতবিদ হলে যুক্তিটা অনুসরণ করা কঠিন নয়, কিন্তু বেশিরভাগ মানুষের জন্য তা সহজ নয়। এটা দুঃখজনক, কারণ universality-এর মূল কারণগুলো সরল ও সুন্দর।
এই অধ্যায়ে আমি universality theorem-এর একটি সরল ও মূলত visual ব্যাখ্যা দেব। আমরা ধাপে ধাপে মূল ধারণাগুলোর ভেতর দিয়ে যাব। তুমি বুঝবে কেন neural network যেকোনো function compute করতে পারে, এটা সত্যি। তুমি এই ফলাফলের কিছু সীমাবদ্ধতাও বুঝবে। আর বুঝবে এই ফলাফল deep neural network-এর সাথে কীভাবে সম্পর্কিত।
এই অধ্যায়ের উপাদান বুঝতে তোমাকে বইয়ের আগের অধ্যায়গুলো পড়তে হবে না। বরং অধ্যায়টি একটি স্বয়ংসম্পূর্ণ প্রবন্ধ হিসেবে উপভোগ করার মতো করে সাজানো। Neural network সম্পর্কে সামান্য মৌলিক পরিচিতি থাকলেই তুমি ব্যাখ্যাটা অনুসরণ করতে পারবে। তবে তোমার জ্ঞানের ফাঁক পূরণে সাহায্য করতে আমি মাঝে মাঝে আগের উপাদানের link দেব।
Universality theorem computer science-এ এতই সাধারণ যে কখনো কখনো আমরা ভুলে যাই এগুলো কতটা বিস্ময়কর। কিন্তু নিজেদের মনে করিয়ে দেওয়া দরকার: একটা যথেচ্ছ function compute করার ক্ষমতা সত্যিই অসাধারণ। তুমি কল্পনা করতে পারো এমন প্রায় যেকোনো প্রক্রিয়াকেই function computation হিসেবে ভাবা যায়। ধরো একটা সংগীতের ছোট্ট নমুনা শুনে গানটির নাম বের করার সমস্যা — একে function compute করা হিসেবে ভাবা যায়। কিংবা একটা চীনা লেখা ইংরেজিতে অনুবাদ করার সমস্যা — আবারও এটা একটা function compute করা*। অথবা একটা mp4 movie file নিয়ে তার কাহিনির বর্ণনা এবং অভিনয়ের মান নিয়ে আলোচনা তৈরির সমস্যা — এটাও এক ধরনের function computation†। Universality-এর মানে হলো, নীতিগতভাবে neural network এই সবকিছুই — এবং আরও অনেক কিছু — করতে পারে।
অবশ্য আমরা জানি যে চীনা লেখা ইংরেজিতে অনুবাদ করতে পারে এমন একটা neural network আছে — তার মানে এই নয় যে এমন network তৈরি করার, এমনকি চিনে নেওয়ার, ভালো কৌশল আমাদের আছে। এই সীমাবদ্ধতা Boolean circuit-এর মতো model-এর প্রচলিত universality theorem-এও খাটে। কিন্তু বইয়ের আগে আমরা দেখেছি, neural network-এ function শেখার শক্তিশালী algorithm আছে। Learning algorithm + universality-এর এই সমন্বয়টা একটা আকর্ষণীয় মিশ্রণ। এ পর্যন্ত বইটি learning algorithm-এর উপর মনোযোগ দিয়েছে। এই অধ্যায়ে আমরা universality এবং তার অর্থের উপর মনোযোগ দেব।
দুটি সতর্কতা
Universality theorem কেন সত্যি তা ব্যাখ্যা করার আগে, "একটা neural network যেকোনো function compute করতে পারে" — এই অনানুষ্ঠানিক বক্তব্যটি নিয়ে দুটি সতর্কতা উল্লেখ করতে চাই।
প্রথমত, এর মানে এই নয় যে একটা network দিয়ে যেকোনো function হুবহু compute করা যায়। বরং আমরা যতটা চাই ততটা ভালো একটা approximation পেতে পারি। Hidden neuron-এর সংখ্যা বাড়িয়ে আমরা approximation-টা উন্নত করতে পারি। যেমন, আগে আমি তিনটি hidden neuron ব্যবহার করে একটা function compute করা একটা network দেখিয়েছিলাম। বেশিরভাগ function-এর জন্য তিনটি hidden neuron দিয়ে কেবল একটা নিম্নমানের approximation সম্ভব হবে। Hidden neuron-এর সংখ্যা বাড়িয়ে (ধরো, পাঁচটিতে) আমরা সাধারণত আরও ভালো একটা approximation পেতে পারি:
আর hidden neuron-এর সংখ্যা আরও বাড়িয়ে আমরা আরও ভালো করতে পারি।
বক্তব্যটিকে আরও সুনির্দিষ্ট করতে, ধরো আমাদের একটা function দেওয়া হলো, যা আমরা কোনো কাঙ্ক্ষিত accuracy -এর মধ্যে compute করতে চাই। নিশ্চয়তা হলো — যথেষ্ট সংখ্যক hidden neuron ব্যবহার করে আমরা সবসময় এমন একটা neural network খুঁজে পেতে পারি যার output এই শর্ত মেনে চলে: প্রতিটি input -এর জন্য । অন্যভাবে বললে, approximation-টা প্রতিটি সম্ভাব্য input-এর জন্য কাঙ্ক্ষিত accuracy-র মধ্যে ভালো হবে।
দ্বিতীয় সতর্কতা হলো — যে শ্রেণির function এই বর্ণিত উপায়ে approximate করা যায়, সেগুলো হলো continuous function। কোনো function discontinuous হলে, অর্থাৎ হঠাৎ তীক্ষ্ণ লাফ দিলে, তাকে সাধারণভাবে neural net দিয়ে approximate করা সম্ভব হবে না। এটা অবাক করার মতো নয়, কারণ আমাদের neural network তাদের input-এর continuous function compute করে। তবে আমরা সত্যিকার অর্থে যে function compute করতে চাই সেটা discontinuous হলেও, প্রায়ই দেখা যায় একটা continuous approximation যথেষ্ট ভালো। তেমন হলে আমরা একটা neural network ব্যবহার করতে পারি। বাস্তবে এটা সাধারণত কোনো গুরুত্বপূর্ণ সীমাবদ্ধতা নয়।
