অধ্যায় ৫
Deep neural network train করা কেন কঠিন?
Why are deep neural networks hard to train?
ধরো তুমি একজন engineer, আর তোমাকে শূন্য থেকে একটা computer design করতে বলা হয়েছে। একদিন তুমি তোমার office-এ কাজ করছ, logical circuit design করছ, AND gate, OR gate ইত্যাদি সাজাচ্ছ — এমন সময় তোমার boss একটা খারাপ খবর নিয়ে এলেন। গ্রাহক সবেমাত্র একটা অদ্ভুত design-শর্ত যোগ করেছেন: গোটা computer-এর circuit-টা হতে হবে মাত্র দুই layer গভীর:
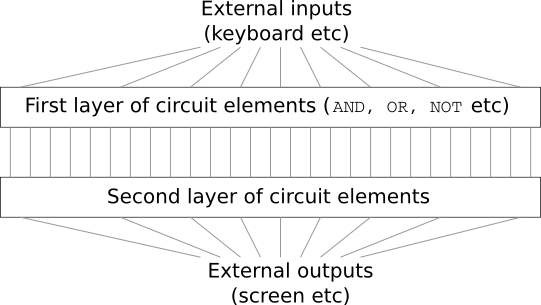
তুমি হতভম্ব হয়ে boss-কে বললে: "গ্রাহক তো পাগল!"
Boss জবাব দিলেন: "আমিও তা-ই মনে করি। কিন্তু গ্রাহক যা চায়, সেটাই তো তাকে দিতে হবে।"
আসলে একটা সীমিত অর্থে গ্রাহক পাগল নন। ধরো তোমাকে এমন একটা বিশেষ logical gate ব্যবহার করতে দেওয়া হলো যা যত খুশি input একসাথে AND করতে পারে। আর সাথে দেওয়া হলো একটা বহু-input NAND gate, অর্থাৎ এমন একটা gate যা একাধিক input AND করে তারপর output-টা negate করে দেয়। এই বিশেষ gate দিয়ে দেখা যায় মাত্র দুই layer গভীর একটা circuit দিয়েই যেকোনো function compute করা সম্ভব।
কিন্তু কোনো কিছু সম্ভব হওয়া মানেই সেটা ভালো বুদ্ধি নয়। বাস্তবে, circuit design সমস্যা (কিংবা প্রায় যেকোনো algorithmic সমস্যা) সমাধানের সময় আমরা সাধারণত আগে ছোট ছোট উপ-সমস্যা কীভাবে সমাধান করা যায় তা বের করি, তারপর ধীরে ধীরে সেই সমাধানগুলোকে একসাথে জুড়ি। অন্যভাবে বললে, আমরা একাধিক layer-এর abstraction-এর মধ্য দিয়ে একটা সমাধানের দিকে এগোই।
যেমন ধরো দুটি সংখ্যা গুণ করার জন্য আমরা একটা logical circuit design করছি। সম্ভবত আমরা একে দুটি সংখ্যা যোগ করার মতো operation করা sub-circuit দিয়ে গড়ে তুলতে চাইব। দুটি সংখ্যা যোগ করার sub-circuit আবার দুটি bit যোগ করার sub-sub-circuit দিয়ে তৈরি হবে। মোটা দাগে আমাদের circuit দেখতে এরকম হবে:
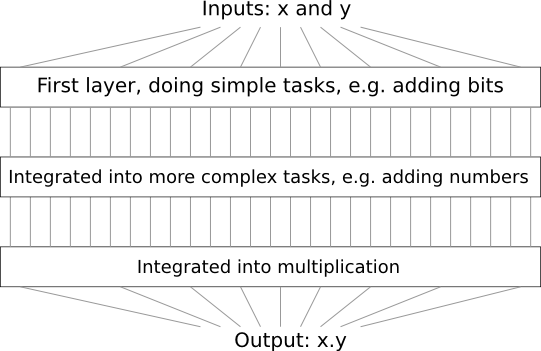
অর্থাৎ আমাদের চূড়ান্ত circuit-এ অন্তত তিন layer circuit element থাকে। আসলে এতে সম্ভবত তিনের বেশি layer থাকবে, কারণ আমি যতটা বর্ণনা করেছি তার চেয়েও ছোট ছোট unit-এ আমরা sub-task ভাঙব। কিন্তু সাধারণ ধারণাটা তুমি বুঝতে পেরেছ।
তাহলে deep circuit design-এর প্রক্রিয়া সহজ করে দেয়। তবে এরা কেবল design-এর জন্যই সহায়ক নয়। আসলে গাণিতিক প্রমাণও আছে যে কিছু function-এর জন্য খুব অগভীর (shallow) circuit-এর তুলনায় deep circuit-এ exponentially কম circuit element লাগে। যেমন ১৯৮০-এর দশকের শুরুর দিকের একটি বিখ্যাত গবেষণা-ধারা
দেখিয়েছিল যে একগুচ্ছ bit-এর parity compute করতে অগভীর circuit ব্যবহার করলে exponentially অনেক gate লাগে। অন্যদিকে deeper circuit ব্যবহার করলে একটা ছোট circuit দিয়েই parity সহজে compute করা যায়: তুমি কেবল জোড়ায় জোড়ায় bit-এর parity বের করো, তারপর সেই ফলাফল দিয়ে জোড়া-জোড়ার parity বের করো, এভাবে দ্রুত সামগ্রিক parity-তে পৌঁছে যাও। তাই deep circuit আসলে shallow circuit-এর চেয়ে অন্তর্নিহিতভাবে অনেক বেশি শক্তিশালী হতে পারে।
এতক্ষণ পর্যন্ত এই বইটি neural network-কে সেই পাগল গ্রাহকের মতোই দেখে এসেছে। আমরা যেসব network নিয়ে কাজ করেছি তাদের প্রায় সবার একটিমাত্র hidden layer ছিল (input ও output layer ছাড়া):