সংক্ষেপে, universality theorem-এর আরও সুনির্দিষ্ট একটা বিবৃতি হলো — একটা single hidden layer-যুক্ত neural network দিয়ে যেকোনো continuous function-কে যেকোনো কাঙ্ক্ষিত নির্ভুলতায় approximate করা যায়। এই অধ্যায়ে আমরা আসলে এই ফলাফলের একটু দুর্বল একটা সংস্করণ প্রমাণ করব — একটি hidden layer-এর বদলে দুটি hidden layer ব্যবহার করে। সমস্যাগুলোতে আমি সংক্ষেপে দেখাব কীভাবে কয়েকটা সামান্য পরিবর্তনে ব্যাখ্যাটিকে কেবল একটি hidden layer ব্যবহারকারী একটা প্রমাণে রূপান্তর করা যায়।
এক input ও এক output-এ universality
Universality theorem কেন সত্যি তা বুঝতে, চলো শুরু করি কীভাবে কেবল একটা input ও একটা output-যুক্ত একটা function-কে approximate করে এমন একটা neural network তৈরি করা যায় তা বুঝে:
দেখা যায় এটাই universality সমস্যার মূল কেন্দ্র। এই বিশেষ ক্ষেত্রটা বুঝে ফেললে অনেক input ও অনেক output-যুক্ত function-এ একে বাড়িয়ে নেওয়া আসলে বেশ সহজ।
compute করার network কীভাবে তৈরি করতে হয় সে সম্পর্কে অন্তর্দৃষ্টি গড়তে, চলো এমন একটা network দিয়ে শুরু করি যাতে কেবল একটা hidden layer আছে, তাতে দুটি hidden neuron, আর একটা output neuron-যুক্ত একটা output layer আছে:
Network-এর component-গুলো কীভাবে কাজ করে তার একটা অনুভূতি পেতে, চলো উপরের hidden neuron-টার দিকে মনোযোগ দিই। মূল বইয়ের নিচের diagram-এ weight -এর উপর click করে mouse একটু ডানে টানলে বাড়ে, আর তখন উপরের hidden neuron যে function compute করছে তা কীভাবে বদলায় তা সাথে সাথে দেখা যায়:
বইয়ে আগে যেমন শিখেছি, hidden neuron যা compute করছে তা হলো , যেখানে হলো sigmoid function। এ পর্যন্ত আমরা এই algebraic রূপটা প্রায়ই ব্যবহার করেছি। কিন্তু universality-এর প্রমাণে algebra-কে পুরোপুরি উপেক্ষা করে এবং তার বদলে graph-এ দেখানো আকৃতিটিকে নাড়াচাড়া করে ও পর্যবেক্ষণ করে আমরা আরও বেশি অন্তর্দৃষ্টি পাব। এতে কী ঘটছে তা সম্পর্কে শুধু ভালো অনুভূতিই আসবে না, বরং এটা আমাদের universality-র এমন একটা প্রমাণও দেবে* যা sigmoid ছাড়া অন্য activation function-এর ক্ষেত্রেও প্রযোজ্য।
এই প্রমাণ শুরু করতে, উপরের diagram-এ bias -এর উপর click করে ডানে টানার চেষ্টা করো — bias বাড়লে graph-টা বাঁয়ে সরে যায়, কিন্তু আকৃতি বদলায় না।
এরপর bias কমাতে বাঁয়ে click করে টানো। দেখবে bias কমলে graph-টা ডানে সরে যায়, কিন্তু আবারও আকৃতি বদলায় না।
এরপর weight-কে বা -এর আশেপাশে কমাও। দেখবে weight কমালে curve-টা চওড়া হয়ে যায়। Curve-টা frame-এর মধ্যে রাখতে হয়তো bias-ও বদলাতে হবে।
শেষে, weight-কে ছাড়িয়ে বাড়াও। তখন curve-টা আরও খাড়া হতে থাকে, শেষে একটা step function-এর মতো দেখাতে শুরু করে। Bias এমনভাবে adjust করো যাতে step-টা -এর কাছে ঘটে।
আমরা weight এতটা বাড়িয়ে দিয়ে আমাদের বিশ্লেষণ অনেকটা সরল করতে পারি যাতে output সত্যিকার অর্থেই খুব ভালো approximation-এ একটা step function হয়ে যায়। নিচে আমি weight হলে উপরের hidden neuron-এর output plot করেছি। মনে রেখো এই plot-টি static, এবং তুমি weight-এর মতো parameter বদলাতে পারবে না।
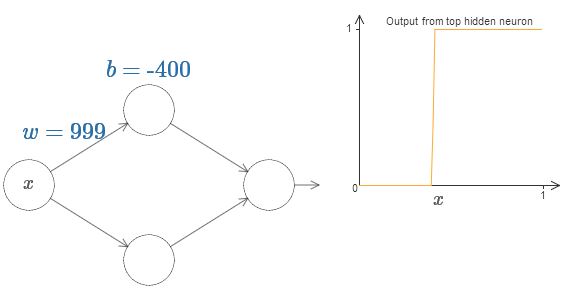
General sigmoid function-এর চেয়ে step function নিয়ে কাজ করা আসলে বেশ সহজ। কারণটা হলো — output layer-এ আমরা সব hidden neuron-এর অবদান যোগ করি। একগুচ্ছ step function-এর যোগফল বিশ্লেষণ করা সহজ, কিন্তু একগুচ্ছ sigmoid-আকৃতির curve যোগ করলে কী হয় তা নিয়ে যুক্তি করা বেশ কঠিন। তাই আমাদের hidden neuron-গুলো step function output দিচ্ছে — এটা ধরে নিলে কাজ অনেক সহজ হয়ে যায়। আরও সুনির্দিষ্টভাবে, আমরা weight -কে কোনো খুব বড় মানে স্থির রাখি, এবং তারপর bias বদলে step-এর অবস্থান ঠিক করি। অবশ্যই output-কে step function ধরা একটা approximation, কিন্তু এটা খুবই ভালো approximation, এবং আপাতত আমরা একে হুবহু বলে ধরে নেব। এই approximation থেকে বিচ্যুতির প্রভাব নিয়ে পরে আবার আলোচনা করব।
Step-টা -এর কোন মানে ঘটে? অন্যভাবে বললে, step-এর অবস্থান weight ও bias-এর উপর কীভাবে নির্ভর করে?