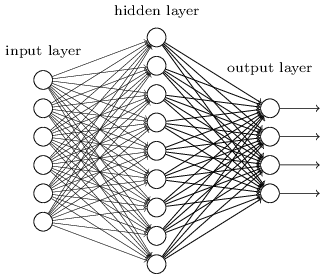
এই সরল network-গুলো লক্ষণীয়ভাবে কার্যকর হয়েছে: আগের অধ্যায়গুলোতে আমরা এমন network ব্যবহার করে ৯৮ শতাংশের বেশি accuracy-তে হাতে লেখা সংখ্যা classify করেছি! তবু স্বজ্ঞাতভাবে আমরা আশা করব আরও বেশি hidden layer-যুক্ত network আরও শক্তিশালী হবে:
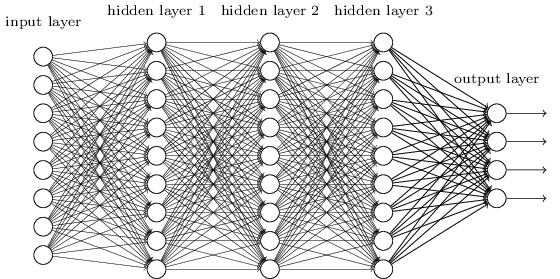
এমন network মধ্যবর্তী layer-গুলো ব্যবহার করে একাধিক স্তরের abstraction গড়ে তুলতে পারত, ঠিক যেমন আমরা Boolean circuit-এ করি। যেমন আমরা যদি visual pattern recognition করি, তাহলে প্রথম layer-এর neuron হয়তো edge চিনতে শিখতে পারে, দ্বিতীয় layer-এর neuron সেই edge দিয়ে গড়ে ওঠা আরও জটিল আকৃতি — যেমন triangle বা rectangle — চিনতে শিখতে পারে। তৃতীয় layer তখন আরও জটিল আকৃতি চিনবে। এভাবে চলতে থাকবে। এই একাধিক স্তরের abstraction জটিল pattern recognition সমস্যা সমাধান শেখায় deep network-কে একটা প্রবল সুবিধা দেবে বলে মনে হয়। তাছাড়া circuit-এর ক্ষেত্রের মতোই, তাত্ত্বিক ফলাফলও আছে যা ইঙ্গিত দেয় deep network অন্তর্নিহিতভাবে shallow network-এর চেয়ে বেশি শক্তিশালী।
এমন deep network আমরা কীভাবে train করব? এই অধ্যায়ে আমরা আমাদের চিরচেনা learning algorithm — backpropagation-এর মাধ্যমে stochastic gradient descent — দিয়ে deep network train করার চেষ্টা করব। কিন্তু আমরা সমস্যায় পড়ব: আমাদের deep network-গুলো shallow network-এর চেয়ে খুব একটা ভালো (যদি আদৌ ভালো) পারফর্ম করবে না।
উপরের আলোচনার আলোকে এই ব্যর্থতা অবাক করার মতো মনে হয়। deep network ছেড়ে দেওয়ার বদলে আমরা গভীরে গিয়ে বোঝার চেষ্টা করব কেন আমাদের deep network train করা কঠিন হচ্ছে। যখন আমরা ভালো করে দেখব, তখন আবিষ্কার করব যে আমাদের deep network-এর বিভিন্ন layer একে অপরের চেয়ে অত্যন্ত ভিন্ন গতিতে শিখছে। বিশেষ করে, network-এর পরের দিকের layer-গুলো যখন ভালোভাবে শিখছে, তখন শুরুর দিকের layer-গুলো প্রায়ই training-এর সময় আটকে যায়, প্রায় কিছুই শেখে না। এই আটকে যাওয়া কেবল দুর্ভাগ্যের কারণে নয়। বরং আমরা দেখব এই learning slowdown ঘটার মৌলিক কিছু কারণ আছে, যা gradient-ভিত্তিক learning কৌশল ব্যবহারের সাথে জড়িত।
সমস্যাটায় আরও গভীরে ঢুকতে গিয়ে আমরা জানব যে এর উল্টো ঘটনাও ঘটতে পারে: শুরুর দিকের layer-গুলো হয়তো ভালোভাবে শিখছে, কিন্তু পরের দিকের layer আটকে যেতে পারে। আসলে আমরা দেখব deep, বহু-layer neural network-এ gradient descent দিয়ে শেখার সাথে একটা অন্তর্নিহিত অস্থিরতা (instability) জড়িত। এই অস্থিরতা প্রায়ই training-এর সময় শুরুর কিংবা পরের layer-গুলোর কোনো একটিকে আটকে দেয়।
এ সবই খারাপ খবরের মতো শোনায়। কিন্তু এই অসুবিধাগুলোর গভীরে ঢুকে আমরা deep network কার্যকরভাবে train করতে কী কী প্রয়োজন সে সম্পর্কে অন্তর্দৃষ্টি পেতে শুরু করতে পারি। তাই এই অনুসন্ধানগুলো পরের অধ্যায়ের ভালো প্রস্তুতি, যেখানে আমরা image recognition সমস্যা সমাধানে deep learning ব্যবহার করব।
Vanishing gradient সমস্যা
আচ্ছা, deep network train করতে গেলে কী ভুল হয়ে যায়?