এই প্রশ্নের উত্তর দিতে, উপরের diagram-এ weight ও bias বদলে চেষ্টা করো (একটু উপরে scroll করতে হতে পারে)। তুমি কি বের করতে পারবে step-এর অবস্থান ও -এর উপর কীভাবে নির্ভর করে? একটু চেষ্টা করলেই নিজেকে বোঝাতে পারবে যে step-এর অবস্থান -এর সমানুপাতিক, এবং -এর ব্যস্তানুপাতিক।
আসলে step থাকে অবস্থানে, যা নিচের diagram-এ weight ও bias বদলে তুমি দেখতে পারো:
Hidden neuron-গুলোকে কেবল একটিমাত্র parameter — step-এর অবস্থান, — দিয়ে বর্ণনা করলে আমাদের জীবন অনেক সহজ হয়ে যাবে। নতুন এই parameterization-এ অভ্যস্ত হতে নিচের diagram-এ বদলে দেখো:
উপরে যেমন বলেছি, আমরা input-এর weight -কে নীরবে কোনো বড় মানে স্থির করেছি — যথেষ্ট বড় যাতে step function একটা খুব ভালো approximation হয়। এভাবে parameterize করা একটা neuron-কে আমরা সহজেই প্রচলিত model-এ ফিরিয়ে নিতে পারি, bias বেছে নিয়ে।
এতক্ষণ আমরা কেবল উপরের hidden neuron-এর output-এ মনোযোগ দিচ্ছিলাম। চলো এবার পুরো network-এর আচরণ দেখি। বিশেষ করে, ধরে নেব hidden neuron-গুলো step function compute করছে, যাদের step-বিন্দু (উপরের neuron) ও (নিচের neuron) দিয়ে parameterize করা। আর তাদের যথাক্রমে output weight হবে ও । এই হলো network-টি:
ডানে যা plot করা হচ্ছে তা হলো hidden layer থেকে আসা weighted output । এখানে ও যথাক্রমে উপরের ও নিচের hidden neuron-এর output*। এই output-গুলোকে দিয়ে লেখা হয়েছে কারণ এদের প্রায়ই neuron-এর activation বলা হয়।
উপরের hidden neuron-এর step-বিন্দু বাড়িয়ে-কমিয়ে দেখো। এটা hidden layer-এর weighted output কীভাবে বদলায় তার একটা অনুভূতি নাও।
যখন ছাড়িয়ে যায় তখন কী হয় তা বোঝা বিশেষভাবে গুরুত্বপূর্ণ। দেখবে এই মুহূর্তে graph-এর আকৃতি বদলে যায়, কারণ আমরা এমন একটা পরিস্থিতি থেকে — যেখানে উপরের hidden neuron প্রথমে active হয় — এমন একটায় চলে যাই যেখানে নিচের hidden neuron প্রথমে active হয়।
একইভাবে নিচের hidden neuron-এর step-বিন্দু নাড়াচাড়া করে দেখো, এবং hidden neuron-গুলোর সম্মিলিত output কীভাবে বদলায় তার অনুভূতি নাও।
প্রতিটি output weight বাড়িয়ে-কমিয়ে দেখো। লক্ষ করো এটা কীভাবে সংশ্লিষ্ট hidden neuron-এর অবদানকে rescale করে। কোনো একটা weight শূন্য হলে কী হয়?
শেষে, -কে ও -কে করে দেখো। তুমি একটা "bump" function পাবে, যা বিন্দুতে শুরু হয়, বিন্দুতে শেষ হয়, এবং যার উচ্চতা । যেমন, weighted output দেখতে এমন হতে পারে:
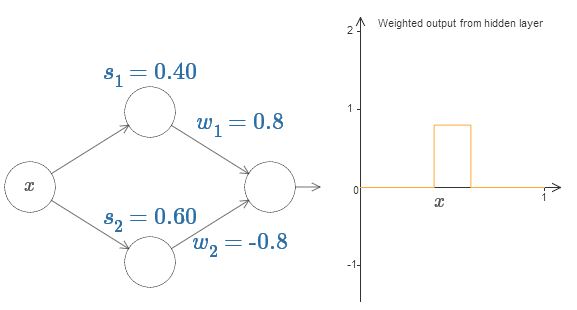
অবশ্যই, আমরা bump-টাকে rescale করে যেকোনো উচ্চতা দিতে পারি। চলো উচ্চতা বোঝাতে একটিমাত্র parameter ব্যবহার করি। জটিলতা কমাতে আমি "" ও "" notation-গুলোও সরিয়ে দেব।
প্রসঙ্গত লক্ষ করবে, আমরা neuron-গুলোকে এমনভাবে ব্যবহার করছি যাকে কেবল graphical ভাষায় নয়, আরও প্রচলিত programming ভাষায় এক ধরনের if-then-else statement হিসেবেও ভাবা যায়, যেমন:
if input >= step point:
add 1 to the weighted output
else:
add 0 to the weighted outputবেশিরভাগ ক্ষেত্রে আমি graphical দৃষ্টিভঙ্গিতেই থাকব। কিন্তু পরে কখনো কখনো দৃষ্টিভঙ্গি বদলে if-then-else-এর পরিভাষায় ভাবা তোমার জন্য সহায়ক হতে পারে।
আমাদের bump তৈরির এই কৌশল দিয়ে আমরা দুই জোড়া hidden neuron একই network-এ জুড়ে দিয়ে দুটি bump পেতে পারি:
এখানে আমি weight-গুলো চাপা দিয়েছি, কেবল প্রতিটি জোড়া hidden neuron-এর জন্য মান লিখেছি। দুটি মান-ই বাড়িয়ে-কমিয়ে দেখো graph কীভাবে বদলায়। Step-বিন্দু বদলে bump-গুলোকে এদিক-ওদিক সরাও।
আরও সাধারণভাবে, এই ধারণা দিয়ে আমরা যত খুশি তত peak — যেকোনো উচ্চতার — পেতে পারি। বিশেষ করে, আমরা ব্যবধিটাকে অনেক সংখ্যক, , উপ-ব্যবধিতে ভাগ করতে পারি, এবং জোড়া hidden neuron ব্যবহার করে যেকোনো কাঙ্ক্ষিত উচ্চতার peak তৈরি করতে পারি। চলো দেখি -এর জন্য এটা কীভাবে কাজ করে। এটা বেশ কিছু neuron, তাই আমি একটু ঠাসাঠাসি করে দেখাব। Diagram-এর জটিলতার জন্য ক্ষমাপ্রার্থী: আরও abstraction করে জটিলতাটা লুকিয়ে ফেলতে পারতাম, কিন্তু আমার মনে হয় এই network-গুলো কীভাবে কাজ করে তার আরও মূর্ত অনুভূতি পেতে একটু জটিলতা সহ্য করা সার্থক।
দেখতে পাচ্ছ পাঁচ জোড়া hidden neuron আছে। সংশ্লিষ্ট জোড়াগুলোর জন্য step-বিন্দু হলো , তারপর , এভাবে পর্যন্ত। এই মানগুলো স্থির — এগুলোর কারণেই আমরা graph-এ পাঁচটি সমদূরবর্তী bump পাই।
প্রতিটি জোড়া neuron-এর সাথে একটা মান যুক্ত। মনে রেখো, neuron থেকে বেরোনো connection-গুলোর weight হলো ও (চিহ্নিত নয়)। কোনো একটা মানের উপর click করে mouse ডানে বা বাঁয়ে টেনে মান বদলাও। সাথে সাথে function বদলাতে দেখো। Output weight বদলে আমরা আসলে function-টাকে design করছি!
উল্টোভাবে, graph-এর উপর click করে উপরে বা নিচে টেনে যেকোনো bump function-এর উচ্চতা বদলে দেখো। উচ্চতা বদলালে সংশ্লিষ্ট মানে অনুরূপ পরিবর্তন দেখতে পাবে। আর, দেখানো না হলেও, সংশ্লিষ্ট output weight-গুলোতেও পরিবর্তন ঘটে, যেগুলো ও ।
অন্যভাবে বললে, ডানের graph-এ দেখানো function-টাকে আমরা সরাসরি নাড়াচাড়া করতে পারি, এবং তা বাঁয়ের মানগুলোতে প্রতিফলিত হতে দেখি। মজার একটা কাজ হলো — mouse button চেপে ধরে graph-এর এক পাশ থেকে অন্য পাশে টেনে নিয়ে যাওয়া। এতে তুমি একটা function এঁকে ফেলো, এবং neural network-এর parameter-গুলো তার সাথে মানিয়ে নিতে দেখো।
একটা চ্যালেঞ্জের সময় হলো।
অধ্যায়ের শুরুতে যে function plot করেছিলাম তার কথা ভাবো:
তখন বলিনি, কিন্তু আমি যা plot করেছিলাম তা আসলে এই function:
যা -এর মান থেকে পর্যন্ত plot করা, আর অক্ষ থেকে পর্যন্ত মান নেয়।
এটা স্পষ্টতই কোনো তুচ্ছ function নয়।
তুমি বের করবে কীভাবে একটা neural network দিয়ে একে compute করা যায়।
উপরের network-গুলোতে আমরা hidden neuron থেকে আসা weighted combination বিশ্লেষণ করছিলাম। এই রাশির উপর কীভাবে অনেকটা নিয়ন্ত্রণ পেতে হয় তা এখন আমরা জানি। কিন্তু, আগে বলেছি, এই রাশি network থেকে যা output হয় তা নয়। Network থেকে যা output হয় তা হলো , যেখানে হলো output neuron-এর bias। Network-এর প্রকৃত output-এর উপর কি কোনোভাবে নিয়ন্ত্রণ পাওয়া যায়?
সমাধানটা হলো এমন একটা neural network design করা যার hidden layer-এর weighted output হবে , যেখানে হলো function-এর inverse। অর্থাৎ, আমরা চাই hidden layer-এর weighted output হোক:
এটা করতে পারলে পুরো network-এর output হবে -এর একটা ভালো approximation*।
তাহলে তোমার চ্যালেঞ্জ হলো — উপরে দেখানো লক্ষ্য-function approximate করার একটা neural network design করা। যতটা সম্ভব শেখার জন্য আমি চাই তুমি সমস্যাটা দুবার সমাধান করো। প্রথমবার graph-এর উপর click করে বিভিন্ন bump function-এর উচ্চতা সরাসরি adjust করো। লক্ষ্য-function-এর সাথে ভালো একটা মিল পাওয়া বেশ সহজ হওয়া উচিত। তুমি কতটা ভালো করছ তা মাপা হয় লক্ষ্য-function ও network যে function compute করছে তার মধ্যকার গড় বিচ্যুতি দিয়ে। তোমার চ্যালেঞ্জ হলো গড় বিচ্যুতি যতটা সম্ভব কম করা। গড় বিচ্যুতি বা তার কম করতে পারলেই চ্যালেঞ্জ সম্পূর্ণ।
সেটা করার পর "Reset"-এ click করে bump-গুলো এলোমেলোভাবে আবার initialize করো। দ্বিতীয়বার সমস্যাটা সমাধান করার সময় graph-এ click করার লোভ সামলাও। বরং বাঁ পাশের মানগুলো বদলাও, এবং আবার গড় বিচ্যুতি বা তার কম করার চেষ্টা করো।
Function approximately compute করার জন্য network-এর প্রয়োজনীয় সব উপাদান তুমি এখন বের করে ফেলেছ! এটা কেবল একটা মোটা approximation, কিন্তু hidden neuron-জোড়ার সংখ্যা বাড়িয়ে — আরও বেশি bump-এর সুযোগ দিয়ে — আমরা সহজেই অনেক ভালো করতে পারতাম।
বিশেষ করে, আমরা যে সব data পেয়েছি তা সহজেই neural network-এ ব্যবহৃত standard parameterization-এ ফিরিয়ে নেওয়া যায়। চলো দ্রুত একটু সারসংক্ষেপ করি কীভাবে তা কাজ করে।