এই প্রশ্নের উত্তর দিতে চলো আগে একটিমাত্র hidden layer-যুক্ত network-এর ক্ষেত্রে ফিরে যাই। যথারীতি আমরা শেখা ও পরীক্ষা-নিরীক্ষার খেলার মাঠ হিসেবে MNIST সংখ্যা classification সমস্যা ব্যবহার করব।
চাইলে তুমি নিজের computer-এ network train করে সাথে সাথে অনুসরণ করতে পারো। অবশ্যই কেবল পড়ে গেলেও কোনো অসুবিধা নেই। যদি live অনুসরণ করতে চাও, তাহলে তোমার লাগবে Python 2.7, Numpy, আর code-এর একটা copy — যেটা তুমি command line থেকে সংশ্লিষ্ট repository clone করে পেতে পারো:
git clone https://github.com/mnielsen/neural-networks-and-deep-learning.gitতুমি যদি git ব্যবহার না করো, তাহলে data ও code সরাসরি download করতে পারো। তোমাকে src subdirectory-তে যেতে হবে।
তারপর একটা Python shell থেকে আমরা MNIST data load করি:
>>> import mnist_loader
>>> training_data, validation_data, test_data = \
... mnist_loader.load_data_wrapper()আমরা আমাদের network সাজাই:
>>> import network2
>>> net = network2.Network([784, 30, 10])এই network-এর input layer-এ ৭৮৪টি neuron আছে, যা input image-এর pixel-এর সাথে সঙ্গতিপূর্ণ। আমরা ৩০টি hidden neuron, এবং ১০টি output neuron ব্যবহার করি — শেষেরগুলো MNIST সংখ্যার ১০টি সম্ভাব্য classification ('0', '1', '2', , '9')-এর সাথে সঙ্গতিপূর্ণ।
চলো আমাদের network-কে ৩০টি পূর্ণ epoch ধরে train করার চেষ্টা করি, একবারে ১০টি training example-এর mini-batch নিয়ে, learning rate , আর regularization parameter সহ। Train করার সময় আমরা validation_data-এর উপর classification accuracy নজরে রাখব:
>>> net.SGD(training_data, 30, 10, 0.1, lmbda=5.0,
... evaluation_data=validation_data, monitor_evaluation_accuracy=True)আমরা ৯৬.৪৮ শতাংশ classification accuracy পাই (বা তার আশেপাশে — প্রতি run-এ একটু পরিবর্তিত হবে), যা একই রকম configuration-এ আমাদের আগের ফলাফলের তুলনীয়।
এবার চলো আরেকটা hidden layer যোগ করি, সেটাতেও ৩০টি neuron রাখি, এবং একই hyper-parameter দিয়ে train করার চেষ্টা করি:
>>> net = network2.Network([784, 30, 30, 10])
>>> net.SGD(training_data, 30, 10, 0.1, lmbda=5.0,
... evaluation_data=validation_data, monitor_evaluation_accuracy=True)এতে উন্নত classification accuracy পাওয়া যায়, ৯৬.৯০ শতাংশ। এটা উৎসাহব্যঞ্জক: একটু বেশি গভীরতা সাহায্য করছে। চলো আরেকটা ৩০-neuron-এর hidden layer যোগ করি:
>>> net = network2.Network([784, 30, 30, 30, 10])
>>> net.SGD(training_data, 30, 10, 0.1, lmbda=5.0,
... evaluation_data=validation_data, monitor_evaluation_accuracy=True)এতে একটুও সাহায্য হলো না। আসলে ফলাফল আবার ৯৬.৫৭ শতাংশে নেমে এলো, যা আমাদের মূল shallow network-এর কাছাকাছি। আর ধরো আমরা আরও একটা hidden layer ঢোকালাম:
>>> net = network2.Network([784, 30, 30, 30, 30, 10])
>>> net.SGD(training_data, 30, 10, 0.1, lmbda=5.0,
... evaluation_data=validation_data, monitor_evaluation_accuracy=True)Classification accuracy আবার নেমে গিয়ে ৯৬.৫৩ শতাংশ হলো। এটা সম্ভবত পরিসংখ্যানগতভাবে উল্লেখযোগ্য পতন নয়, তবে উৎসাহব্যঞ্জকও নয়।
এই আচরণ অদ্ভুত মনে হয়। স্বজ্ঞাতভাবে অতিরিক্ত hidden layer থাকলে network-এর আরও জটিল classification function শেখার ক্ষমতা থাকা উচিত, ফলে classify করার কাজটা আরও ভালো হওয়া উচিত। অন্তত পরিস্থিতি খারাপ হওয়া উচিত নয়, কারণ সবচেয়ে খারাপ ক্ষেত্রে অতিরিক্ত layer-গুলো কেবল কিছুই না করে চুপ করে থাকতে পারে।
কিন্তু আসলে যা ঘটছে তা এমন নয়।
তাহলে কী ঘটছে? ধরে নিই অতিরিক্ত hidden layer-গুলো নীতিগতভাবে সত্যিই সাহায্য করতে পারত, আর সমস্যাটা হলো আমাদের learning algorithm সঠিক weight ও bias খুঁজে পাচ্ছে না। আমরা বের করতে চাই আমাদের learning algorithm-এ ঠিক কী ভুল হচ্ছে, আর কীভাবে আরও ভালো করা যায়।
কী ভুল হচ্ছে তা নিয়ে কিছুটা অন্তর্দৃষ্টি পেতে চলো দেখি network কীভাবে শেখে, তা visualize করি। নিচে আমি একটা network-এর অংশ এঁকেছি, অর্থাৎ দুটি hidden layer-যুক্ত একটা network, যার প্রতিটিতে টি hidden neuron আছে। ছবিতে প্রতিটি neuron-এর গায়ে একটা ছোট bar আছে, যা দেখায় network শেখার সাথে সাথে ওই neuron কত দ্রুত পরিবর্তিত হচ্ছে। বড় bar মানে neuron-এর weight ও bias দ্রুত পরিবর্তিত হচ্ছে, ছোট bar মানে weight ও bias ধীরে পরিবর্তিত হচ্ছে। আরও সূক্ষ্মভাবে, bar-গুলো প্রতিটি neuron-এর জন্য gradient বোঝায়, অর্থাৎ neuron-এর bias-এর সাপেক্ষে cost-এর পরিবর্তনের হার। Chapter 2-তে আমরা দেখেছিলাম এই gradient রাশিটি শুধু learning-এর সময় bias কত দ্রুত পরিবর্তিত হয় তা-ই নয়, neuron-এ আসা weight কত দ্রুত পরিবর্তিত হয় তাও নিয়ন্ত্রণ করে। খুঁটিনাটি মনে না থাকলে চিন্তা কোরো না: মনে রাখার বিষয় শুধু এটুকু যে এই bar-গুলো দেখায় network শেখার সাথে সাথে প্রতিটি neuron-এর weight ও bias কত দ্রুত পরিবর্তিত হচ্ছে।
ছবিটা সরল রাখতে আমি দুই hidden layer-এর কেবল উপরের ছয়টি neuron দেখিয়েছি। Input neuron বাদ দিয়েছি, কারণ তাদের শেখার মতো কোনো weight বা bias নেই। Output neuron-ও বাদ দিয়েছি, কারণ আমরা layer-ভিত্তিক তুলনা করছি, আর একই সংখ্যক neuron-যুক্ত layer তুলনা করাই সবচেয়ে যুক্তিযুক্ত। ফলাফলগুলো training-এর একদম শুরুতে, অর্থাৎ network initialize হওয়ার ঠিক পরেই, plot করা হয়েছে। এই হলো সেগুলো:
Network-টি random ভাবে initialize করা হয়েছিল, তাই neuron-গুলো কত দ্রুত শেখে তাতে অনেক বৈচিত্র্য থাকা অবাক করার মতো নয়। তবু একটা জিনিস চোখে পড়ে: দ্বিতীয় hidden layer-এর bar-গুলো বেশিরভাগই প্রথম hidden layer-এর bar-গুলোর চেয়ে অনেক বড়। ফলে দ্বিতীয় hidden layer-এর neuron প্রথম hidden layer-এর neuron-এর চেয়ে বেশ দ্রুত শিখবে। এটা কি কেবল একটা কাকতাল, নাকি সাধারণভাবেই দ্বিতীয় hidden layer-এর neuron প্রথম hidden layer-এর neuron-এর চেয়ে দ্রুত শেখার সম্ভাবনা থাকে?
এটা সত্যি কিনা নির্ধারণ করতে প্রথম ও দ্বিতীয় hidden layer-এর শেখার গতি তুলনা করার একটা সামগ্রিক (global) উপায় থাকলে সুবিধা হয়। এর জন্য চলো gradient-কে লিখি , অর্থাৎ -তম layer-এর -তম neuron-এর gradient।
Gradient -কে আমরা এমন একটা vector হিসেবে ভাবতে পারি যার entry-গুলো ঠিক করে প্রথম hidden layer কত দ্রুত শেখে, আর -কে এমন একটা vector হিসেবে যার entry-গুলো ঠিক করে দ্বিতীয় hidden layer কত দ্রুত শেখে। তারপর আমরা এই vector-গুলোর দৈর্ঘ্যকে layer-গুলো কত গতিতে শিখছে তার (মোটামুটি!) সামগ্রিক পরিমাপ হিসেবে ব্যবহার করব। যেমন দৈর্ঘ্য মাপে প্রথম hidden layer কত গতিতে শিখছে, আর মাপে দ্বিতীয় hidden layer কত গতিতে শিখছে।
এই সংজ্ঞাগুলো নিয়ে, এবং উপরে যে configuration plot করা হয়েছিল সেটাতেই, আমরা পাই ও । অর্থাৎ এটা আমাদের আগের সন্দেহ নিশ্চিত করে: দ্বিতীয় hidden layer-এর neuron সত্যিই প্রথম hidden layer-এর neuron-এর চেয়ে অনেক দ্রুত শিখছে।
আরও hidden layer যোগ করলে কী হয়? যদি তিনটি hidden layer থাকে, একটা network-এ, তাহলে শেখার সংশ্লিষ্ট গতিগুলো দাঁড়ায় 0.012, 0.060 ও 0.283। আবারও, শুরুর দিকের hidden layer পরের দিকের hidden layer-এর চেয়ে অনেক ধীরে শিখছে। ধরো আমরা আরও একটা -neuron-এর layer যোগ করলাম। সেক্ষেত্রে শেখার গতি দাঁড়ায় 0.003, 0.017, 0.070 ও 0.285। প্যাটার্নটা বজায় থাকে: শুরুর layer পরের layer-এর চেয়ে ধীরে শেখে।
আমরা training-এর শুরুতে, অর্থাৎ network initialize হওয়ার ঠিক পরে, শেখার গতি দেখছিলাম। Network train করার সাথে সাথে শেখার গতি কীভাবে বদলায়? চলো আবার কেবল দুটি hidden layer-যুক্ত network-এর দিকে তাকাই। শেখার গতি এভাবে বদলায়:
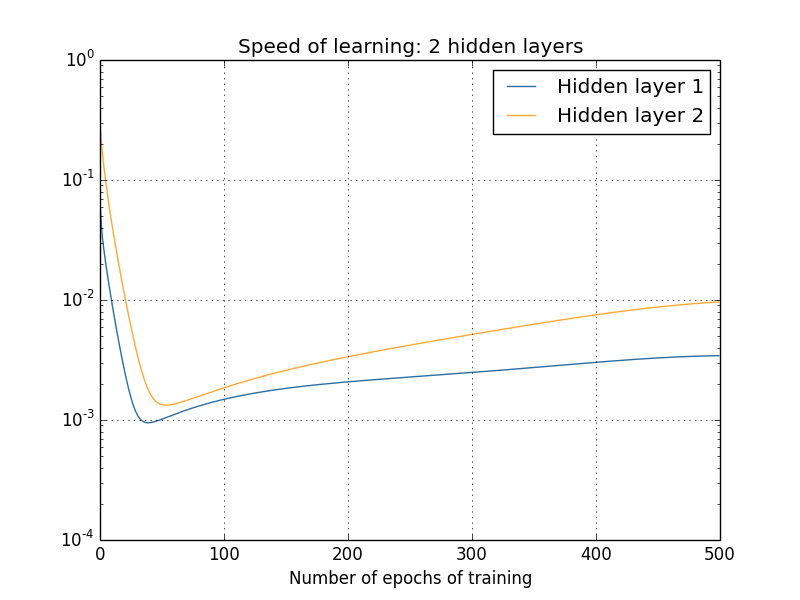
এই ফলাফলগুলো তৈরি করতে আমি কেবল ১,০০০ training image নিয়ে batch gradient descent ব্যবহার করেছি, ৫০০ epoch ধরে train করেছি। এটা আমরা সাধারণত যেভাবে train করি তার চেয়ে একটু আলাদা — আমি কোনো mini-batch ব্যবহার করিনি, আর পুরো ৫০,০০০ image-এর training set-এর বদলে কেবল ১,০০০ training image নিয়েছি। আমি কোনো চালাকি করছি না, বা তোমার চোখে ধুলো দিচ্ছি না; তবে দেখা যায় mini-batch stochastic gradient descent ব্যবহার করলে ফলাফল অনেক বেশি noisy হয় (যদিও noise গড় করে ফেললে খুবই একই রকম)। আমি যে parameter বেছেছি তা ফলাফল মসৃণ করার একটা সহজ উপায়, যাতে কী ঘটছে তা দেখা যায়।
যাই হোক, তুমি দেখতে পাচ্ছ দুটি layer খুব ভিন্ন গতিতে শেখা শুরু করে (যা আমরা আগেই জানি)। তারপর দুই layer-এই গতি খুব দ্রুত নেমে যায়, এরপর আবার কিছুটা বেড়ে ওঠে। কিন্তু সবকিছুর মধ্যেও প্রথম hidden layer দ্বিতীয় hidden layer-এর চেয়ে অনেক ধীরে শেখে।