প্রথম layer-এর সব weight-এর কোনো একটা বড়, ধ্রুব মান থাকবে, ধরো ।
Hidden neuron-গুলোর bias হলো কেবল । যেমন, দ্বিতীয় hidden neuron-এর জন্য হয়ে যায় ।
শেষ layer-এর weight-গুলো মান দিয়ে নির্ধারিত হয়। যেমন, প্রথম -এর জন্য তুমি উপরে যে মান বেছেছ, তা বোঝায় উপরের দুটি hidden neuron থেকে আসা output weight যথাক্রমে ও । এবং এভাবে পুরো output weight-এর layer জুড়ে।
শেষে, output neuron-এর bias ।
এই হলো সবকিছু: আমাদের কাছে এখন একটা সম্পূর্ণ neural network-এর বর্ণনা আছে যা আমাদের মূল লক্ষ্য-function বেশ ভালোভাবে compute করে। আর আমরা বুঝি hidden neuron-এর সংখ্যা বাড়িয়ে কীভাবে approximation-এর মান উন্নত করা যায়।
আরও বড় কথা, আমাদের মূল লক্ষ্য-function -এর বিশেষ কিছু ছিল না। থেকে -এর যেকোনো continuous function-এর জন্যই আমরা এই পদ্ধতি ব্যবহার করতে পারতাম। মূলত আমরা আমাদের single-layer neural network ব্যবহার করে function-টির জন্য একটা lookup table তৈরি করছি। আর universality-এর একটা সাধারণ প্রমাণ দিতে আমরা এই ধারণার উপর গড়ে তুলতে পারব।
অনেকগুলো input variable
চলো আমাদের ফলাফলকে অনেকগুলো input variable-এর ক্ষেত্রে বাড়িয়ে নিই। শুনতে জটিল মনে হলেও, আমাদের প্রয়োজনীয় সব ধারণা কেবল দুটি input-এর ক্ষেত্রেই বোঝা যায়। তাই চলো দুই-input ক্ষেত্রটা দেখি।
একটা neuron-এ দুটি input থাকলে কী হয় তা বিবেচনা করে শুরু করব:
এখানে আমাদের input ও , তাদের সংশ্লিষ্ট weight ও , আর neuron-এ একটা bias । চলো weight -কে করি, এবং তারপর প্রথম weight ও bias নিয়ে নাড়াচাড়া করে দেখি এরা neuron-এর output-কে কীভাবে প্রভাবিত করে:
দেখতেই পাচ্ছ, হলে input neuron-এর output-এ কোনো পার্থক্য আনে না। যেন -ই একমাত্র input।
এ অবস্থায়, শূন্য রেখে weight -কে পর্যন্ত বাড়ালে কী হবে বলে তোমার মনে হয়? উত্তরটা সাথে সাথে না দেখলে, একটু ভেবে দেখো কী হয় বের করতে পারো কিনা। তারপর চেষ্টা করে দেখো তুমি ঠিক কিনা। নিচের movie-তে আমি দেখিয়েছি কী হয়:
আমাদের আগের আলোচনার মতোই, input weight বড় হলে output একটা step function-এর দিকে এগোয়। পার্থক্য হলো এখন step function-টা ত্রিমাত্রিক। আগের মতোই, bias বদলে আমরা step-বিন্দুর অবস্থান সরাতে পারি। Step-বিন্দুর প্রকৃত অবস্থান হলো ।
চলো উপরেরটাই আবার করি, কিন্তু এবার step-এর অবস্থানকে parameter হিসেবে নিয়ে:
এখানে আমরা input-এর weight কোনো বড় মান ধরছি — আমি ব্যবহার করেছি — আর weight । Neuron-এর উপরের সংখ্যাটি হলো step-বিন্দু, আর সংখ্যার উপরের ছোট্ট মনে করিয়ে দেয় যে step-টা অভিমুখে।
অবশ্যই অভিমুখেও একটা step function পাওয়া সম্ভব — input-এর weight খুব বড় (ধরো ) এবং -এর weight (অর্থাৎ ) করে:
Neuron-এর উপরের সংখ্যাটি আবারও step-বিন্দু, আর এক্ষেত্রে সংখ্যার উপরের ছোট্ট মনে করিয়ে দেয় step-টা অভিমুখে। আমি ও input-এর weight স্পষ্টভাবে লিখতে পারতাম, কিন্তু diagram-কে এলোমেলো করে ফেলত বলে লিখিনি। তবে মনে রেখো — ছোট্ট চিহ্নটি নীরবে বলে দিচ্ছে যে weight বড় এবং weight ।
এইমাত্র তৈরি করা step function-গুলো ব্যবহার করে আমরা একটা ত্রিমাত্রিক bump function compute করতে পারি। এর জন্য আমরা দুটি neuron ব্যবহার করি, প্রতিটি অভিমুখে একটা step function compute করে। তারপর সেই step function-গুলোকে যথাক্রমে weight ও দিয়ে মিলিয়ে দিই, যেখানে হলো bump-এর কাঙ্ক্ষিত উচ্চতা। পুরোটা নিচের diagram-এ দেখানো হয়েছে:
উচ্চতা বদলে দেখো। লক্ষ করো এটা network-এর weight-এর সাথে কীভাবে সম্পর্কিত। আর ডানে bump function-এর উচ্চতা কীভাবে বদলায় তা দেখো।
এছাড়া উপরের hidden neuron-এর সাথে যুক্ত step-বিন্দু বদলে দেখো। লক্ষ করো এটা bump-এর আকৃতি কীভাবে বদলায়। নিচের hidden neuron-এর সাথে যুক্ত step-বিন্দু ছাড়িয়ে এটাকে সরালে কী হয়?