আরও জটিল network-এর ক্ষেত্রে কী হয়? এই হলো একই রকম একটা পরীক্ষার ফলাফল, তবে এবার তিনটি hidden layer সহ (একটা network):
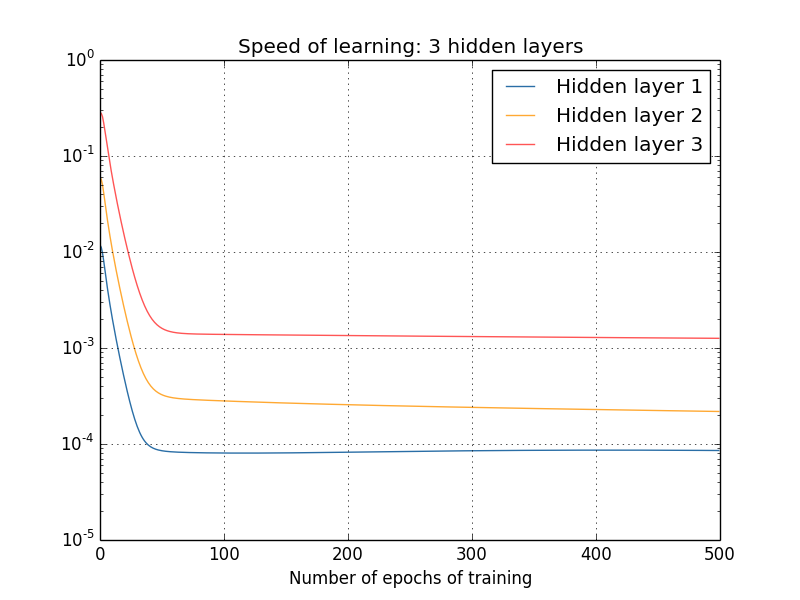
আবারও, শুরুর দিকের hidden layer পরের দিকের hidden layer-এর চেয়ে অনেক ধীরে শেখে। শেষে চলো একটা চতুর্থ hidden layer যোগ করি (একটা network), আর train করলে কী হয় দেখি:
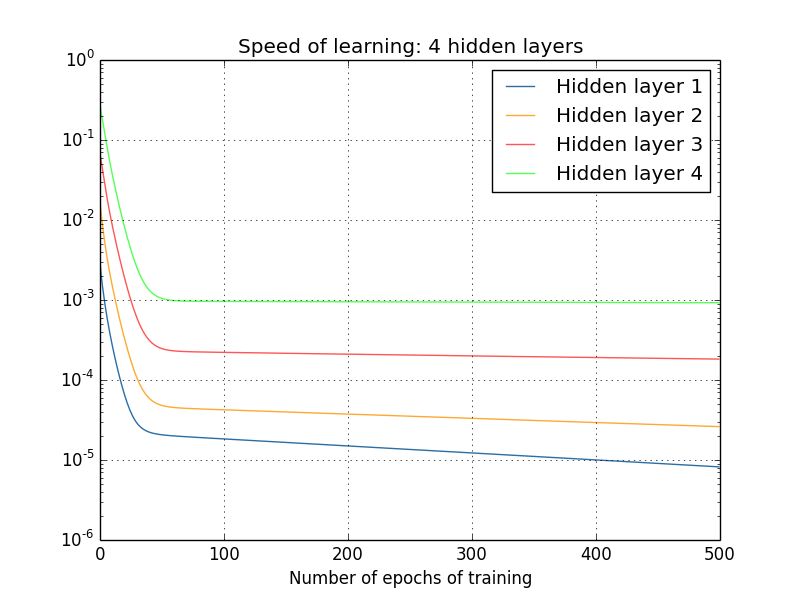
আবারও, শুরুর দিকের hidden layer পরের দিকের hidden layer-এর চেয়ে অনেক ধীরে শেখে। এই ক্ষেত্রে প্রথম hidden layer শেষ hidden layer-এর চেয়ে প্রায় ১০০ গুণ ধীরে শিখছে। তাহলে এই network-গুলো train করতে আমাদের যে আগে সমস্যা হচ্ছিল তাতে অবাক হওয়ার কিছু নেই!
এখানে আমরা একটা গুরুত্বপূর্ণ পর্যবেক্ষণ পেলাম: অন্তত কিছু deep neural network-এ, hidden layer-গুলোর মধ্য দিয়ে পেছনের দিকে যেতে যেতে gradient ছোট হতে থাকে। এর মানে শুরুর দিকের layer-এর neuron পরের দিকের layer-এর neuron-এর চেয়ে অনেক ধীরে শেখে। আর যদিও আমরা এটা কেবল একটা network-এ দেখেছি, অনেক neural network-এ এমন ঘটার পেছনে মৌলিক কারণ আছে। এই ঘটনাটি vanishing gradient problem নামে পরিচিত।
Vanishing gradient সমস্যা কেন ঘটে? এটা এড়ানোর কোনো উপায় আছে কি? আর deep neural network train করার সময় আমরা কীভাবে এর মোকাবিলা করব? আসলে আমরা শীঘ্রই জানব এটা অনিবার্য নয়, যদিও বিকল্পটাও খুব আকর্ষণীয় নয়: কখনো কখনো gradient শুরুর দিকের layer-এ অনেক বড় হয়ে যায়! এটাই exploding gradient problem, আর এটা vanishing gradient সমস্যার চেয়ে খুব একটা ভালো খবর নয়। আরও সাধারণভাবে, দেখা যায় deep neural network-এ gradient অস্থির (unstable), শুরুর দিকের layer-এ এটা হয় explode করে নয়তো vanish করে। এই অস্থিরতা deep neural network-এ gradient-ভিত্তিক learning-এর জন্য একটা মৌলিক সমস্যা। এটা আমাদের বুঝতে হবে, এবং সম্ভব হলে এর মোকাবিলায় পদক্ষেপ নিতে হবে।
Vanishing (বা unstable) gradient-এর একটা সম্ভাব্য প্রতিক্রিয়া হলো ভাবা — এটা কি সত্যিই এতটা সমস্যা? এক মুহূর্তের জন্য neural net থেকে সরে এসে ধরো আমরা একটা single-variable function সংখ্যাগতভাবে minimize করার চেষ্টা করছি। derivative ছোট হলে কি সেটা ভালো খবর নয়? এর মানে কি আমরা ইতিমধ্যেই কোনো extremum-এর কাছে নেই? একই ভাবে, deep network-এর শুরুর layer-এ gradient ছোট হওয়া মানে কি weight ও bias-এ আমাদের খুব একটা সমন্বয় করার দরকার নেই?