আমরা বের করেছি কীভাবে অভিমুখে একটা bump function বানাতে হয়। অবশ্যই, অভিমুখে দুটি step function ব্যবহার করে সহজেই অভিমুখেও একটা bump function বানাতে পারি। মনে রেখো, এটা করি input-এ weight বড়, আর input-এ weight করে। এই হলো ফলাফল:
এটা আগের network-এর প্রায় হুবহু! স্পষ্টভাবে যা বদলেছে তা হলো এখন আমাদের hidden neuron-গুলোর উপরে ছোট্ট চিহ্ন আছে। এটা মনে করিয়ে দেয় যে এরা -step নয়, -step function তৈরি করছে, তাই weight input-এ খুব বড় আর input-এ শূন্য, উল্টোটা নয়। আগের মতোই এলোমেলো এড়াতে আমি এটা স্পষ্টভাবে দেখাইনি।
চলো বিবেচনা করি, একটা অভিমুখের ও একটা অভিমুখের — দুটি bump function — একই উচ্চতা -এর — যোগ করলে কী হয়:
Diagram সরল করতে আমি শূন্য-weight-এর connection-গুলো বাদ দিয়েছি। আপাতত hidden neuron-গুলোর উপর ছোট্ট ও চিহ্ন রেখে দিয়েছি, যাতে মনে রাখো কোন অভিমুখে bump function compute হচ্ছে। পরে আমরা ওই চিহ্নগুলোও বাদ দেব, কারণ input variable দেখলেই সেগুলো বোঝা যায়।
Parameter বদলে দেখো। দেখতে পাচ্ছ, এটা output weight-গুলো বদলে দেয়, আর ও — দুই bump function-এর উচ্চতাও বদলে দেয়।
আমরা যা তৈরি করেছি তা কিছুটা একটা tower function-এর মতো দেখায়:
যদি এমন tower function বানাতে পারতাম, তবে বিভিন্ন উচ্চতার ও বিভিন্ন অবস্থানের অনেকগুলো tower যোগ করে আমরা যথেচ্ছ function approximate করতে পারতাম:
অবশ্য আমরা এখনও বের করিনি কীভাবে একটা tower function বানাতে হয়। আমরা যা তৈরি করেছি তা দেখায় একটা কেন্দ্রীয় tower, উচ্চতা , আর তার চারপাশে একটা মালভূমি (plateau), উচ্চতা ।
কিন্তু আমরা একটা tower function বানাতে পারি। মনে রেখো, আগে আমরা দেখেছি neuron দিয়ে এক ধরনের if-then-else statement implement করা যায়:
if combined output from hidden neurons >= threshold:
output 1
else:
output 0সেটা ছিল কেবল একটা input-যুক্ত neuron-এর জন্য। আমরা চাই hidden neuron-গুলোর সম্মিলিত output-এ অনুরূপ একটা ধারণা প্রয়োগ করতে। উপরের if-then-else-এ "input"-এর জায়গায় তাই বসে "hidden neuron-গুলোর সম্মিলিত output"।
Threshold-টা যথাযথভাবে — ধরো , যেটা মালভূমির উচ্চতা ও কেন্দ্রীয় tower-এর উচ্চতার মাঝখানে — বেছে নিলে আমরা মালভূমিটাকে শূন্যে চেপে নামিয়ে কেবল tower-টা দাঁড়িয়ে রাখতে পারি।
কীভাবে এটা করতে হয় দেখতে পাচ্ছ? নিচের network নিয়ে পরীক্ষা করে বের করার চেষ্টা করো। লক্ষ করো, আমরা এখন পুরো network-এর output plot করছি, কেবল hidden layer-এর weighted output নয়। এর মানে আমরা hidden layer-এর weighted output-এ একটা bias term যোগ করে function প্রয়োগ করি। ও -এর এমন মান কি খুঁজে পাচ্ছ যা একটা tower তৈরি করে? এটা একটু কঠিন, তাই কিছুক্ষণ ভেবেও আটকে গেলে দুটি ইঙ্গিত: (১) output neuron-এ ঠিকঠাক if-then-else আচরণ পেতে আমাদের input weight (সব বা ) বড় হওয়া দরকার; আর (২) -এর মান if-then-else threshold-এর scale ঠিক করে দেয়।
আমাদের প্রাথমিক parameter দিয়ে output দেখায় আগের diagram-এর — tower ও মালভূমিসহ — একটা চ্যাপ্টা সংস্করণের মতো। কাঙ্ক্ষিত আচরণ পেতে আমরা parameter -কে বড় না হওয়া পর্যন্ত বাড়াই। তাতে আসে if-then-else thresholding আচরণ। দ্বিতীয়ত, threshold ঠিক পেতে আমরা বেছে নেব। চেষ্টা করে দেখো কীভাবে কাজ করে!
ব্যবহার করলে এটা দেখতে এমন হয়:
-এর এই অপেক্ষাকৃত মাঝারি মানেও আমরা বেশ ভালো একটা tower function পাই। আর অবশ্যই, আরও বাড়িয়ে এবং bias রেখে আমরা একে যত খুশি ততটা ভালো করতে পারি।
চলো এমন দুটি network জুড়ে দিয়ে দুটি ভিন্ন tower function compute করার চেষ্টা করি। দুটি sub-network-এর নিজ নিজ ভূমিকা স্পষ্ট করতে নিচে আমি সেগুলোকে আলাদা box-এ রেখেছি: প্রতিটি box উপরে বর্ণিত কৌশলে একটা tower function compute করে। ডানের graph দ্বিতীয় hidden layer-এর weighted output দেখায়, অর্থাৎ এটা tower function-গুলোর একটা weighted combination।
বিশেষ করে, দেখতে পাচ্ছ চূড়ান্ত layer-এর weight বদলে তুমি output tower-গুলোর উচ্চতা বদলাতে পারো।
একই ধারণা দিয়ে আমরা যত খুশি তত tower compute করতে পারি। সেগুলোকে যত খুশি তত সরু, আর যেকোনো উচ্চতার করতে পারি। ফলে আমরা নিশ্চিত করতে পারি যে দ্বিতীয় hidden layer-এর weighted output দুই variable-এর যেকোনো কাঙ্ক্ষিত function-কে approximate করে:
বিশেষ করে, দ্বিতীয় hidden layer-এর weighted output-কে -এর একটা ভালো approximation বানিয়ে আমরা নিশ্চিত করি যে আমাদের network-এর output যেকোনো কাঙ্ক্ষিত function -এর একটা ভালো approximation হবে।
দুইয়ের বেশি variable-এর function নিয়ে কী বলা যায়?