অবশ্যই, ব্যাপারটা এমন নয়। মনে রাখো আমরা network-এর weight ও bias random ভাবে initialize করেছিলাম। আমাদের network যা করুক চাই, প্রাথমিক weight ও bias সেই কাজে ভালো হওয়ার সম্ভাবনা অত্যন্ত কম। আরও সুনির্দিষ্ট হতে, MNIST সমস্যার জন্য একটা network-এর প্রথম layer-এর weight-গুলো বিবেচনা করো। Random initialization মানে প্রথম layer input image সম্পর্কে বেশিরভাগ তথ্যই ফেলে দেয়। পরের layer-গুলো ব্যাপকভাবে train করা হলেও তারা input image চিনতে খুবই কষ্ট পাবে, কারণ তাদের কাছে যথেষ্ট তথ্য নেই। তাই প্রথম layer-এ খুব একটা শেখার দরকার নেই — এমন হতেই পারে না। deep network train করতে গেলে আমাদের vanishing gradient সমস্যার মোকাবিলা কীভাবে করতে হয় তা বের করতেই হবে।
Vanishing gradient সমস্যার কারণ কী? Deep neural net-এ unstable gradient
Vanishing gradient সমস্যা কেন ঘটে সে সম্পর্কে অন্তর্দৃষ্টি পেতে চলো সবচেয়ে সরল deep neural network বিবেচনা করি: যার প্রতিটি layer-এ মাত্র একটি করে neuron। এই হলো তিনটি hidden layer-যুক্ত একটা network:

এখানে হলো weight, হলো bias, আর হলো কোনো cost function। কীভাবে এটা কাজ করে তা আবার মনে করিয়ে দিই: -তম neuron থেকে output হলো , যেখানে হলো চিরচেনা sigmoid activation function, আর হলো neuron-এ আসা weighted input। শেষে cost এঁকেছি এটা জোর দিতে যে cost হলো network-এর output -এর একটা function: network-এর প্রকৃত output কাঙ্ক্ষিত output-এর কাছাকাছি হলে cost কম হবে, আর দূরে হলে cost বেশি হবে।
আমরা প্রথম hidden neuron-এর সাথে জড়িত gradient অধ্যয়ন করব। আমরা -এর একটা রাশি বের করব, এবং সেই রাশি অধ্যয়ন করে বুঝব কেন vanishing gradient সমস্যা ঘটে।
আমি শুরু করব -এর রাশিটা শুধু দেখিয়ে দিয়ে। এটা ভীতিকর দেখায়, কিন্তু আসলে এর গঠন সরল, যা একটু পরে বর্ণনা করব। এই হলো সেই রাশি (এখনকার মতো network-টা উপেক্ষা করো, আর খেয়াল করো হলো শুধু function-এর derivative):

রাশিটার গঠন এরকম: network-এর প্রতিটি neuron-এর জন্য গুণফলে একটা পদ আছে; প্রতিটি weight-এর জন্য একটা পদ আছে; আর শেষে cost function-এর সাথে সঙ্গতিপূর্ণ একটা পদ আছে। লক্ষ করো আমি রাশির প্রতিটি পদকে network-এর সংশ্লিষ্ট অংশের ঠিক উপরে বসিয়েছি। অর্থাৎ network নিজেই রাশিটার একটা স্মৃতিসহায়ক (mnemonic)।
তুমি চাইলে এই রাশিটা মেনে নিয়ে সরাসরি এটা vanishing gradient সমস্যার সাথে কীভাবে সম্পর্কিত সেই আলোচনায় চলে যেতে পারো। এতে কোনো ক্ষতি নেই, কারণ এই রাশিটা আমাদের আগের backpropagation আলোচনার একটা বিশেষ ক্ষেত্র মাত্র। তবে রাশিটা কেন সত্য তার একটা সরল ব্যাখ্যাও আছে, আর সেই ব্যাখ্যাটা দেখা মজার (এবং হয়তো আলোকপাতকারী)।
ধরো আমরা bias -এ একটা সামান্য পরিবর্তন করলাম। এটা network-এর বাকি অংশে একগুচ্ছ পরপর (cascading) পরিবর্তন ঘটাবে। প্রথমে এটা প্রথম hidden neuron-এর output-এ একটা পরিবর্তন ঘটায়। সেটা আবার দ্বিতীয় hidden neuron-এ আসা weighted input-এ একটা পরিবর্তন ঘটায়। তারপর দ্বিতীয় hidden neuron-এর output-এ একটা পরিবর্তন । এভাবে চলতে চলতে একদম output-এ cost-এ একটা পরিবর্তন পর্যন্ত পৌঁছে যায়। আমাদের আছে
এটা ইঙ্গিত দেয় যে এই cascade-এর প্রতিটি ধাপের প্রভাব সাবধানে অনুসরণ করে আমরা gradient -এর একটা রাশি বের করতে পারি।
এটা করতে চলো ভাবি কীভাবে প্রথম hidden neuron-এর output -এ পরিবর্তন ঘটায়। আমাদের আছে , তাই
ওই পদটা পরিচিত মনে হওয়ার কথা: এটাই gradient -এর জন্য আমাদের দাবি-করা রাশির প্রথম পদ। স্বজ্ঞাতভাবে, এই পদটা bias-এ একটা পরিবর্তন -কে output activation-এ একটা পরিবর্তন -এ রূপান্তরিত করে। সেই পরিবর্তন আবার দ্বিতীয় hidden neuron-এ আসা weighted input -এ একটা পরিবর্তন ঘটায়:
ও -এর জন্য আমাদের রাশিগুলো একসাথে করলে আমরা দেখি bias -এর পরিবর্তন কীভাবে network বরাবর ছড়িয়ে গিয়ে -কে প্রভাবিত করে:
আবারও, এটা পরিচিত মনে হওয়ার কথা: আমরা এখন gradient -এর দাবি-করা রাশির প্রথম দুটি পদ পেয়ে গেছি।
আমরা এভাবে এগিয়ে যেতে পারি, network-এর বাকি অংশের মধ্য দিয়ে পরিবর্তন কীভাবে ছড়ায় তা অনুসরণ করে। প্রতিটি neuron-এ আমরা একটা পদ পাই, আর প্রতিটি weight-এর মধ্য দিয়ে একটা পদ পাই। শেষ ফলাফল হলো cost-এর চূড়ান্ত পরিবর্তন -কে bias-এর প্রাথমিক পরিবর্তন -এর সাথে সম্পর্কিত করা একটা রাশি:
দিয়ে ভাগ করলে আমরা সত্যিই gradient-এর কাঙ্ক্ষিত রাশিটা পাই:
Vanishing gradient সমস্যা কেন ঘটে: Vanishing gradient সমস্যা কেন ঘটে তা বুঝতে চলো gradient-এর গোটা রাশিটা স্পষ্টভাবে লিখে ফেলি:
একদম শেষ পদটা বাদ দিলে, এই রাশিটা রূপের পদগুলোর একটা গুণফল। এই পদগুলোর প্রতিটি কেমন আচরণ করে তা বুঝতে চলো function-এর একটা plot দেখি:
Derivative-টি সর্বোচ্চে পৌঁছায় -এ। এখন, network-এ weight initialize করতে আমরা যদি আমাদের standard পদ্ধতি ব্যবহার করি, তাহলে আমরা mean ও standard deviation -এর একটা Gaussian দিয়ে weight বেছে নেব। তাই weight-গুলো সাধারণত মেনে চলবে। এই পর্যবেক্ষণগুলো একসাথে রাখলে আমরা দেখি পদগুলো সাধারণত মেনে চলবে। আর যখন আমরা এমন অনেকগুলো পদের গুণফল নিই, তখন গুণফলটা exponentially কমতে থাকে: যত বেশি পদ, গুণফল তত ছোট। এতে vanishing gradient সমস্যার একটা সম্ভাব্য ব্যাখ্যার গন্ধ পাওয়া যাচ্ছে।
এটা আরও স্পষ্ট করতে চলো -এর রাশিকে পরের কোনো bias-এর সাপেক্ষে gradient-এর রাশির সাথে তুলনা করি, ধরো । অবশ্যই আমরা -এর রাশিটা স্পষ্টভাবে বের করিনি, কিন্তু এটাও -এর জন্য বর্ণিত একই প্যাটার্ন অনুসরণ করে। এই হলো দুটি রাশির তুলনা:
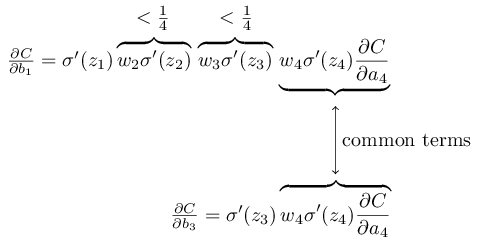
দুটি রাশি অনেকগুলো পদ ভাগাভাগি করে। কিন্তু gradient -এ অতিরিক্ত দুটি পদ আছে, প্রতিটি রূপের। আমরা দেখেছি এমন পদ সাধারণত মাত্রায় -এর চেয়ে কম। তাই gradient সাধারণত -এর চেয়ে গুণ (বা তার বেশি) ছোট হবে। এটাই vanishing gradient সমস্যার মূল উৎস।
অবশ্যই এটা একটা অনানুষ্ঠানিক যুক্তি, vanishing gradient সমস্যা ঘটবেই এমন কঠোর প্রমাণ নয়। বেশ কিছু সম্ভাব্য ফাঁকফোকর আছে। বিশেষ করে আমরা ভাবতে পারি training-এর সময় weight বেড়ে যেতে পারে কিনা। বাড়লে গুণফলের পদগুলো হয়তো আর মেনে চলবে না। আসলে পদগুলো যথেষ্ট বড় হয়ে গেলে — -এর চেয়ে বড় — আমাদের আর vanishing gradient সমস্যা থাকবে না। বরং layer-গুলোর মধ্য দিয়ে পেছনে যেতে যেতে gradient আসলে exponentially বাড়বে। Vanishing gradient সমস্যার বদলে আমাদের একটা exploding gradient সমস্যা হবে।
Exploding gradient সমস্যা: চলো একটা সুনির্দিষ্ট উদাহরণ দেখি যেখানে exploding gradient ঘটে। উদাহরণটা কিছুটা সাজানো: আমি network-এর parameter-গুলো ঠিক এমনভাবে স্থির করব যাতে নিশ্চিতভাবে একটা exploding gradient পাই। কিন্তু সাজানো হলেও উদাহরণটার একটা গুণ আছে — এটা দৃঢ়ভাবে প্রতিষ্ঠা করে যে exploding gradient কেবল একটা তাত্ত্বিক সম্ভাবনা নয়, এটা সত্যিই ঘটতে পারে।
Exploding gradient পেতে দুটি ধাপ আছে। প্রথমত, আমরা network-এর সব weight বড় বেছে নিই, ধরো । দ্বিতীয়ত, আমরা bias এমন বেছে নেব যাতে পদগুলো খুব ছোট না হয়। এটা আসলে বেশ সহজ: আমাদের কেবল bias এমন বেছে নিতে হবে যাতে প্রতিটি neuron-এ আসা weighted input হয় (ফলে )। যেমন আমরা চাই । এটা আমরা ধরে অর্জন করতে পারি। একই ভাবনা ব্যবহার করে অন্য bias-গুলো বেছে নিতে পারি। এটা করলে আমরা দেখি সব পদ সমান । এই পছন্দগুলো দিয়ে আমরা একটা exploding gradient পাই।
Unstable gradient সমস্যা: এখানে মৌলিক সমস্যাটা আসলে vanishing gradient সমস্যা বা exploding gradient সমস্যা ততটা নয়। সমস্যাটা হলো শুরুর দিকের layer-এর gradient হলো পরের সব layer থেকে আসা পদগুলোর গুণফল। যখন অনেক layer থাকে, তখন এটা অন্তর্নিহিতভাবে একটা অস্থির পরিস্থিতি। সব layer প্রায় একই গতিতে শিখতে পারে কেবল তখনই, যখন এই পদগুলোর গুণফল একে অপরকে প্রায় ভারসাম্যে নিয়ে আসে। সেই ভারসাম্য ঘটানোর কোনো ব্যবস্থা বা অন্তর্নিহিত কারণ ছাড়া, কেবল আকস্মিকভাবে এমনটা ঘটার সম্ভাবনা অত্যন্ত কম। সংক্ষেপে, এখানে আসল সমস্যা হলো neural network একটা unstable gradient problem-এ ভোগে। ফলে আমরা যদি standard gradient-ভিত্তিক learning কৌশল ব্যবহার করি, তাহলে network-এর বিভিন্ন layer ভীষণ ভিন্ন ভিন্ন গতিতে শিখবে।
Vanishing gradient সমস্যার প্রাবল্য: আমরা দেখেছি deep network-এর শুরুর দিকের layer-এ gradient vanish করতে পারে বা explode করতে পারে। আসলে sigmoid neuron ব্যবহার করলে gradient সাধারণত vanish-ই করে। কেন তা দেখতে আবার রাশিটা বিবেচনা করো। Vanishing gradient সমস্যা এড়াতে আমাদের দরকার । তুমি হয়তো ভাবছ খুব বড় হলে এটা সহজেই ঘটতে পারে। কিন্তু এটা যতটা সহজ মনে হয় তার চেয়ে কঠিন। কারণ পদটাও -এর উপর নির্ভর করে: , যেখানে হলো input activation। তাই আমরা যখন বড় করি, তখন সাবধান থাকতে হবে যেন আমরা একইসাথে -কে ছোট করে না ফেলি। এটা দেখা যায় বেশ বড় একটা বাধা। কারণ আমরা যখন বড় করি তখন -ও খুব বড় হয়ে যায়। -এর গ্রাফ দেখলে বোঝা যায় এটা আমাদের function-এর "ডানা"-য় (wings) নিয়ে ফেলে, যেখানে এটা খুব ছোট মান নেয়। এটা এড়ানোর একমাত্র উপায় হলো input activation একটা বেশ সংকীর্ণ পরিসরের মানের মধ্যে পড়া (এই গুণগত ব্যাখ্যাটি নিচের প্রথম সমস্যায় পরিমাণগত করা হয়েছে)। কখনো কখনো আকস্মিকভাবে এমনটা ঘটবে। তবে বেশিরভাগ সময় তা ঘটে না। আর তাই সাধারণ ক্ষেত্রে আমাদের vanishing gradient হয়।
আরও জটিল network-এ unstable gradient
আমরা খেলনা (toy) network নিয়ে পড়ছিলাম, যাদের প্রতিটি hidden layer-এ মাত্র একটা করে neuron। আরও জটিল deep network-এর ক্ষেত্রে কী হয়, যাদের প্রতিটি hidden layer-এ অনেক neuron থাকে?