চলো তিনটি variable দিয়ে চেষ্টা করি। নিচের network ব্যবহার করে চার-মাত্রায় একটা tower function compute করা যায়:
এখানে হলো network-এর input। ইত্যাদি হলো neuron-গুলোর step-বিন্দু — অর্থাৎ প্রথম layer-এর সব weight বড়, আর bias-গুলো এমনভাবে সেট করা যাতে step-বিন্দু পাওয়া যায়। দ্বিতীয় layer-এর weight পর্যায়ক্রমে , যেখানে কোনো খুব বড় সংখ্যা। আর output bias ।
এই network এমন একটা function compute করে যা তিনটি শর্ত পূরণ হলে হয়: থাকে ও -এর মধ্যে; থাকে ও -এর মধ্যে; আর থাকে ও -এর মধ্যে। বাকি সব জায়গায় network । অর্থাৎ এটা এক ধরনের tower যা input space-এর একটা ছোট্ট অঞ্চলে , আর বাকি সর্বত্র ।
এমন অনেকগুলো network জুড়ে দিয়ে আমরা যত খুশি তত tower পেতে পারি, এবং তাই তিন variable-এর একটা যথেচ্ছ function approximate করতে পারি। ঠিক একই ধারণা মাত্রায় কাজ করে। কেবল যে পরিবর্তনটা দরকার তা হলো output bias-কে করা, যাতে মালভূমি সমান করার জন্য সঠিক ধরনের sandwiching আচরণ পাওয়া যায়।
ঠিক আছে, এখন আমরা জানি কীভাবে neural network ব্যবহার করে অনেক variable-এর একটা real-valued function approximate করতে হয়। Vector-valued function নিয়ে কী বলা যায়? অবশ্যই এমন একটা function-কে -টি আলাদা real-valued function ইত্যাদি হিসেবে দেখা যায়। তাই আমরা approximate করা একটা network বানাই, -এর জন্য আরেকটা, এভাবে। তারপর সব network-কে সহজভাবে জুড়ে দিই। তাই এটাও সামলানো সহজ।
Sigmoid neuron-এর বাইরে সম্প্রসারণ
আমরা প্রমাণ করেছি যে sigmoid neuron দিয়ে গঠিত network যেকোনো function compute করতে পারে। মনে রেখো, একটা sigmoid neuron-এ input থেকে output আসে , যেখানে হলো weight, হলো bias, আর হলো sigmoid function:
যদি আমরা ভিন্ন ধরনের একটা neuron বিবেচনা করি, যা অন্য কোনো activation function ব্যবহার করে, তাহলে কী হয়:
অর্থাৎ আমরা ধরে নেব আমাদের neuron-এর input , weight ও bias হলে output হবে ।
Sigmoid-এর মতোই আমরা এই activation function ব্যবহার করে একটা step function পেতে পারি। নিচের diagram-এ weight বাড়িয়ে — ধরো পর্যন্ত — চেষ্টা করে দেখো:
Sigmoid-এর মতোই, এতে activation function সংকুচিত হয়, এবং শেষ পর্যন্ত একটা step function-এর খুব ভালো approximation হয়ে যায়। Bias বদলে দেখো — আমরা step-এর অবস্থান যেখানে খুশি সেখানে রাখতে পারি। আর তাই আমরা যেকোনো কাঙ্ক্ষিত function compute করতে আগের সব কৌশলই ব্যবহার করতে পারি।
এটা কাজ করার জন্য -এর কী কী ধর্ম পূরণ করা দরকার? আমাদের ধরে নিতে হবে যে ও -এ সুসংজ্ঞায়িত (well-defined)। এই দুই limit-ই হলো আমাদের step function যে দুটি মান নেয় সেগুলো। আমাদের আরও ধরে নিতে হবে যে এই দুই limit পরস্পর থেকে ভিন্ন। ভিন্ন না হলে কোনো step থাকত না, কেবল একটা সমতল graph থাকত! কিন্তু activation function এই ধর্মগুলো পূরণ করলে তেমন activation function-ভিত্তিক neuron computation-এর জন্য universal।
Step function-গুলো ঠিক করে নেওয়া
এতক্ষণ আমরা ধরে নিচ্ছিলাম যে আমাদের neuron হুবহু step function তৈরি করতে পারে। এটা একটা বেশ ভালো approximation, কিন্তু কেবল একটা approximation-ই। আসলে একটা সরু ব্যর্থতার জানালা (window of failure) থাকবে, যা নিচের graph-এ দেখানো হয়েছে, যেখানে function-টি একটা step function থেকে খুব ভিন্নভাবে আচরণ করে:
এই ব্যর্থতার জানালাগুলোতে universality-র জন্য আমার দেওয়া ব্যাখ্যা ভেঙে পড়বে।
তবে এটা ভয়াবহ কোনো ব্যর্থতা নয়। Neuron-এ input-এর weight যথেষ্ট বড় করে আমরা এই ব্যর্থতার জানালাগুলোকে যত খুশি তত সরু করতে পারি। নিশ্চিতভাবে আমরা উপরে দেখানোর চেয়ে অনেক সরু করতে পারি — এমনকি আমাদের চোখ যা দেখতে পায় তার চেয়েও সরু। তাই হয়তো আমরা এই সমস্যা নিয়ে খুব বেশি চিন্তা না-ও করতে পারি।
তবু সমস্যাটা সমাধানের একটা উপায় থাকলে ভালো হয়।
আসলে দেখা যায় সমস্যাটা সমাধান করা সহজ। চলো কেবল একটা input ও একটা output-যুক্ত function compute করা neural network-এর জন্য সমাধানটা দেখি। Input ও output বেশি হলেও একই ধারণা সমস্যাটি সমাধানে কাজ করে।
বিশেষ করে, ধরো আমরা চাই আমাদের network কোনো function compute করুক। আগের মতোই, এটা করি আমাদের network এমনভাবে design করার চেষ্টা করে যাতে hidden neuron-এর layer-এর weighted output হয় :
আগে বর্ণিত কৌশল দিয়ে এটা করতে গেলে আমরা hidden neuron দিয়ে একগুচ্ছ bump function-এর একটা ধারা তৈরি করতাম:
আবারও, ব্যর্থতার জানালাগুলো সহজে দেখাতে আমি এদের আকার অতিরঞ্জিত করেছি। স্পষ্ট হওয়া উচিত যে এই সব bump function যোগ করলে আমরা ব্যর্থতার জানালা ছাড়া সর্বত্র -এর একটা যুক্তিসঙ্গত approximation পাব।
ধরো এই বর্ণিত approximation ব্যবহার না করে, আমরা একগুচ্ছ hidden neuron ব্যবহার করি আমাদের মূল লক্ষ্য-function-এর অর্ধেক, অর্থাৎ -এর একটা approximation compute করতে। অবশ্যই, এটা দেখতে শেষ graph-টিরই একটা ছোট-করা সংস্করণের মতো:
আর ধরো আমরা আরেক গুচ্ছ hidden neuron ব্যবহার করি -এর একটা approximation compute করতে, কিন্তু bump-গুলোর ভিত্তি একটা bump-এর প্রস্থের অর্ধেক করে সরানো:
এখন আমাদের কাছে -এর দুটি ভিন্ন approximation আছে। এই দুই approximation যোগ করলে আমরা -এর একটা সামগ্রিক approximation পাব। সেই সামগ্রিক approximation-এও তখনও ছোট জানালায় ব্যর্থতা থাকবে। কিন্তু সমস্যাটা আগের চেয়ে অনেক কম হবে। কারণ একটা approximation-এর ব্যর্থতার জানালায় থাকা বিন্দুগুলো অন্য approximation-এর ব্যর্থতার জানালায় থাকবে না। তাই ওই জানালাগুলোতে approximation-টা মোটামুটি গুণ ভালো হবে।
আমরা আরও ভালো করতে পারি — function -এর অনেক সংখ্যক, -টি, overlap করা approximation যোগ করে। ব্যর্থতার জানালাগুলো যথেষ্ট সরু হলে, কোনো বিন্দু কখনো কেবল একটিমাত্র ব্যর্থতার জানালায় থাকবে। আর আমরা যথেষ্ট বড় সংখ্যক overlap করা approximation ব্যবহার করলে ফলাফল হবে একটা চমৎকার সামগ্রিক approximation।
উপসংহার
Universality-র যে ব্যাখ্যা আমরা আলোচনা করেছি তা অবশ্যই neural network দিয়ে কীভাবে compute করতে হয় তার কোনো ব্যবহারিক নির্দেশিকা নয়! এ দিক থেকে এটা NAND gate প্রভৃতির universality-র প্রমাণের মতোই। এই কারণে আমি বেশিরভাগই গঠনটিকে স্পষ্ট ও অনুসরণ করা সহজ করার চেষ্টায় মনোযোগ দিয়েছি, গঠনের খুঁটিনাটি optimize করায় নয়। তবে গঠনটিকে উন্নত করতে পারো কিনা তা দেখা একটা মজার ও শিক্ষণীয় অনুশীলন হতে পারে।
ফলাফলটা সরাসরি network তৈরিতে কাজে না এলেও এটা গুরুত্বপূর্ণ, কারণ এটা কোনো নির্দিষ্ট function neural network দিয়ে computable কিনা — এই প্রশ্নটাকেই আলোচনার টেবিল থেকে সরিয়ে দেয়। সেই প্রশ্নের উত্তর সবসময়ই "হ্যাঁ"। তাই সঠিক প্রশ্ন হলো কোনো নির্দিষ্ট function computable কিনা তা নয়, বরং function-টা compute করার একটা ভালো উপায় কী।
আমরা যে universality গঠন গড়ে তুলেছি তা একটা যথেচ্ছ function compute করতে কেবল দুটি hidden layer ব্যবহার করে। তাছাড়া, আমরা আলোচনা করেছি, কেবল একটি hidden layer দিয়েও একই ফলাফল পাওয়া সম্ভব। এ অবস্থায় তুমি ভাবতে পারো তবে আমরা deep network — অর্থাৎ অনেক hidden layer-যুক্ত network — নিয়ে কেন আগ্রহী হব। আমরা কি ওই network-গুলোকে কেবল shallow, single hidden layer-যুক্ত network দিয়ে প্রতিস্থাপন করতে পারি না?
নীতিগতভাবে তা সম্ভব হলেও, deep network ব্যবহারের ভালো ব্যবহারিক কারণ আছে। অধ্যায় ১-এ যেমন যুক্তি দেওয়া হয়েছে, deep network-এর একটা শ্রেণিবদ্ধ গঠন আছে যা বাস্তব-জগতের সমস্যা সমাধানে কাজে লাগে এমন জ্ঞানের শ্রেণিবিন্যাস শিখতে এদের বিশেষভাবে উপযোগী করে তোলে। আরও মূর্তভাবে বললে, image recognition-এর মতো সমস্যা মোকাবিলায় এমন একটা system ব্যবহার করা সহায়ক যা কেবল আলাদা আলাদা pixel নয়, বরং ক্রমশ আরও জটিল ধারণাও বোঝে: edge থেকে সরল জ্যামিতিক আকৃতি, এভাবে জটিল, বহু-object দৃশ্য পর্যন্ত। পরের অধ্যায়গুলোতে আমরা এমন প্রমাণ দেখব যা ইঙ্গিত করে এ ধরনের জ্ঞানের শ্রেণিবিন্যাস শেখায় deep network shallow network-এর চেয়ে ভালো কাজ করে। সংক্ষেপে: universality আমাদের বলে neural network যেকোনো function compute করতে পারে; আর অভিজ্ঞতালব্ধ প্রমাণ ইঙ্গিত করে যে অনেক বাস্তব-জগতের সমস্যা সমাধানে কাজে লাগে এমন function শেখার জন্য deep network-ই সবচেয়ে উপযোগী।