আসলে এমন network-এও প্রায় একই আচরণ ঘটে। backpropagation নিয়ে আগের অধ্যায়ে আমরা দেখেছিলাম -layer-এর একটা network-এর -তম layer-এ gradient দেওয়া হয়:
এখানে একটা diagonal matrix যার entry-গুলো হলো -তম layer-এ আসা weighted input-এর জন্য মান। হলো বিভিন্ন layer-এর weight matrix। আর হলো output activation-এর সাপেক্ষে -এর partial derivative-গুলোর vector।
এটা single-neuron ক্ষেত্রের চেয়ে অনেক বেশি জটিল রাশি। তবু ভালো করে দেখলে মূল রূপটা খুবই অনুরূপ, প্রচুর রূপের জোড়া সহ। তাছাড়া matrix-গুলোর diagonal-এ ছোট ছোট entry আছে, কোনোটিই -এর চেয়ে বড় নয়। weight matrix খুব বড় না হলে, প্রতিটি অতিরিক্ত পদ gradient vector-কে আরও ছোট করার দিকে ঝোঁকায়, যা একটা vanishing gradient-এ নিয়ে যায়। আরও সাধারণভাবে, গুণফলে এত বেশি পদ থাকায় তা একটা unstable gradient-এর দিকে নিয়ে যায়, ঠিক আমাদের আগের উদাহরণের মতো। বাস্তবে, পরীক্ষালব্ধভাবে sigmoid network-এ সাধারণত দেখা যায় শুরুর দিকের layer-এ gradient exponentially দ্রুত vanish করে। ফলে ওই layer-গুলোয় learning ধীর হয়ে যায়। এই slowdown কেবল একটা দুর্ঘটনা বা অসুবিধা নয়: এটা আমরা learning-এর যে পদ্ধতি নিচ্ছি তার একটা মৌলিক পরিণাম।
Deep learning-এর অন্যান্য বাধা
এই অধ্যায়ে আমরা deep learning-এর একটা বাধা হিসেবে vanishing gradient — এবং আরও সাধারণভাবে unstable gradient — এর উপর মনোযোগ দিয়েছি। আসলে unstable gradient deep learning-এর কেবল একটা বাধা, যদিও একটা গুরুত্বপূর্ণ মৌলিক বাধা। চলমান অনেক গবেষণার লক্ষ্য deep network train করার সময় কী কী চ্যালেঞ্জ ঘটতে পারে তা আরও ভালোভাবে বোঝা। আমি এখানে সেই কাজের পূর্ণাঙ্গ সারসংক্ষেপ দেব না, শুধু কয়েকটা গবেষণাপত্রের সংক্ষিপ্ত উল্লেখ করতে চাই, যাতে মানুষ যে ধরনের প্রশ্ন করছে তার একটা স্বাদ পাও।
প্রথম উদাহরণ হিসেবে, ২০১০ সালে Glorot ও Bengio
এমন প্রমাণ পান যা ইঙ্গিত দেয় sigmoid activation function ব্যবহার deep network train করায় সমস্যা ঘটাতে পারে। বিশেষ করে তাঁরা প্রমাণ পান যে sigmoid ব্যবহারে training-এর শুরুর দিকেই শেষ hidden layer-এর activation -এর কাছাকাছি saturate হয়ে যায়, যা learning-কে উল্লেখযোগ্যভাবে ধীর করে দেয়। তাঁরা কিছু বিকল্প activation function-এর প্রস্তাব করেন, যেগুলো এই saturation সমস্যায় ততটা ভোগে না বলে মনে হয়।
দ্বিতীয় উদাহরণ হিসেবে, ২০১৩ সালে Sutskever, Martens, Dahl ও Hinton
deep learning-এ random weight initialization এবং momentum-ভিত্তিক stochastic gradient descent-এর momentum schedule — দুটিরই প্রভাব অধ্যয়ন করেন। দুই ক্ষেত্রেই, ভালো পছন্দ করা deep network train করার সক্ষমতায় উল্লেখযোগ্য পার্থক্য তৈরি করে।
এই উদাহরণগুলো ইঙ্গিত দেয় যে "deep network train করা কী কঠিন করে তোলে?" একটা জটিল প্রশ্ন। এই অধ্যায়ে আমরা deep network-এ gradient-ভিত্তিক learning-এর সাথে জড়িত অস্থিরতার উপর মনোযোগ দিয়েছি। শেষ দুই অনুচ্ছেদের ফলাফল ইঙ্গিত দেয় যে এতে activation function-এর পছন্দ, weight কীভাবে initialize করা হয়, এমনকি gradient descent দিয়ে learning কীভাবে বাস্তবায়িত হয় তার খুঁটিনাটিও ভূমিকা রাখে। আর অবশ্যই network architecture ও অন্যান্য hyper-parameter-এর পছন্দও গুরুত্বপূর্ণ। তাই deep network train করা কঠিন করায় অনেক বিষয় ভূমিকা রাখতে পারে, এবং সেই সব বিষয় বোঝা এখনও চলমান গবেষণার একটা বিষয়। এ সবই বেশ হতাশাজনক ও নৈরাশ্যজনক মনে হয়। তবে সুখবর হলো, পরের অধ্যায়ে আমরা এটা উল্টে দেব, এবং deep learning-এর এমন কয়েকটা পদ্ধতি গড়ে তুলব যা কিছুটা হলেও এই সব চ্যালেঞ্জ কাটিয়ে ওঠে বা পাশ কাটিয়ে যায়।